

Advancing Korean Medical Large Language Models: Automated Pipeline for Korean Medical Preference Dataset Construction
- PMID: 40384068
- PMCID: PMC12086433
- DOI: 10.4258/hir.2025.31.2.166
Advancing Korean Medical Large Language Models: Automated Pipeline for Korean Medical Preference Dataset Construction
Abstract
Objectives: Developing large language models (LLMs) in biomedicine requires access to high-quality training and alignment tuning datasets. However, publicly available Korean medical preference datasets are scarce, hindering the advancement of Korean medical LLMs. This study constructs and evaluates the efficacy of the Korean Medical Preference Dataset (KoMeP), an alignment tuning dataset constructed with an automated pipeline, minimizing the high costs of human annotation.
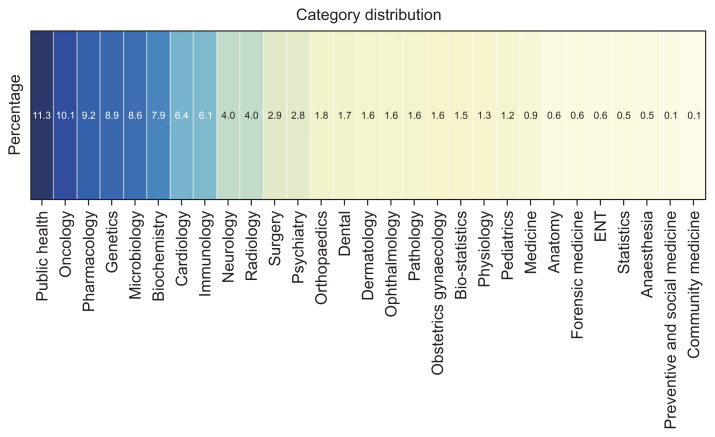
Methods: KoMeP was generated using the DAHL score, an automated hallucination evaluation metric. Five LLMs (Dolly-v2-3B, MPT-7B, GPT-4o, Qwen-2-7B, Llama-3-8B) produced responses to 8,573 biomedical examination questions, from which 5,551 preference pairs were extracted. Each pair consisted of a "chosen" response and a "rejected" response, as determined by their DAHL scores. The dataset was evaluated when trained through two different alignment tuning methods, direct preference optimization (DPO) and odds ratio preference optimization (ORPO) respectively across five different models. The KorMedMCQA benchmark was employed to assess the effectiveness of alignment tuning.
Results: Models trained with DPO consistently improved KorMedMCQA performance; notably, Llama-3.1-8B showed a 43.96% increase. In contrast, ORPO training produced inconsistent results. Additionally, English-to-Korean transfer learning proved effective, particularly for English-centric models like Gemma-2, whereas Korean-to-English transfer learning achieved limited success. Instruction tuning with KoMeP yielded mixed outcomes, which suggests challenges in dataset formatting.
Conclusions: KoMeP is the first publicly available Korean medical preference dataset and significantly improves alignment tuning performance in LLMs. The DPO method outperforms ORPO in alignment tuning. Future work should focus on expanding KoMeP, developing a Korean-native dataset, and refining alignment tuning methods to produce safer and more reliable Korean medical LLMs.
Keywords: Informatics; Large Language Models; Medical Informatics; Natural Language Models; Natural Language Processing.
Conflict of interest statement
Jinwook Choi is an editor of Healthcare Informatics Research; however, he was not involved in this article’s peer reviewer selection, evaluation, and decision process. Otherwise, no potential conflict of interest relevant to this article was reported.
Figures







References
-
- Rafailov R, Sharma A, Mitchell E, Manning CD, Ermon S, Finn C. Direct preference optimization: your language model is secretly a reward model. Adv Neural Inf Process Syst. 2023;36:53728–41.
Grants and funding
LinkOut - more resources
Full Text Sources
