

This is a preprint.
Multimodal Integrated Knowledge Transfer to Large Language Models through Preference Optimization with Biomedical Applications
- PMID: 40386570
- PMCID: PMC12083703
Multimodal Integrated Knowledge Transfer to Large Language Models through Preference Optimization with Biomedical Applications
Abstract
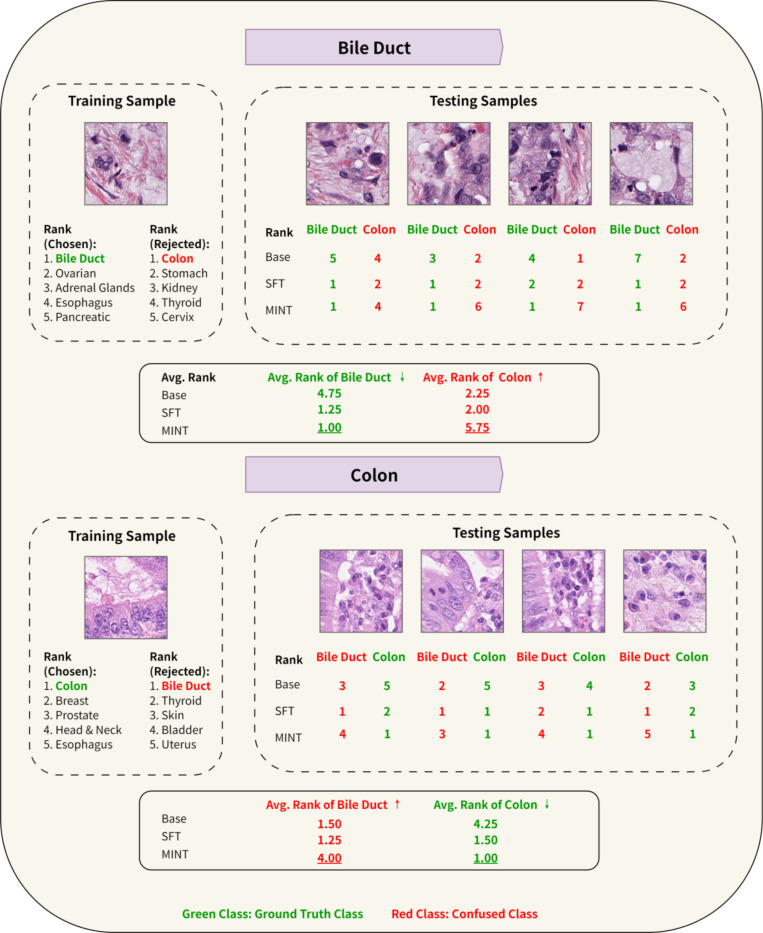
The scarcity of high-quality multimodal biomedical data limits the ability to effectively fine-tune pretrained Large Language Models (LLMs) for specialized biomedical tasks. To address this challenge, we introduce MINT (Multimodal Integrated kNowledge Transfer), a framework that aligns unimodal large decoder models with domain-specific decision patterns from high-quality multimodal biomedical data through preference optimization. While MINT supports different optimization techniques, we primarily implement it with the Odds Ratio Preference Optimization (ORPO) framework as its backbone. This strategy enables the aligned LLMs to perform predictive tasks using text-only or image-only inputs while retaining knowledge learnt from multimodal data. MINT leverages an upstream multimodal machine learning (MML) model trained on high-quality multimodal data to transfer domain-specific insights to downstream text-only or image-only LLMs. We demonstrate MINT's effectiveness through two key applications: (1) Rare genetic disease prediction from texts, where MINT uses a multimodal encoder model, trained on facial photos and clinical notes, to generate a preference dataset for aligning a lightweight decoder-based text-only LLM (Llama 3.2-3B-Instruct). Despite relying on text input only, the MINT-derived model outperforms models trained with Supervised Fine-Tuning (SFT), Retrieval-Augmented Generation (RAG), or direct preference optimization (DPO), and even outperforms much larger foundation model (Llama 3.1-405B-Instruct). (2) Tissue type classification using cell nucleus images, where MINT uses a vision-language foundation model as the preference generator, containing knowledge learnt from both text and histopathological images to align downstream image-only models. The resulting MINT-derived model significantly improves the performance of Llama 3.2-Vision-11B-Instruct on tissue type classification. In summary, MINT provides an effective strategy to align unimodal LLMs with high-quality multimodal expertise through preference optimization. Our study also highlights a hybrid strategy that grafts the strength of encoder models in classification tasks into large decoder models to enhance reasoning, improve predictive tasks and reduce hallucination in biomedical applications.
Keywords: Direct Preference Optimization; Human Phenotype Ontology; Large Language Models; Odds Ratio Preference Optimization; Rare Genetic Disorders; Retrieval Augmented Generation; Supervised Fine-Tuning.
Conflict of interest statement
Competing interests The authors declare no competing interests.
Figures



Similar articles
-
Advancing Korean Medical Large Language Models: Automated Pipeline for Korean Medical Preference Dataset Construction.Healthc Inform Res. 2025 Apr;31(2):166-174. doi: 10.4258/hir.2025.31.2.166. Epub 2025 Apr 30. Healthc Inform Res. 2025. PMID: 40384068 Free PMC article.
-
nach0: multimodal natural and chemical languages foundation model.Chem Sci. 2024 May 8;15(22):8380-8389. doi: 10.1039/d4sc00966e. eCollection 2024 Jun 5. Chem Sci. 2024. PMID: 38846388 Free PMC article.
-
Evaluating large language models for health-related text classification tasks with public social media data.J Am Med Inform Assoc. 2024 Oct 1;31(10):2181-2189. doi: 10.1093/jamia/ocae210. J Am Med Inform Assoc. 2024. PMID: 39121174 Free PMC article.
-
Optimizing large language models in digestive disease: strategies and challenges to improve clinical outcomes.Liver Int. 2024 Sep;44(9):2114-2124. doi: 10.1111/liv.15974. Epub 2024 May 31. Liver Int. 2024. PMID: 38819632 Review.
-
Use of SNOMED CT in Large Language Models: Scoping Review.JMIR Med Inform. 2024 Oct 7;12:e62924. doi: 10.2196/62924. JMIR Med Inform. 2024. PMID: 39374057 Free PMC article.
References
-
- Wolf T, Debut L, Sanh V, et al. Transformers: State-of-the-Art Natural Language Processing. 2019:
-
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in neural information processing systems. 2017;30
-
- McKinzie B, Gan Z, Fauconnier J-P, et al. MM1: methods, analysis and insights from multimodal LLM pre-training. Springer; 2024:304–323.
-
- Tirumala K, Simig D, Aghajanyan A, Morcos A. D4: Improving llm pretraining via document deduplication and diversification. Advances in Neural Information Processing Systems. 2023;36:53983–53995.
-
- Shi W, Ajith A, Xia M, et al. Detecting pretraining data from large language models. arXiv preprint arXiv:231016789. 2023;
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources