

Statistical Methods for Chemical Mixtures: A Roadmap for Practitioners Using Simulation Studies and a Sample Data Analysis in the PROTECT Cohort
- PMID: 40392783
- PMCID: PMC12178341
- DOI: 10.1289/EHP15305
Statistical Methods for Chemical Mixtures: A Roadmap for Practitioners Using Simulation Studies and a Sample Data Analysis in the PROTECT Cohort
Abstract
Background: Quantitative characterization of the health impacts associated with exposure to chemical mixtures has received considerable attention in current environmental and epidemiological studies. With many existing statistical methods and emerging approaches, it is important for practitioners to understand which method is best suited for their inferential goals.
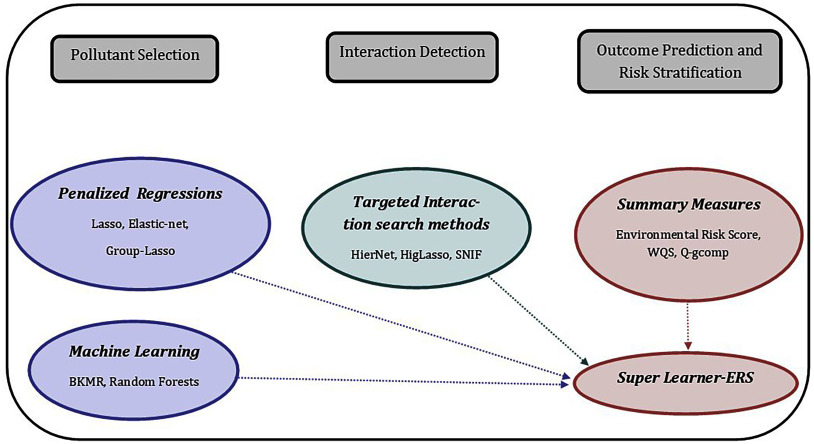
Objective: The goal of this paper is to provide empirical simulation-based evidence regarding performance of mixture methods to help guide researchers on selecting the best available methods to address three scientific questions in mixtures analysis: identifying important components of a mixture, identifying interactions among mixture components, and creating a summary score for risk stratification and prediction.
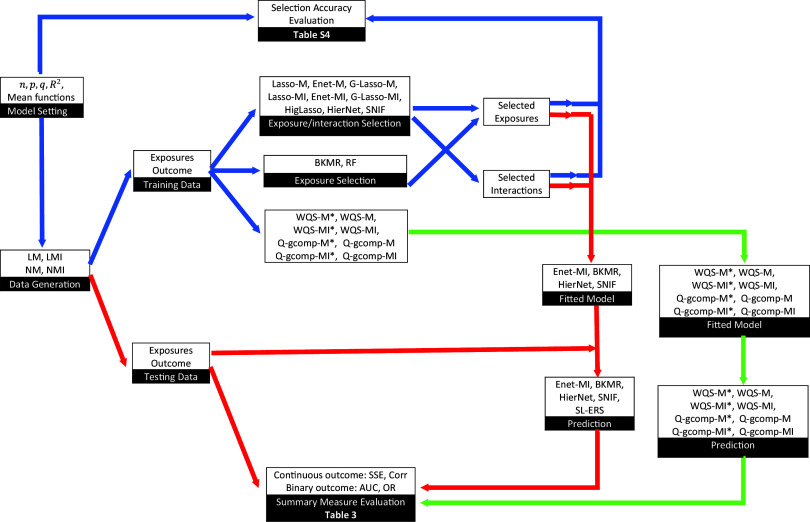
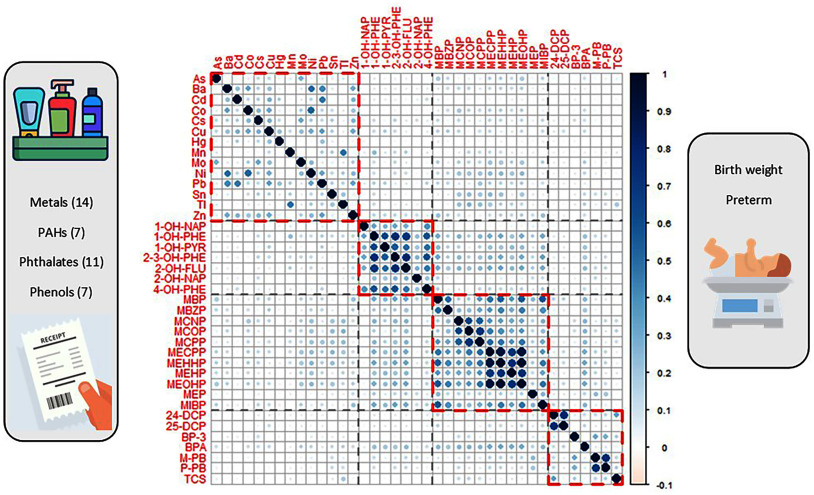
Methods: We conducted a review and comparison of 11 analytical methods available for use in mixtures research through extensive simulation studies for continuous and binary outcomes. In addition, we carried out an illustrative data analysis using the PROTECT birth cohort from Puerto Rico to examine the associations between exposure to chemical mixtures-metals, polycyclic aromatic hydrocarbons (PAHs), phthalates, and phenols-and birth outcomes.
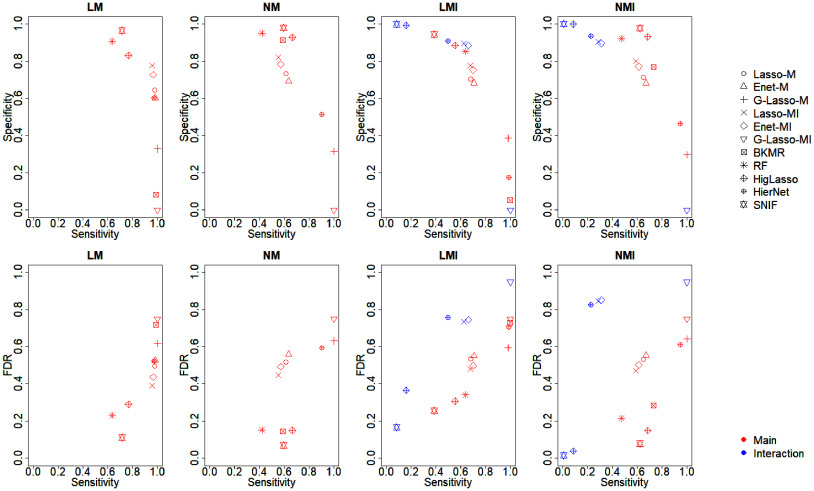
Results: Our simulation results suggest that the choice of methods depends on the goal of analysis and that there is no clear winner across the board. For selection of important toxicants in the mixtures and for identifying interactions, Elastic net (Enet) by Zou et al., Lasso for Hierarchical Interactions (HierNet) by Bien et al., and selection of nonlinear interactions by a forward stepwise algorithm (SNIF) by Narisetty et al. have the most stable performance across simulation settings. For overall summary or a cumulative measure, we find that using the Super Learner to combine multiple environmental risk scores can lead to improved risk stratification and prediction properties.
Conclusions: We develop an integrated R package "CompMix" that provides a platform for mixtures analysis where the practitioners can implement a pipeline that includes several approaches for mixtures analysis. Our study offers guidelines for selecting appropriate statistical methods for addressing specific scientific questions related to mixtures research. We identify critical gaps where new and better methods are needed. https://doi.org/10.1289/EHP15305.
Figures
Update of
-
Statistical methods for chemical mixtures: a roadmap for practitioners.medRxiv [Preprint]. 2024 Mar 4:2024.03.03.24303677. doi: 10.1101/2024.03.03.24303677. medRxiv. 2024. Update in: Environ Health Perspect. 2025 Jun;133(6):67019. doi: 10.1289/EHP15305. PMID: 38496435 Free PMC article. Updated. Preprint.
Similar articles
-
Statistical methods for chemical mixtures: a roadmap for practitioners.medRxiv [Preprint]. 2024 Mar 4:2024.03.03.24303677. doi: 10.1101/2024.03.03.24303677. medRxiv. 2024. Update in: Environ Health Perspect. 2025 Jun;133(6):67019. doi: 10.1289/EHP15305. PMID: 38496435 Free PMC article. Updated. Preprint.
-
Comparison of Two Modern Survival Prediction Tools, SORG-MLA and METSSS, in Patients With Symptomatic Long-bone Metastases Who Underwent Local Treatment With Surgery Followed by Radiotherapy and With Radiotherapy Alone.Clin Orthop Relat Res. 2024 Dec 1;482(12):2193-2208. doi: 10.1097/CORR.0000000000003185. Epub 2024 Jul 23. Clin Orthop Relat Res. 2024. PMID: 39051924
-
[Volume and health outcomes: evidence from systematic reviews and from evaluation of Italian hospital data].Epidemiol Prev. 2013 Mar-Jun;37(2-3 Suppl 2):1-100. Epidemiol Prev. 2013. PMID: 23851286 Italian.
-
Behavioral interventions to reduce risk for sexual transmission of HIV among men who have sex with men.Cochrane Database Syst Rev. 2008 Jul 16;(3):CD001230. doi: 10.1002/14651858.CD001230.pub2. Cochrane Database Syst Rev. 2008. PMID: 18646068
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
Cited by
-
Exposome-wide association study of cognition among older adults in the National Health and Nutrition Examination Survey.medRxiv [Preprint]. 2024 Jul 21:2024.07.19.24310725. doi: 10.1101/2024.07.19.24310725. medRxiv. 2024. Update in: Exposome. 2025 Jan 28;5(1):osaf002. doi: 10.1093/exposome/osaf002. PMID: 39072041 Free PMC article. Updated. Preprint.
References
-
- Taylor KW, Joubert BR, Braun JM, Dilworth C, Gennings C, Hauser R, et al. 2016. Statistical approaches for assessing health effects of environmental chemical mixtures in epidemiology: lessons from an innovative workshop. Environ Health Perspect 124(12):A227–A229, PMID: 27905274, 10.1289/EHP547. - DOI - PMC - PubMed
-
- Joubert BR, Kioumourtzoglou M-A, Chamberlain T, Chen HY, Gennings C, Turyk ME, et al. 2022. Powering Research through Innovative Methods for mixtures in Epidemiology (PRIME) program: novel and expanded statistical methods. Int J Environ Res Public Health 19(3):1378, PMID: 35162394, 10.3390/ijerph19031378. - DOI - PMC - PubMed
-
- Osterman MJK, Hamilton BE, Martin JA, Driscoll AK, Valenzuela CP. 2022. Births: Final Data for 2020. National Center for Health Statistics (US). National Vital Statistics Reports. https://stacks.cdc.gov/view/cdc/112078 [accessed 11 June 2025].
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
