

Benchmarking accelerated next-generation sequencing analysis pipelines
- PMID: 40395501
- PMCID: PMC12092081
- DOI: 10.1093/bioadv/vbaf085
Benchmarking accelerated next-generation sequencing analysis pipelines
Abstract
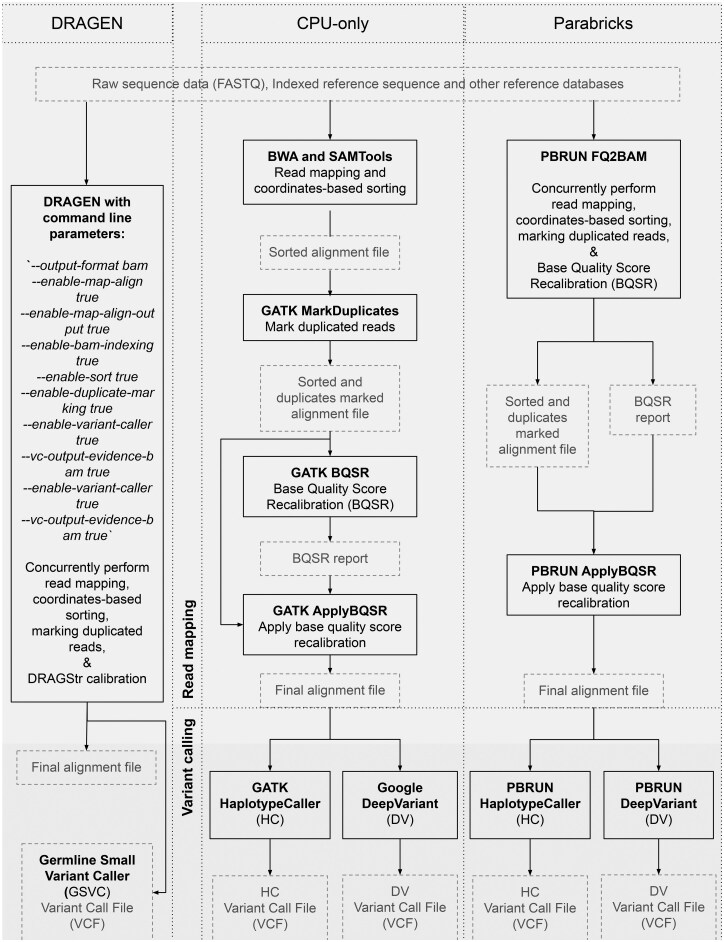
Motivation: Industry-standard central processing unit (CPU)-based next-generation sequencing (NGS) analysis tools have led to longer runtimes, affecting their utility in time-sensitive clinical practices and population-scale research studies. To address this, researchers have developed accelerated NGS platforms like DRAGEN and Parabricks, which have significantly reduced runtimes-from days to hours. However, these studies have evaluated accelerated platforms independently without sufficiently assessing computational resource usage or thoroughly investigating speedup scalability, a gap our study is designed to address.
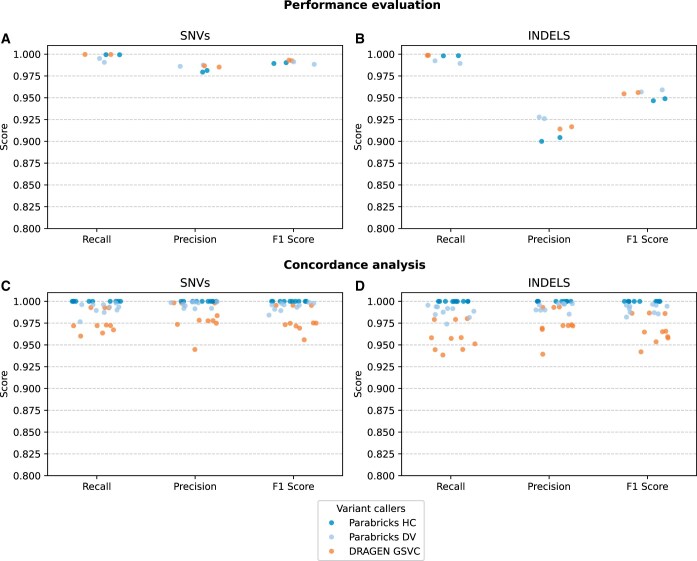
Results: Corroborating previous studies, accelerated pipelines demonstrated shorter runtimes than CPU-only approaches, with Parabricks-H100 demonstrating the highest speedups, followed by DRAGEN. In mapping, DRAGEN outperformed Parabricks (L4 and A100) and matched H100 speedups. Parabricks (A100 and H100) variant calling demonstrated higher speedups than DRAGEN. Moreover, DRAGEN and Parabricks-H100 mapping showed positive trends in the coverage-based scalability analysis, while other configurations failed to scale effectively. Our profiler analysis provided new insights into the relationships between Parabricks' performances and resource usage patterns, revealing its potential for further improvements. Our findings and cost comparison help researchers select accelerated platforms based on coverage needs, timeframes, and budget, while suggesting optimization strategies.
Availability and implementation: Datasets are described in the 'Data availability' section. Our NGS pipelines are available at https://github.com/NAICNO/accelerated_genomics.
© The Author(s) 2025. Published by Oxford University Press.
Conflict of interest statement
All the authors declare no competing interests.
Figures



References
-
- Abadi M, Agarwal A, Barham P et al. TensorFlow: large-scale machine learning on heterogeneous distributed systems. arXiv [cs.DC], 10.48550/arXiv.1603.04467, 16 March 2016, preprint: not peer reviewed. - DOI
-
- Behera S, Catreux S, Rossi M et al. Comprehensive and accurate genome analysis at scale using DRAGEN accelerated algorithms. bioRxiv, 10.1101/2024.01.02.573821, 6 January 2024, preprint: not peer reviewed. - DOI
LinkOut - more resources
Full Text Sources
Miscellaneous
