

DeepCCDS: Interpretable Deep Learning Framework for Predicting Cancer Cell Drug Sensitivity through Characterizing Cancer Driver Signals
- PMID: 40397390
- PMCID: PMC12199323
- DOI: 10.1002/advs.202416958
DeepCCDS: Interpretable Deep Learning Framework for Predicting Cancer Cell Drug Sensitivity through Characterizing Cancer Driver Signals
Abstract
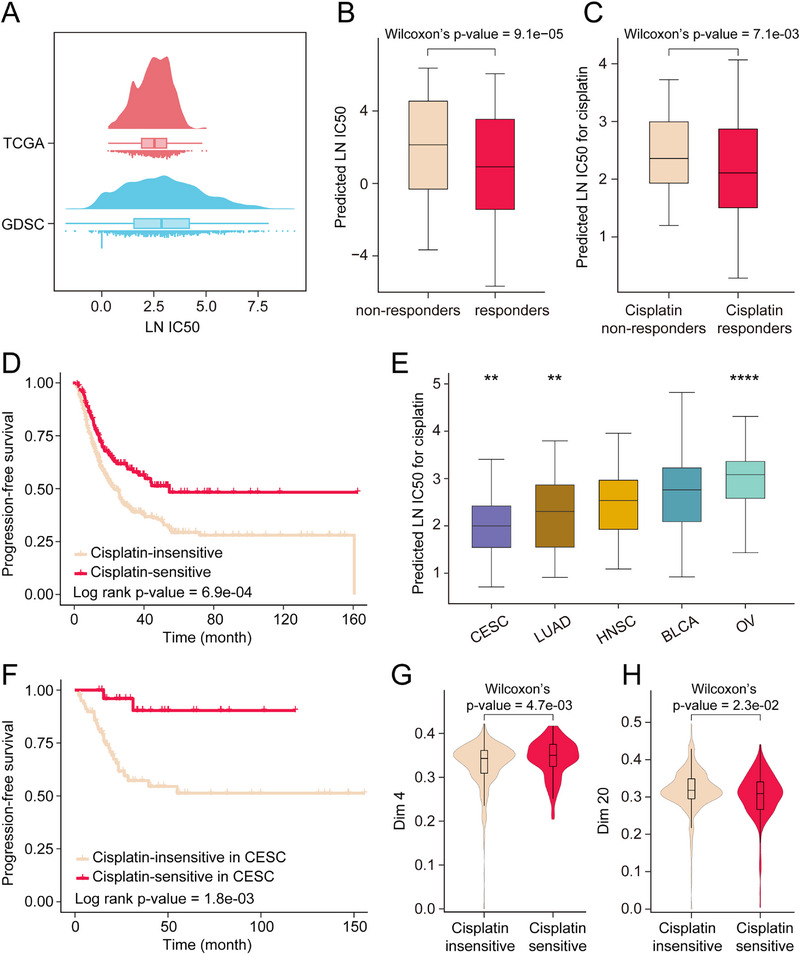
Accurate characterization of cellular states is the foundation for precise prediction of drug sensitivity in cancer cell lines, which in turn is fundamental to realizing precision oncology. However, current deep learning approaches have limitations in characterizing cellular states. They rely solely on isolated genetic markers, overlooking the complex regulatory networks and cellular mechanisms that underlie drug responses. To address this limitation, this work proposes DeepCCDS, a Deep learning framework for Cancer Cell Drug Sensitivity prediction through Characterizing Cancer Driver Signals. DeepCCDS incorporates a prior knowledge network to characterize cancer driver signals, building upon the self-supervised neural network framework. The signals can reflect key mechanisms influencing cancer cell development and drug response, enhancing the model's predictive performance and interpretability. DeepCCDS has demonstrated superior performance in predicting drug sensitivity compared to previous state-of-the-art approaches across multiple datasets. Benefiting from integrating prior knowledge, DeepCCDS exhibits powerful feature representation capabilities and interpretability. Based on these feature representations, we have identified embedding features that could potentially be used for drug screening in new indications. Further, this work demonstrates the applicability of DeepCCDS on solid tumor samples from The Cancer Genome Atlas. This work believes integrating DeepCCDS into clinical decision-making processes can potentially improve the selection of personalized treatment strategies for cancer patients.
Keywords: deep learning; drug sensitivity; feature representation; precision oncology; self‐supervised neural network.
© 2025 The Author(s). Advanced Science published by Wiley‐VCH GmbH.
Conflict of interest statement
The authors declare no conflict of interest.
Figures






References
-
- McGranahan N., Swanton C., Cell 2017, 168, 613. - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical