

Application of AI Chatbot in Responding to Asynchronous Text-Based Messages From Patients With Cancer: Comparative Study
- PMID: 40397947
- PMCID: PMC12138309
- DOI: 10.2196/67462
Application of AI Chatbot in Responding to Asynchronous Text-Based Messages From Patients With Cancer: Comparative Study
Abstract
Background: Telemedicine, which incorporates artificial intelligence such as chatbots, offers significant potential for enhancing health care delivery. However, the efficacy of artificial intelligence chatbots compared to human physicians in clinical settings remains underexplored, particularly in complex scenarios involving patients with cancer and asynchronous text-based interactions.
Objective: This study aimed to evaluate the performance of the GPT-4 (OpenAI) chatbot in responding to asynchronous text-based medical messages from patients with cancer by comparing its responses with those of physicians across two clinical scenarios: patient education and medical decision-making.
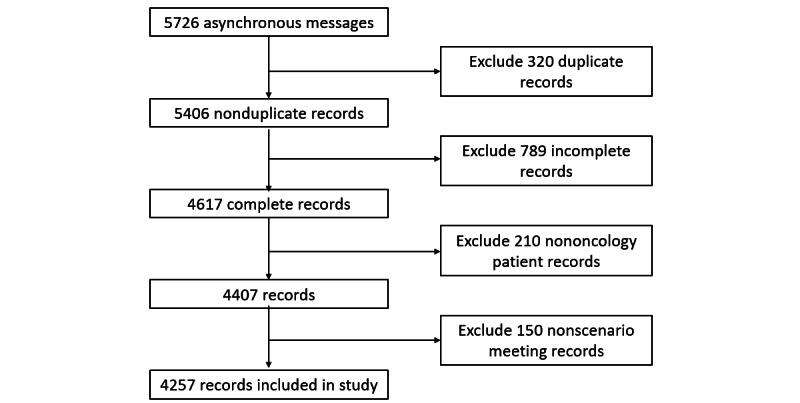
Methods: We collected 4257 deidentified asynchronous text-based medical consultation records from 17 oncologists across China between January 1, 2020, and March 31, 2024. Each record included patient questions, demographic data, and disease-related details. The records were categorized into two scenarios: patient education (eg, symptom explanations and test interpretations) and medical decision-making (eg, treatment planning). The GPT-4 chatbot was used to simulate physician responses to these records, with each session conducted in a new conversation to avoid cross-session interference. The chatbot responses, along with the original physician responses, were evaluated by a medical review panel (3 oncologists) and a patient panel (20 patients with cancer). The medical panel assessed completeness, accuracy, and safety using a 3-level scale, whereas the patient panel rated completeness, trustworthiness, and empathy on a 5-point ordinal scale. Statistical analyses included chi-square tests for categorical variables and Wilcoxon signed-rank tests for ordinal ratings.
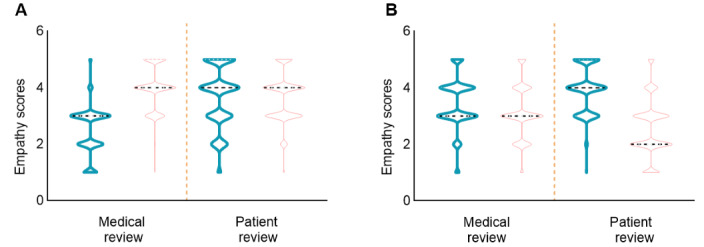
Results: In the patient education scenario (n=2364), the chatbot scored higher than physicians in completeness (n=2301, 97.34% vs n=2213, 93.61% for fully complete responses; P=.002), with no significant differences in accuracy or safety (P>.05). In the medical decision-making scenario (n=1893), the chatbot exhibited lower accuracy (n=1834, 96.88% vs n=1855, 97.99% for fully accurate responses; P<.001) and trustworthiness (n=860, 50.71% vs n=1766, 93.29% rated as "Moderately trustworthy" or higher; P<.001) compared with physicians. Regarding empathy, the medical review panel rated the chatbot as demonstrating higher empathy scores across both scenarios, whereas the patient review panel reached the opposite conclusion, consistently favoring physicians in empathetic communication. Errors in chatbot responses were primarily due to misinterpretations of medical terminology or the lack of updated guidelines, with 3.12% (59/1893) of its responses potentially leading to adverse outcomes, compared with 2.01% (38/1893) for physicians.
Conclusions: The GPT-4 chatbot performs comparably to physicians in patient education by providing comprehensive and empathetic responses. However, its reliability in medical decision-making remains limited, particularly in complex scenarios requiring nuanced clinical judgment. These findings underscore the chatbot's potential as a supplementary tool in telemedicine while highlighting the need for physician oversight to ensure patient safety and accuracy.
Keywords: artificial intelligence, chatbot, telemedicine; comparative study; oncology.
©Xuexue Bai, Shiyong Wang, Yuanli Zhao, Ming Feng, Wenbin Ma, Xiaomin Liu. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 21.05.2025.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Bashshur RL, Armstrong PA. Telemedicine: a new mode for the delivery of health care. Inquiry. 1976;13(3):233–244. - PubMed
-
- Nguyen HTT, Tran HB, Tran PM, Pham HM, Dao CX, Le TN, Do LD, Nguyen HQ, Vu TT, Kirkpatrick J, Reid C, Nguyen DV. Effect of a telemedicine model on patients with heart failure with reduced ejection fraction in a resource-limited setting in vietnam: Cohort study. J Med Internet Res. 2025;27:e67228. doi: 10.2196/67228. https://www.jmir.org/2025//e67228/ v27i1e67228 - DOI - PMC - PubMed
-
- Kong M, Wang Y, Li M, Yao Z. Mechanism assessment of physician discourse strategies and patient consultation behaviors on online health platforms: mixed methods study. J Med Internet Res. 2025;27:e54516. doi: 10.2196/54516. https://www.jmir.org/2025//e54516/ v27i1e54516 - DOI - PMC - PubMed
-
- Chu C, Cram P, Pang A, Stamenova V, Tadrous M, Bhatia RS. Rural telemedicine use before and during the COVID-19 pandemic: repeated cross-sectional study. J Med Internet Res. 2021;23(4):e26960. doi: 10.2196/26960. https://www.jmir.org/2021/4/e26960/ v23i4e26960 - DOI - PMC - PubMed
-
- Snoswell CL, Taylor ML, Comans TA, Smith AC, Gray LC, Caffery LJ. Determining if telehealth can reduce health system costs: scoping review. J Med Internet Res. 2020;22(10):e17298. doi: 10.2196/17298. https://www.jmir.org/2020/10/e17298/ v22i10e17298 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
