

Evaluating performance of large language models for atrial fibrillation management using different prompting strategies and languages
- PMID: 40447746
- PMCID: PMC12125184
- DOI: 10.1038/s41598-025-04309-5
Evaluating performance of large language models for atrial fibrillation management using different prompting strategies and languages
Abstract
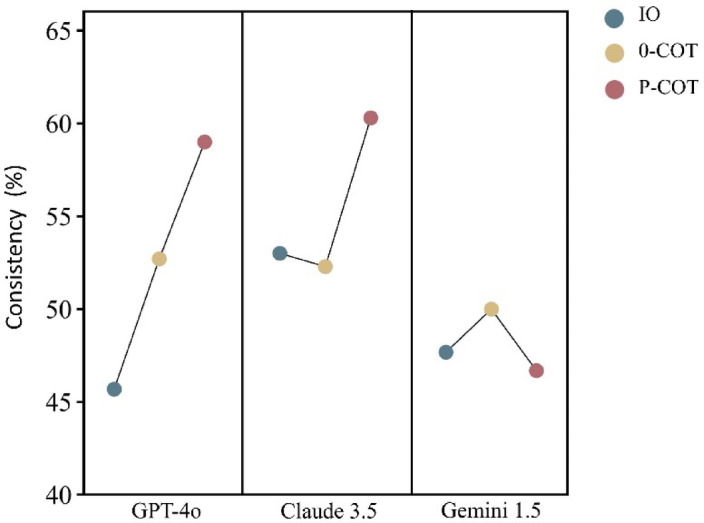
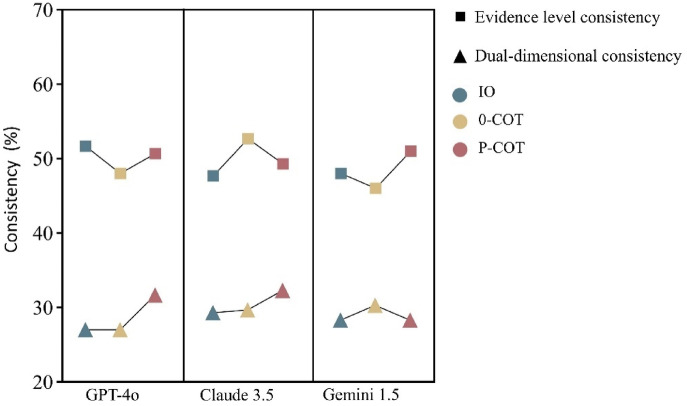
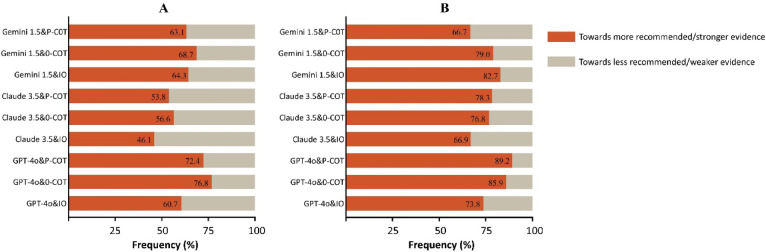
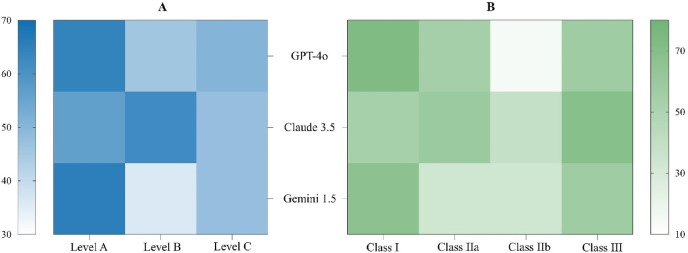
This study evaluated large language models (LLMs) using 30 questions, each derived from a recommendation in the 2024 European Society of Cardiology (ESC) guidelines for atrial fibrillation (AF) management. These recommendations were stratified by class of recommendation and level of evidence. The primary objective was to assess the reliability and consistency of LLM-generated classifications compared to those in the ESC guidelines. Additionally, the study assessed the impact of different prompting strategies and working languages on LLM performance. Three prompting strategies were tested: Input-output (IO), 0-shot-Chain of thought (0-COT) and Performed-Chain of thought (P-COT) prompting. Each question, presented in both English and Chinese, was input into three LLMs: ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro. The reliability of the different LLM-prompt combinations showed moderate to substantial agreement (Fleiss kappa ranged from 0.449 to 0.763). Claude 3.5 with P-COT prompting had the highest recommendation classification consistency (60.3%). No significant differences were observed between English and Chinese across most LLM-prompt combinations. Bias analysis of inconsistent outcomes revealed a propensity towards more recommended treatments and stronger evidence levels across most LLM-prompt combinations. The characteristics of clinical questions potentially influence LLM performance. This study highlights the limitations in the accuracy of LLM responses to AF-related questions. To gather more comprehensive insights, conducting repeated queries is advisable. Future efforts should focus on expanding the use of diverse prompting strategies, conducting ongoing model evaluation and refinement, and establishing a comprehensive, objective benchmarking system.
Keywords: Artificial intelligence; Atrial fibrillation; ChatGPT; Large language models; Prompt engineering.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures
References
-
- Sufi, F. Generative pre-trained transformer (GPT) in research: A systematic review on data augmentation. 15 99 (2024).
MeSH terms
Grants and funding
- 2023HXFH002/1.3.5 Project for Disciplines of Excellence-Clinical Research Incubation Project, West China Hospital of Sichuan University
- 2023HXFH002/1.3.5 Project for Disciplines of Excellence-Clinical Research Incubation Project, West China Hospital of Sichuan University
- 2023HXFH002/1.3.5 Project for Disciplines of Excellence-Clinical Research Incubation Project, West China Hospital of Sichuan University
- 2023HXFH002/1.3.5 Project for Disciplines of Excellence-Clinical Research Incubation Project, West China Hospital of Sichuan University
- 2023HXFH002/1.3.5 Project for Disciplines of Excellence-Clinical Research Incubation Project, West China Hospital of Sichuan University
- 2023HXFH002/1.3.5 Project for Disciplines of Excellence-Clinical Research Incubation Project, West China Hospital of Sichuan University
- 2024YFFK0046/Sichuan Science and Technology Program
- 2024YFFK0046/Sichuan Science and Technology Program
- 2024YFFK0046/Sichuan Science and Technology Program
- 2024YFFK0046/Sichuan Science and Technology Program
- 2024YFFK0046/Sichuan Science and Technology Program
- 2024YFFK0046/Sichuan Science and Technology Program
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
