

Rational Design of Safer Inorganic Nanoparticles via Mechanistic Modeling-Informed Machine Learning
- PMID: 40460056
- PMCID: PMC12177941
- DOI: 10.1021/acsnano.5c03590
Rational Design of Safer Inorganic Nanoparticles via Mechanistic Modeling-Informed Machine Learning
Abstract
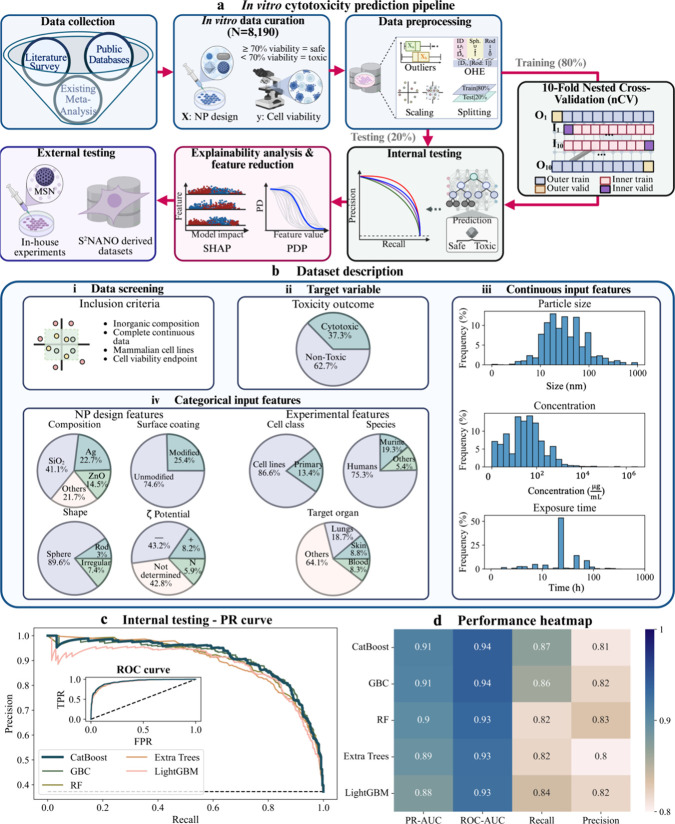
The safety of inorganic nanoparticles (NPs) remains a critical challenge for their clinical translation. To address this, we developed a machine learning (ML) framework that predicts NP toxicity both in vitro and in vivo, leveraging physicochemical properties and experimental conditions. A curated in vitro cytotoxicity dataset was used to train and validate binary classification models, with top-performing models undergoing explainability analysis to identify key determinants of toxicity and establish structure-toxicity relationships. External testing with diverse inorganic NPs validated the predictive accuracy of the framework for in vitro settings. To enable organ-specific toxicity predictions in vivo, we integrated a physiologically based pharmacokinetic (PBPK) model into the ML pipeline to quantify NP exposure across organs. Retraining the ML models with PBPK-derived exposure metrics yielded robust predictions of organ-specific nanotoxicity, further validating the framework. This PBPK-informed ML approach can thus serve as a potential alternative approach to streamline NP safety assessment, enabling the rational design of safer NPs and expediting their clinical translation.
Keywords: PBPK; artificial intelligence; cytotoxicity; machine learning; mathematical modeling; nanoparticle; nanotoxicity.
Figures




Update of
-
Rational Design of Safer Inorganic Nanoparticles via Mechanistic Modeling-informed Machine Learning.Res Sq [Preprint]. 2025 Feb 18:rs.3.rs-5960303. doi: 10.21203/rs.3.rs-5960303/v1. Res Sq. 2025. Update in: ACS Nano. 2025 Jun 17;19(23):21538-21555. doi: 10.1021/acsnano.5c03590. PMID: 40034433 Free PMC article. Updated. Preprint.
Similar articles
-
Rational Design of Safer Inorganic Nanoparticles via Mechanistic Modeling-informed Machine Learning.Res Sq [Preprint]. 2025 Feb 18:rs.3.rs-5960303. doi: 10.21203/rs.3.rs-5960303/v1. Res Sq. 2025. Update in: ACS Nano. 2025 Jun 17;19(23):21538-21555. doi: 10.1021/acsnano.5c03590. PMID: 40034433 Free PMC article. Updated. Preprint.
-
Idiographic Lapse Prediction With State Space Modeling: Algorithm Development and Validation Study.JMIR Form Res. 2025 Jun 3;9:e73265. doi: 10.2196/73265. JMIR Form Res. 2025. PMID: 40460422 Free PMC article.
-
What makes a 'good' decision with artificial intelligence? A grounded theory study in paediatric care.BMJ Evid Based Med. 2025 May 20;30(3):183-193. doi: 10.1136/bmjebm-2024-112919. BMJ Evid Based Med. 2025. PMID: 39939160 Free PMC article.
-
A Systematic Review and Bibliometric Analysis of Applications of Artificial Intelligence and Machine Learning in Vascular Surgery.Ann Vasc Surg. 2022 Sep;85:395-405. doi: 10.1016/j.avsg.2022.03.019. Epub 2022 Mar 24. Ann Vasc Surg. 2022. PMID: 35339595
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
References
-
- da Cruz Schneid A., Albuquerque L. J. C., Mondo G. B., Ceolin M., Picco A. S., Cardoso M. B.. Colloidal stability and degradability of silica nanoparticles in biological fluids: a review. J. Sol-Gel Sci. Technol. 2022;102(1):41–62. doi: 10.1007/s10971-021-05695-8. - DOI
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
