

Geospatial analysis of toponyms in geotagged social media posts
- PMID: 40471903
- PMCID: PMC12140283
- DOI: 10.1371/journal.pone.0325022
Geospatial analysis of toponyms in geotagged social media posts
Abstract
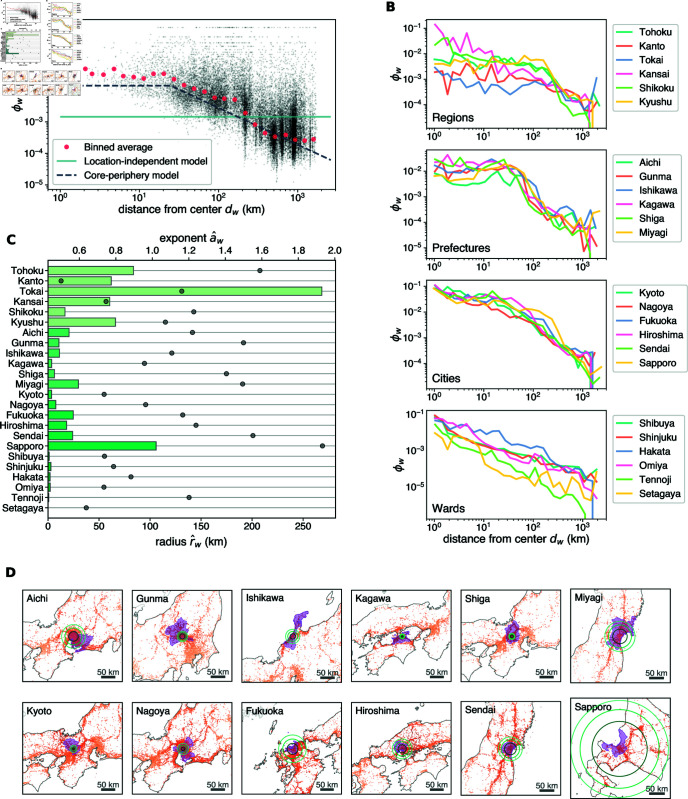
Place names, or toponyms, play an integral role in human representation and communication of geographic space. In particular, how people relate each toponym with particular locations in geographic space should be indicative of their spatial perception. Here, we make use of an extensive dataset of georeferenced social media posts, retrieved from Twitter, to perform a statistical analysis of the geographic distribution of toponyms and uncover the relationship between toponyms and geographic space. We show that the occurrence of toponyms is characterized by spatial inhomogeneity, giving rise to patterns that are distinct from the distribution of common nouns. Using simple models, we quantify the spatial specificity of toponym distributions and identify their core-periphery structures. In particular, we find that toponyms are used with a probability that decays as a power law with distance from the geographic center of their occurrence. Our findings highlight the potential of social media data to explore linguistic patterns in geographic space, paving the way for comprehensive analyses of human spatial representations.
Copyright: © 2025 Hiraoka et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures







Similar articles
-
Spatial-temporal characteristics and causes of changes to the county-level administrative toponyms cultural landscape in the eastern plains of China.PLoS One. 2019 May 28;14(5):e0217381. doi: 10.1371/journal.pone.0217381. eCollection 2019. PLoS One. 2019. PMID: 31136593 Free PMC article.
-
Spatial-Temporal Characteristic Analysis of Ethnic Toponyms Based on Spatial Information Entropy at the Rural Level in Northeast China.Entropy (Basel). 2020 Mar 30;22(4):393. doi: 10.3390/e22040393. Entropy (Basel). 2020. PMID: 33286167 Free PMC article.
-
Do Global Cities Enable Global Views? Using Twitter to Quantify the Level of Geographical Awareness of U.S. Cities.PLoS One. 2015 Jul 13;10(7):e0132464. doi: 10.1371/journal.pone.0132464. eCollection 2015. PLoS One. 2015. PMID: 26167942 Free PMC article.
-
Uses and Limitations of Social Media to Inform Visitor Use Management in Parks and Protected Areas: A Systematic Review.Environ Manage. 2021 Jan;67(1):120-132. doi: 10.1007/s00267-020-01373-7. Epub 2020 Oct 15. Environ Manage. 2021. PMID: 33063153
-
Characteristics of Gun Advertisements on Social Media: Systematic Search and Content Analysis of Twitter and YouTube Posts.J Med Internet Res. 2020 Mar 27;22(3):e15736. doi: 10.2196/15736. J Med Internet Res. 2020. PMID: 32217496 Free PMC article.
References
-
- Montello DR, Goodchild MF, Gottsegen J, Fohl P. Where’s downtown?: Behavioral methods for determining referents of vague spatial queries. Spatial Cognit Comput. 2003;3(2–3):185–204. doi: 10.1080/13875868.2003.9683761 - DOI
-
- Jones CB, Purves RS, Clough PD, Joho H. Modelling vague places with knowledge from the Web. Int J Geograph Inf Sci. 2008;22(10):1045–65. doi: 10.1080/13658810701850547 - DOI
-
- DeLozier G, Baldridge J, London L. Gazetteer-independent toponym resolution using geographic word profiles. AAAI. 2015;29(1):2382–8. doi: 10.1609/aaai.v29i1.9531 - DOI
-
- Cheng Z, Caverlee J, Lee K. You are where you tweet. In: Proceedings of the 19th ACM International Conference on Information and Knowledge Management. ACM. 2010. doi: 10.1145/1871437.1871535 - DOI
-
- Li W, Serdyukov P, de Vries AP, Eickhoff C, Larson M. The where in the tweet. In: Proceedings of the 20th ACM International Conference on Information and Knowledge Management. ACM. 2011. doi: 10.1145/2063576.2063995 - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
