

A microRNA-based dynamic risk score for type 1 diabetes
- PMID: 40473952
- PMCID: PMC12353805
- DOI: 10.1038/s41591-025-03730-7
A microRNA-based dynamic risk score for type 1 diabetes
Abstract
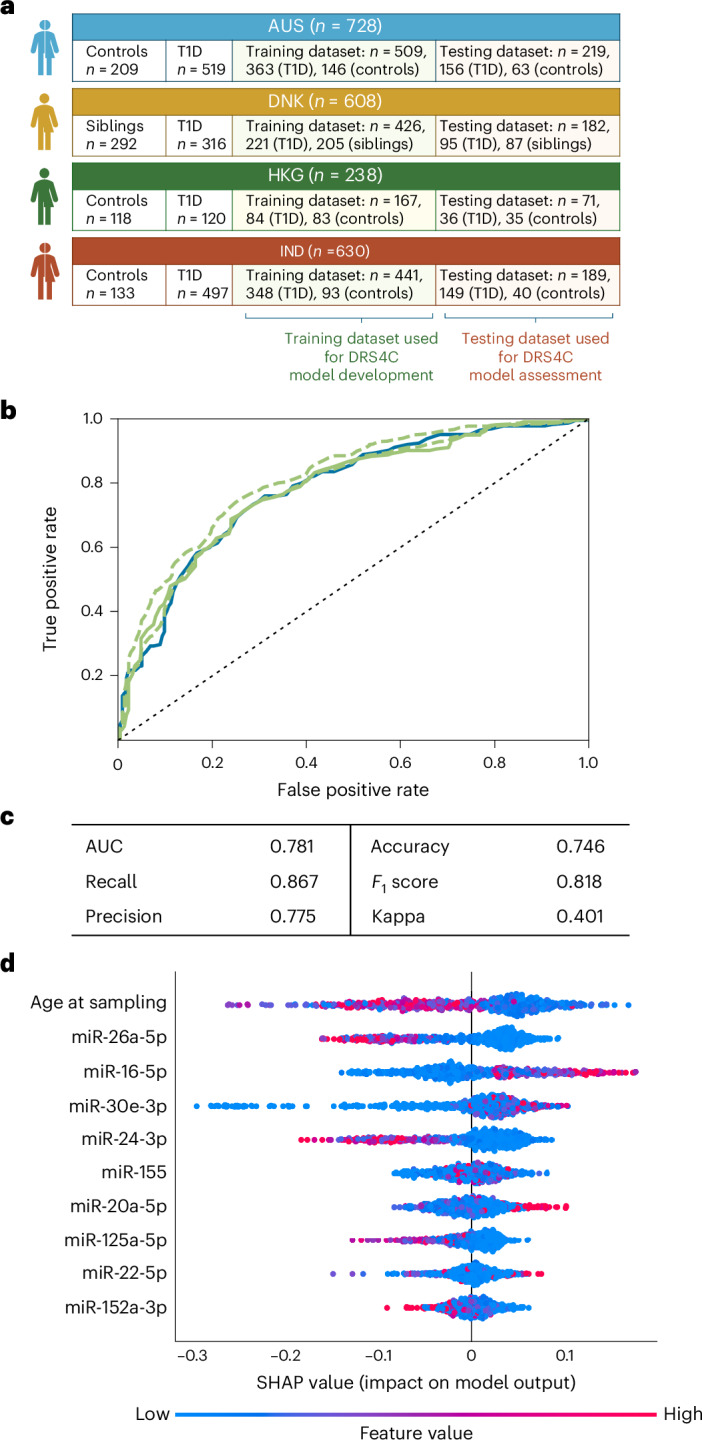
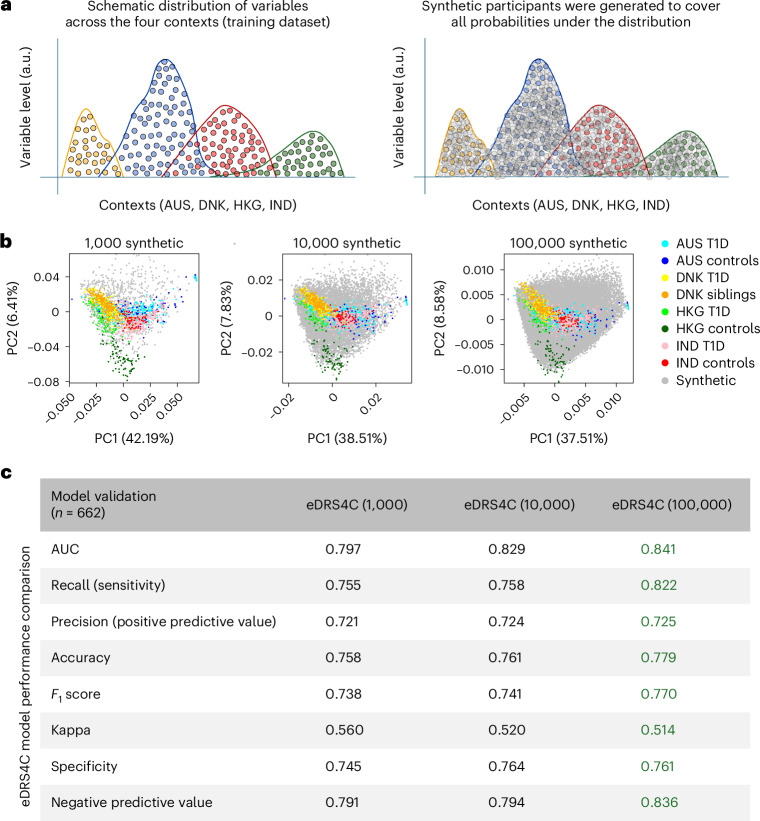
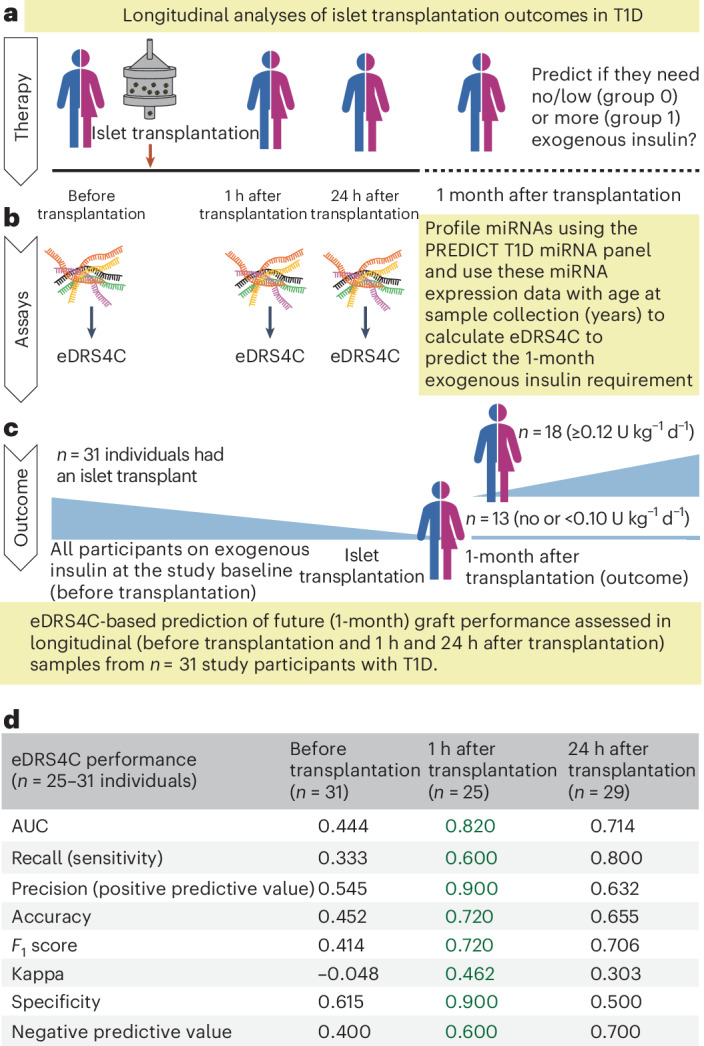
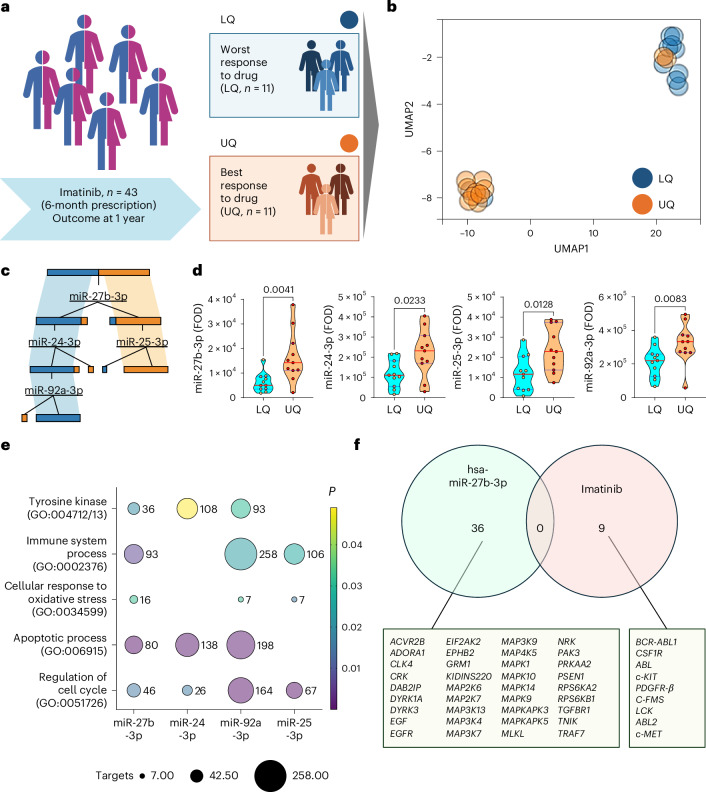
Identifying individuals at high risk of type 1 diabetes (T1D) is crucial as disease-delaying medications are available. Here we report a microRNA (miRNA)-based dynamic (responsive to the environment) risk score developed using multicenter, multiethnic and multicountry ('multicontext') cohorts for T1D risk stratification. Discovery (wet and dry lab) analysis identified 50 miRNAs associated with functional β cell loss, which is a hallmark of T1D. These miRNAs measured across n = 2,204 individuals from four contexts (4C: Australia, Denmark, Hong Kong SAR People's Republic of China, India) led to a four-context, miRNA-based dynamic risk score (DRS) that effectively stratified individuals with and without T1D. Generative artificial intelligence was used to create an enhanced four-context, miRNA-based DRS, which offered good predictive power (area under the curve = 0.84) for T1D stratification in a separate multicontext validation dataset (n = 662), and accurately predicted future exogenous insulin requirement at 1 hour of islet transplantation. In a clinical trial assessing the imatinib drug therapy, baseline miRNA signature, rather than clinical characteristics, distinguished drug responders from nonresponders at 1 year. This study harnessed machine learning/generative artificial intelligence approaches, identifying and validating a miRNA-based DRS for T1D discrimination and treatment efficacy prediction.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: S.E.G. has served on advisory boards for Abata, Genentech, GentiBio, Provention Bio, SAB Biotherapeutics, Sanofi and Shoreline Biosciences. He has received support from Provention Bio, Sanofi and the National Institutes of Health for his roles in conducting clinical trials. He serves on data and safety monitoring boards for Diamyd Medical, Breakthrough T1D and INNODIA. F.P. has received advisory and lecture fees from Sanofi Aventis. A.A.H. has served on the advisory boards of Abbott and Mylan, and has received grants through Breakthrough T1D and the Novo Nordisk Foundation to identify the biomarkers and regulators of diabetes progression. He has been funded through The Leona M. and Harry B. Helmsley Charitable Trust to develop a nanotechnology-based method for miRNA detection. The other authors declare no competing interests.
Figures










References
-
- Mathis, D., Vence, L. & Benoist, C. β-Cell death during progression to diabetes. Nature414, 792–798 (2001). - PubMed
-
- Borchers, A. T., Uibo, R. & Gershwin, M. E. The geoepidemiology of type 1 diabetes. Autoimmun. Rev.9, A355–A365 (2010). - PubMed
-
- Atkinson, M. A. & Gianani, R. The pancreas in human type 1 diabetes: providing new answers to age-old questions. Curr. Opin. Endocrinol. Diabetes Obes.16, 279–285 (2009). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
- 4-CDA-2016-228-M-B, 1-CDA-2021-1084-M-B/Juvenile Diabetes Research Foundation Australia (JDRF Australia)
- 2021/GNT2011557/Department of Health | National Health and Medical Research Council (NHMRC)
- 3-SRA-2019-694-M-B and 1-SRA2021-1067-MB/Leona M. and Harry B. Helmsley Charitable Trust (Helmsley Charitable Trust)
- 3-APF-2016-178-A-N and 1-FAC-2021-1063-A-N/JDRF/United States
- 3-PDF-2023-1324-A-N/JDRF/United States
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
