

Sources of information waste in neuroimaging: mishandling structures, thinking dichotomously, and over-reducing data
- PMID: 40476042
- PMCID: PMC12140072
- DOI: 10.52294/apertureneuro.2022.2.zrji8542
Sources of information waste in neuroimaging: mishandling structures, thinking dichotomously, and over-reducing data
Abstract
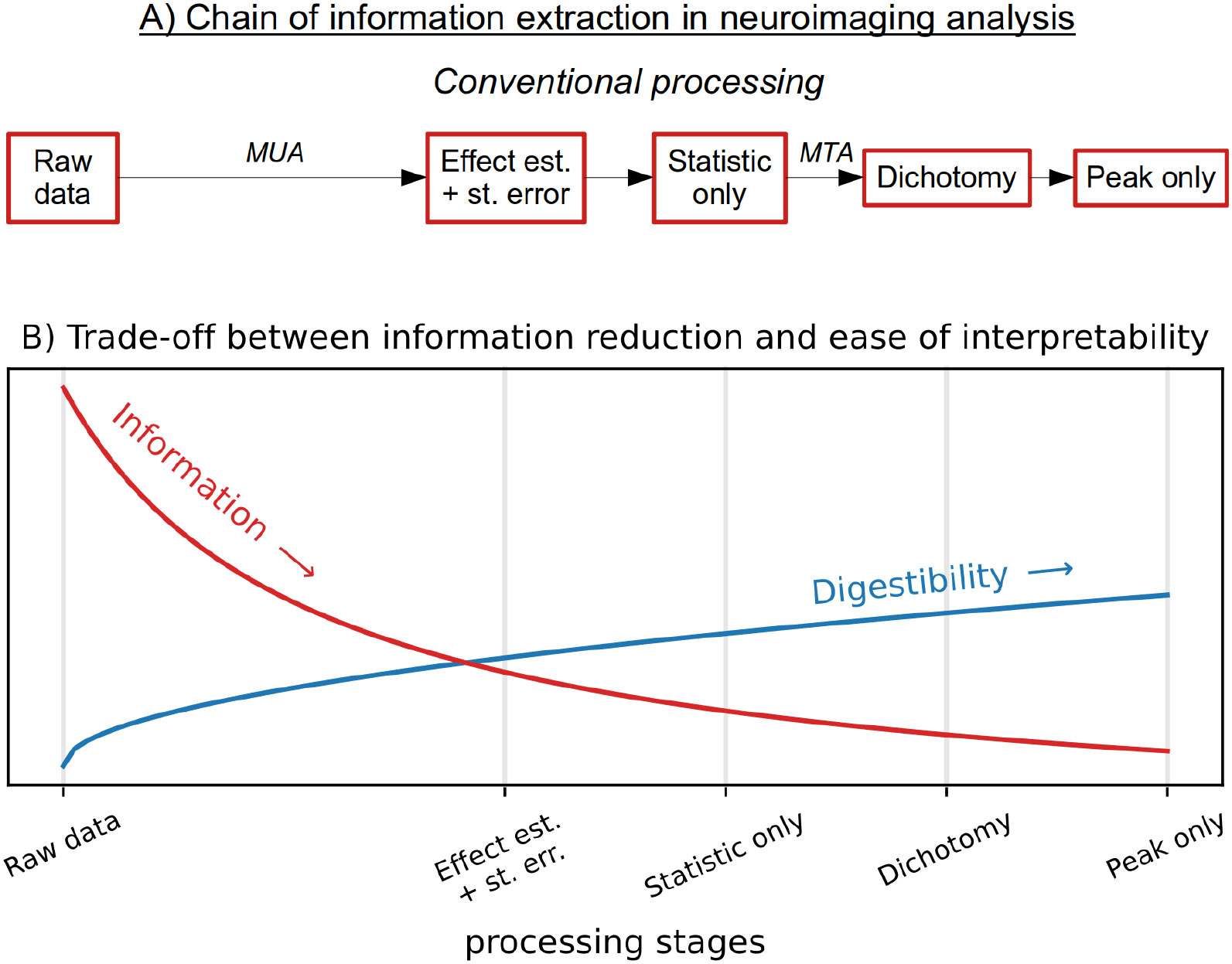
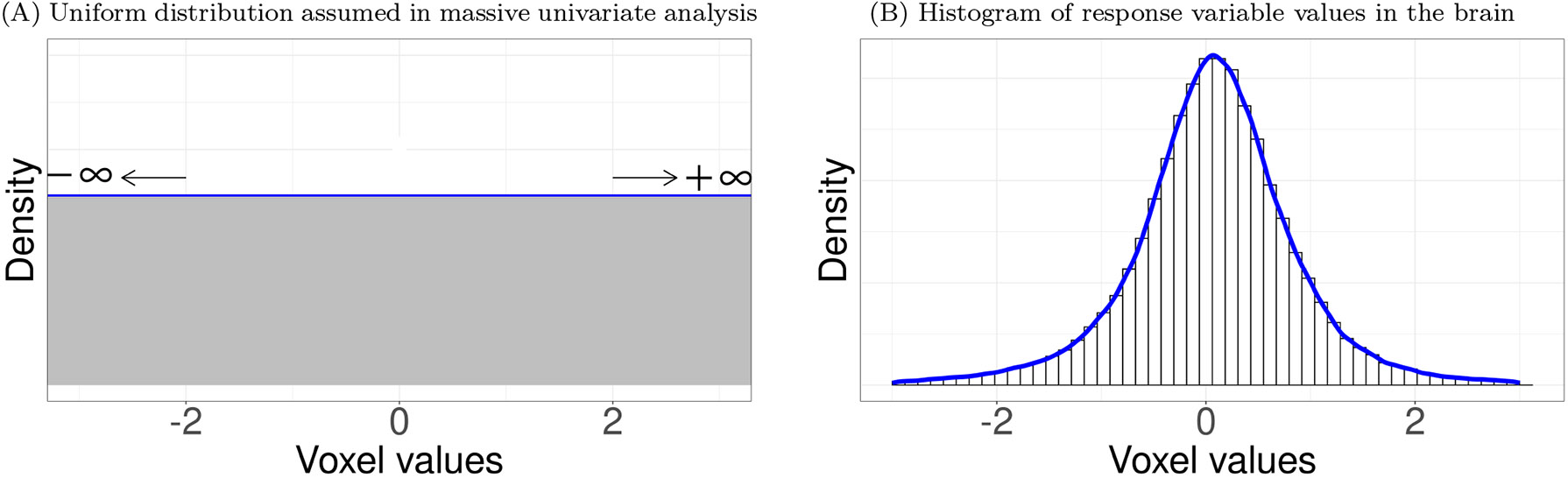
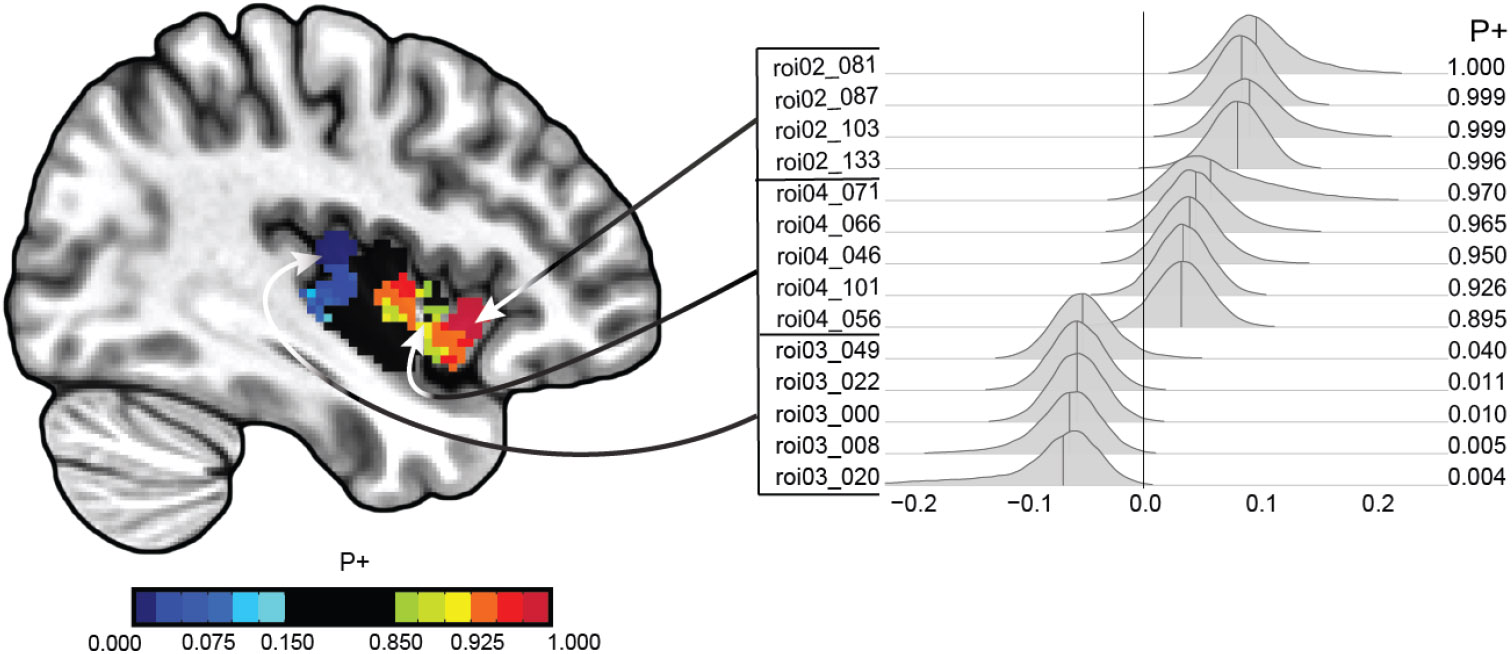
Neuroimaging relies on separate statistical inferences at tens of thousands of spatial locations. Such massively univariate analysis typically requires an adjustment for multiple testing in an attempt to maintain the family-wise error rate at a nominal level of 5%. First, we examine three sources of substantial information loss that are associated with the common practice under the massively univariate framework: (a) the hierarchical data structures (spatial units and trials) are not well maintained in the modeling process; (b) the adjustment for multiple testing leads to an artificial step of strict thresholding; (c) information is excessively reduced during both modeling and result reporting. These sources of information loss have far-reaching impacts on result interpretability as well as reproducibility in neuroimaging. Second, to improve inference efficiency, predictive accuracy, and generalizability, we propose a Bayesian multilevel modeling framework that closely characterizes the data hierarchies across spatial units and experimental trials. Rather than analyzing the data in a way that first creates multiplicity and then resorts to a post hoc solution to address them, we suggest directly incorporating the cross-space information into one single model under the Bayesian framework (so there is no multiplicity issue). Third, regardless of the modeling framework one adopts, we make four actionable suggestions to alleviate information waste and to improve reproducibility: 1) model data hierarchies, 2) quantify effects, 3) abandon strict dichotomization, and 4) report full results. We provide examples for all of these points using both demo and real studies, including the recent Neuroimaging Analysis Replication and Prediction Study (NARPS).
Keywords: Bayesian multilevel modeling; data hierarchy; dichotomization; effect magnitude; information waste; multiple testing problem; result reporting.
Figures







References
-
- Zhang L, Guindani M, Versace F, Engelmann JM, Vannucci M. A spatiotemporal nonparametric Bayesian model of multi-subject fMRI data. Annals of Applied Statistics. 2016. Jun;10(2):638–66.
-
- Worsley KJ, Evans AC, Marrett S, Neelin P. A Three-Dimensional Statistical Analysis for CBF Activation Studies in Human Brain. Journal of Cerebral Blood Flow & Metabolism. 1992. Nov;12(6):900–18. - PubMed
-
- Forman SD, Cohen JD, Fitzgerald M, Eddy WF, Mintun MA, Noll DC. Improved Assessment of Significant Activation in Functional Magnetic Resonance Imaging (fMRI): Use of a Cluster-Size Threshold. Magnetic Resonance in Medicine. 1995;33(5):636–47. - PubMed
-
- Smith SM, Nichols TE. Threshold-free cluster enhancement: Addressing problems of smoothing, threshold dependence and localisation in cluster inference. NeuroImage. 2009. Jan;44(1):83–98. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources