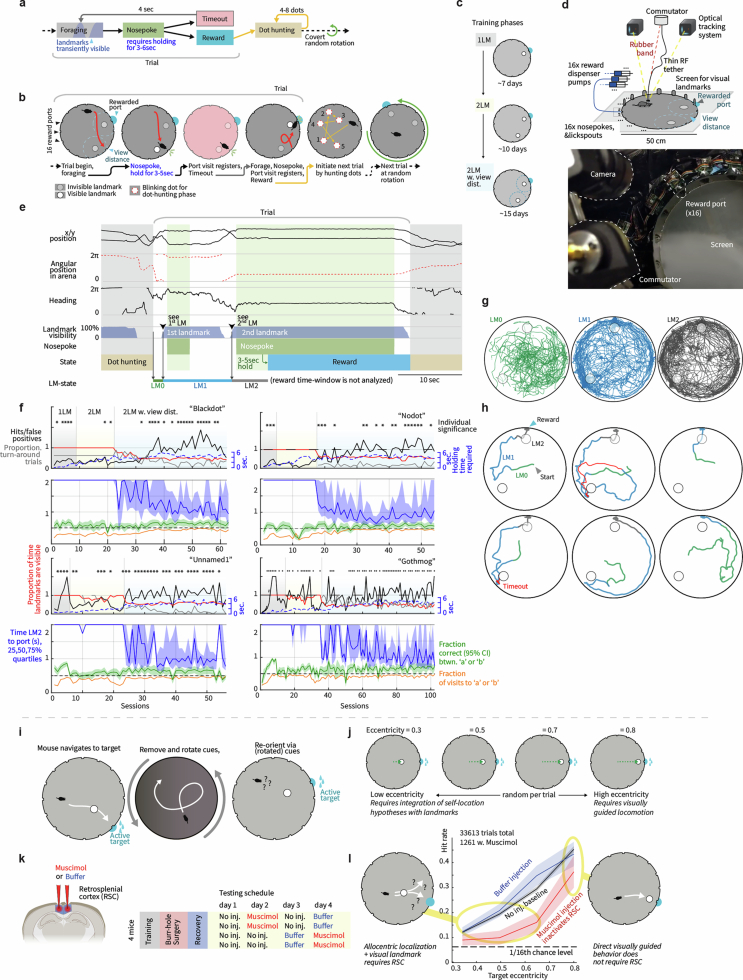
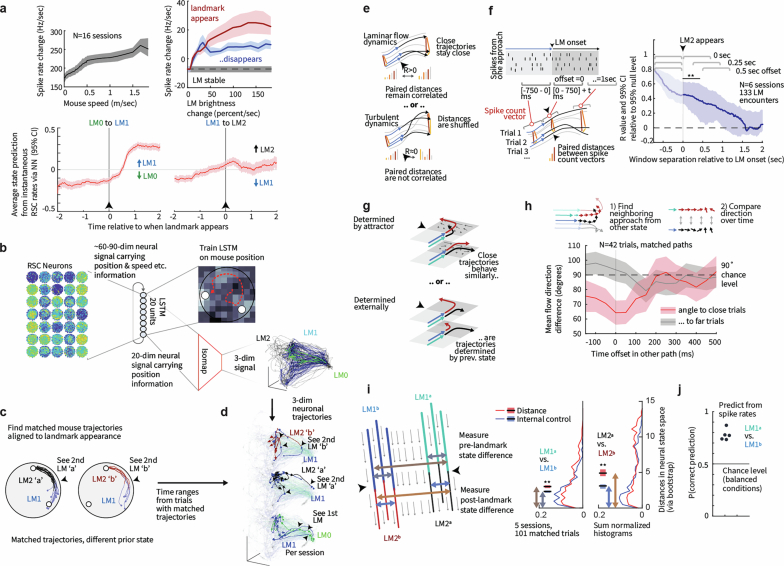
Extended Data Fig. 5. Architecture, trajectories, and population statistics for ANN with external map input.
(a) Structure of the recurrent network. Input neurons encoded noisy velocity input with linear tuning curves (similar to speed cells in the entorhinal cortex), and landmark information. In the standard setup (referred to as “external map”), the landmark input signaled the global configuration of landmarks (map). If there are K landmarks (all assumed to be perceptually indistinguishable), then whenever the animal encounters a landmark, the input provides a simultaneous encoding of all K landmark locations using spatially tuned input cells. Thus, the input encodes the map of the environment but does not disambiguate locations within it. This input can be thought of as originating from a distinct brain area that identifies the current environment and provides the network with its map. (b) Trajectories varied randomly and continuously in speed and direction. There were 2-4 landmarks at random locations. (c) Activity of output neurons ordered by preferred location as a function of time in an easy trial with two nearby landmarks and a constant velocity trajectory. Black arrows: landmark encounters. Thick black dashed line: time of disambiguation of location estimate in output layer. Thin red dashed line: true location. The network’s decision on when to collapse its estimate is flexible, and dynamically adapts the decision time to task difficulty: When the task is harder because of the configuration of landmarks (the task becomes harder as the two landmarks approach a 180 degree separation because of velocity noise and the resulting imprecision in estimating distances; the task is impossible at 180 degree because of symmetry), the network keeps alive multiple hypotheses about its states across more landmark encounters until it is able to reach an accurate decision. Panels c,d,f,g show example trials from experiment configuration 4 (See Methods) with different values of landmark separation parametrized by α. (d) Same as c, but in a difficult trial with two landmarks almost opposite of each other. (e) Top: The ANN took longer to disambiguate its location in harder task configurations: average time until disambiguation as a function of landmark separation (Standard error bars are narrower than line width). Middle: Distribution of the number of landmark encounters until the network disambiguates location, as a function of landmark separation. Bottom: Fraction of trials in which the network location estimate is closer to the correct than the alternative landmark location at the last landmark encounter, as a function of landmark separation. Data from 10000 trials in experiment configuration 4, 1000 for each of the 10 equally spaced values of α. The performance of the ANN (Fig. 2 main text) can be compared to the much poorer performance achieved by a strategy of path integration to update a single location estimate with landmark-based resets (to the coordinates of the landmark that is nearest the current path-integrated estimate), Fig. 2b (black versus gray). The latter strategy is equivalent to existing continuous attractor integration models, combined with a landmark- or border based resetting mechanism,,,, which to our knowledge is as far as models of brain localization circuits have gone in combining internal velocity-based estimates with external spatial cues. The present network goes beyond a simple resetting strategy, matching the performance of a sequential probabilistic estimator – the particle filter (PF) – which updates samples from a multi-peaked probability distribution over possible locations over time and is asymptotically Bayes-optimal (M = 1000 particles versus N = 128 neurons in network; Fig. 2b, lavender (PF) and green (enhanced PF)). Notably, the network matches PF performance without using stochastic or sampling-based representations, which have been proposed as possible neural mechanisms for probabilistic computation,. (f) Similar to c, but in a trial where the network disambiguates its location before the second landmark encounter. Yellow arrows mark times of landmark interactions if the alternative location hypothesis had been correct. Disambiguation occurs shortly after the absence of a landmark encounter at the first yellow arrow. (g) Similar to f, but in a trial where disambiguation occurs at the first landmark location, since no landmark has been encountered at the time denoted by the first gray arrow. (h) In the regular task where landmark identity must be inferred by the ANN, discrete hypothesis states (denoted LM0,1,2 throughout) emerge during the LM1 state. (j) If the ANN is instead given the landmark identity via separate input channels, it immediately identifies the correct location after the 1st landmark encounter and learns to acts as a simple path integration attractor without hypothesis states. Plots show ANN output as in c,d,g,f. (i,k) To quantify the separation of hypothesis states in the ANNs hidden states even in cases where such separation might not be evident in a PCA projection, we linearly projected hidden state activations onto the axis that separates the hypothesis states. The regular ANN shows a clear LM1 vs LM2 separation, but the ANN trained with landmark identity does not distinguish between these. (l) Population statistics for ANN with external map input. Scatter plot of enhanced particle filter (ePF) circular variance vs. estimate decoded from hidden layer of the network. 4000 trials from experiment configuration 1 were used to train a linear decoder on the posterior circular variance of the ePF from the activity of the hidden units and performance was evaluated on 1000 test trials. (m) Scatter plot of widths and heights of ANN tuning curves after the 2nd landmark encounter. Insets: example tuning curves corresponding to red dots. Unlike hand-designed continuous attractor networks, where neurons typically display homogeneous tuning across cells,,, our model reproduces the heterogeneity observed in hippocampus and associated cortical areas. Tuning curves are from LM2 using 1000 trials from experiment configuration 2 using 20 location bins. Tuning height specifies the difference between the tuning curve maximum and minimum, and tuning width denotes the fraction of the tuning curve above the mean of maximum and minimum. (n) The distribution of recurrent weights shows that groups of neurons with strong or weak location tuning or selectivity have similar patterns and strengths of connectivity within and between groups: distribution of absolute connection strength between and across location-sensitive “place cells” (PCs) and location-insensitive “unselective cells” (UCs) in the ANN. The black line denotes the mean; s.e.m. is smaller than the linewidth. The result is consistent with data suggesting that place cells and non-place cells do not form distinct sub-networks, but are part of a system that collectively encodes more than just place information. Location tuning curves were determined after the second landmark encounter using 5000 trials from distribution 1 and using 20 location bins. The resulting tuning curves were shifted to have minimum value 0 and normalized to sum to one. The location entropy of each neuron was defined to be the entropy of the normalized location tuning curve. Neurons were split in two equal sets according to their location entropy, where neurons with low entropy were defined as “place cells” (PCs) and neurons with high entropy were defined as “non-place cells” (UCs). Between and across PCs and UCs absolute connection strength was calculated as the absolute value of the recurrent weight between non-identical pairs. (o) Pairwise correlation structure is maintained across LM[1,2] states and environments. Corresponds to Fig. 3a. Top: Correlations in spatial tuning between pairs of cells in one environment after the 1st landmark encounter / LM1 (left), after the 2nd encounter / LM2, and in a separate environment in LM2 (right). The neurons are ordered according to their preferred locations in environment 1. Bottom: Example tuning curve pairs (normalized amplitude) corresponding to the indicated locations i-iv. Data from experiment configuration 1. (p) State-space activity of ANN is approximately 3-dimensional. Even when summed across all environments and random trajectories, the states still occupy a very low-dimensional subspace of the full state space, quantified by the correlation dimension as d ≈ 3 (left, see Methods). This measure typically overestimates manifold dimension, and serves as an upper bound on the true manifold dimension. As a control, the method yields a much larger dimension (d = 14) on the same network architecture with large random recurrent weights (right); thus, the low-dimensional dynamics are an emergent property of the network when it is trained on the navigation task. Data from 5000 trial, recurrent weights were sampled i.i.d. from a uniform distribution Wh,ij ~ U([ − 1, 1]), then fixed across trials. The initial hidden state across trials was sampled from ht=0,i ~ U([ − 1, 1]). Data from 5000 trials from experiment configuration 1. (q) In the LM2 state, position on the rate-space attractor corresponds to location in the maze. State-space trajectories after second landmark encounter for random trajectories. Color corresponds to true location (plot shows 100 trials). (r) ANN with external map input implements a circular attractor structure: Hidden layer activity arranged by preferred location in an example trial shows a bump of activity that moves coherently. Black arrows: first two landmark encounters. Preferred location was determined after the second landmark encounter using 5000 trials from experiment configuration 1. (s) Left: Recurrent weight matrix arranged by preferred location of neurons (determined after the second landmark encounter using 5000 trials from experiment configuration 1) indicates no apparent ring structure, despite apparent bump of activity that moves with velocity inputs (panel a). Right: However, recurrent coupling of modes defined by output weights (defined by , where are the recurrent weights and are the output weights) has a clear band structure. Connections between appropriate neural mixtures in the hidden layer – defined by the output projection of the neurons – therefore exhibit a circulant structure, but the actual recurrent weights do not, even after sorting neurons according to their preferred locations. The ANN thus implements a generalization of hand-wired attractor networks, in which the integration of velocity inputs by the recurrent weights occurs in a basis shuffled by an arbitrary linear transformation. Given these results, one cannot expect a connectomic reconstruction of a recurrent circuit to display an ordered matrix structure even when the dynamics are low-dimensional, without considering the output projection. Because trials in the mouse experiments typically ended almost immediately when the mouse had seen both landmarks (See Extended Data Fig. 1f for a quantification), we did not quantify the topology of the neural dynamics in RSC. (t) Low-dimensional state-space dynamics in the ANN with external map input suggests novel form of probabilistic encoding. Visualization of the full state-space dynamics of the hidden layer population, projected onto the three largest principal components, for constant-velocity trajectories. ANN hidden layer activity was low-dimensional: Fig. 3a shows data on low-dimensional dynamics, evident in maintained pairwise correlations, and Fig. 3d and panel p show correlation dimension. Trajectories are shown from the beginning of the trials; arrows indicate landmark encounter locations, black squares: first landmark encounter; black circles: second landmark encounter; line colors denote trajectory stage: LM0 (green), LM1 (blue), andLM2 (grey). Data in a-c is from 1000 trials from experiment configuration 3 (see Methods); sensory noise was set to zero. Trajectory starting points were selected to be a fixed distance before the first landmark. The intermediate ring (LM1) corresponds to times at which the output neurons represent multiple hypotheses, whereas the final location-coding ring (LM2), well-separated from the multiple hypothesis coding ring, corresponds to the period during which the output estimate has collapsed to a single hypothesis. In other words, the network internally encodes single-location hypothesis states separably from multi-location hypothesis states, as we find in RSC (Fig. 1), and transitions smoothly between them, a novel form of encoding of probability distributions that appears distinct from previously suggested forms of probabilistic representation,. (u) ANN trial trajectory examples, (corresponding to Fig. 2e). Divergence of trajectories for two paths that are idiothetically identical until after the second landmark encounter. ‘a’ and ‘b’ denote identities of locally ambiguous identical landmarks. Disambiguation occurs at the second landmark encounter, or by encountering locations where a landmark would be expected in the opposite identity assignments. See insets for geometry of trajectories and landmark locations. LM2 state has been simplified in these plots. (v) All four trajectories from panel b plotted simultaneously, and with full corresponding LM2 state. (w) The low-dimensional state-space manifold is stable, attracting perturbed states back to it, which suggests that the network dynamics follow a low-dimensional continuous attractor and the network’s computations are robust to most types of noise. Relaxations in state space after perturbations before the first (left), between first and second (middle), and after the second (right) landmark encounter. For the base trial, a trial with two landmarks and random trajectory was chosen. The first and second landmark encounter in this base trial is at time t = 2 s and t = 4.6 s respectively. At time t = 1 s (left), t = 4 s (middle), and t = 7 s (right) a multiplicative perturbation of size 50% was introduced at the hidden layer. See Extended Data Fig. 10l for same result on internal map ANNs.