

Development and validation of an autonomous artificial intelligence agent for clinical decision-making in oncology
- PMID: 40481323
- PMCID: PMC12380607
- DOI: 10.1038/s43018-025-00991-6
Development and validation of an autonomous artificial intelligence agent for clinical decision-making in oncology
Abstract
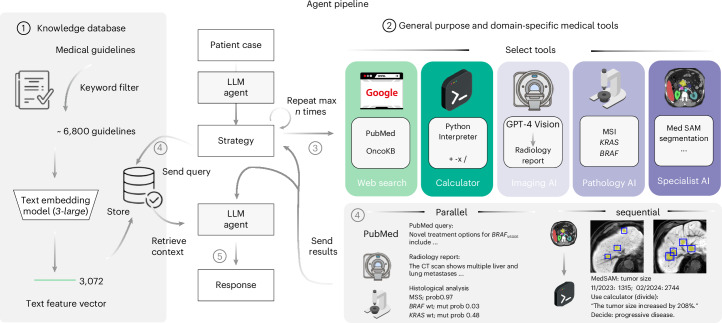
Clinical decision-making in oncology is complex, requiring the integration of multimodal data and multidomain expertise. We developed and evaluated an autonomous clinical artificial intelligence (AI) agent leveraging GPT-4 with multimodal precision oncology tools to support personalized clinical decision-making. The system incorporates vision transformers for detecting microsatellite instability and KRAS and BRAF mutations from histopathology slides, MedSAM for radiological image segmentation and web-based search tools such as OncoKB, PubMed and Google. Evaluated on 20 realistic multimodal patient cases, the AI agent autonomously used appropriate tools with 87.5% accuracy, reached correct clinical conclusions in 91.0% of cases and accurately cited relevant oncology guidelines 75.5% of the time. Compared to GPT-4 alone, the integrated AI agent drastically improved decision-making accuracy from 30.3% to 87.2%. These findings demonstrate that integrating language models with precision oncology and search tools substantially enhances clinical accuracy, establishing a robust foundation for deploying AI-driven personalized oncology support systems.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: O.S.M.E.N. holds shares in StratifAI. J.N.K. declares consulting services for Owkin, DoMore Diagnostics, Panakeia and Scailyte, holds shares in Kather Consulting, StratifAI and Synagen and has received honoraria for lectures and advisory board participation from AstraZeneca, Bayer, Eisai, MSD, BMS, Roche, Pfizer and Fresenius. D.T. has received honoraria for lectures by Bayer and holds shares in StratifAI and holds shares in Synagen. D.F. holds shares in Synagen. M.S.T. is a scientific advisor to Mindpeak and Sonrai Analytics and has received honoraria from BMS, MSD, Roche, Sanofi and Incyte. S.F. has received honoraria from MSD and BMS. The remaining authors declare no competing interests.
Figures





References
-
- Zhao, W. X. et al. A survey of large language models. Preprint at 10.48550/arXiv.2303.18223 (2023).
-
- OpenAI et al. GPT-4 technical report. Preprint at 10.48550/arXiv.2303.08774 (2023).
-
- Nori, H., King, N., McKinney, S. M., Carignan, D. & Horvitz, E. Capabilities of GPT-4 on medical challenge problems. Preprint at 10.48550/arXiv.2303.13375 (2023).
-
- Ferber, D. et al. GPT-4 for information retrieval and comparison of medical oncology guidelines. NEJM AI1, AIcs2300235 (2024).
-
- Acosta, J. N., Falcone, G. J., Rajpurkar, P. & Topol, E. J. Multimodal biomedical AI. Nat. Med.28, 1773–1784 (2022). - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Medical
Research Materials
Miscellaneous
