

Detecting Redundant Health Survey Questions by Using Language-Agnostic Bidirectional Encoder Representations From Transformers Sentence Embedding: Algorithm Development Study
- PMID: 40493668
- PMCID: PMC12173092
- DOI: 10.2196/71687
Detecting Redundant Health Survey Questions by Using Language-Agnostic Bidirectional Encoder Representations From Transformers Sentence Embedding: Algorithm Development Study
Abstract
Background: As the importance of person-generated health data (PGHD) in health care and research has increased, efforts have been made to standardize survey-based PGHD to improve its usability and interoperability. Standardization efforts such as the Patient-Reported Outcomes Measurement Information System (PROMIS) and the National Institutes of Health (NIH) Common Data Elements (CDE) repository provide effective tools for managing and unifying health survey questions. However, previous methods using ontology-mediated annotation are not only labor-intensive and difficult to scale but also challenging for identifying semantic redundancies in survey questions, especially across multiple languages.
Objective: The goal of this work was to compute the semantic similarity among publicly available health survey questions to facilitate the standardization of survey-based PGHD.
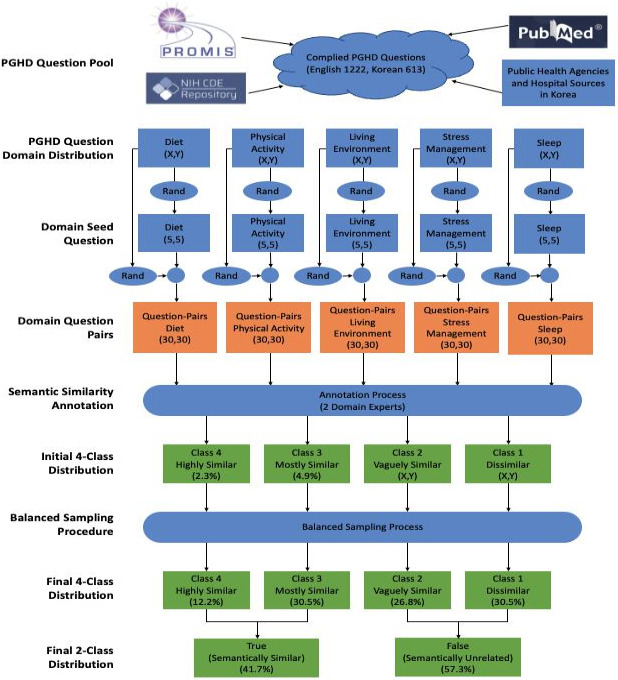
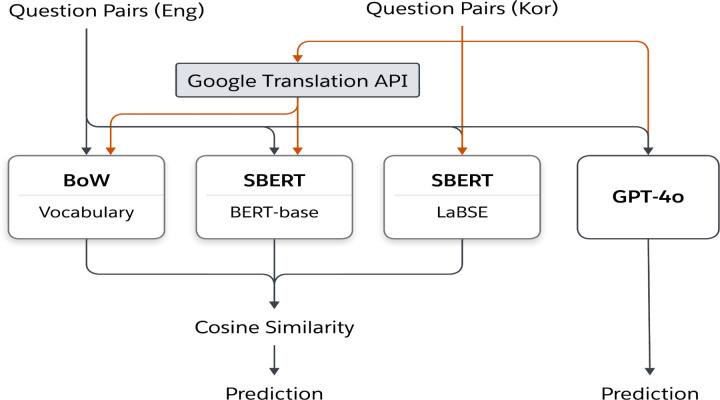
Methods: We compiled various health survey questions authored in both English and Korean from the NIH CDE repository, PROMIS, Korean public health agencies, and academic publications. Questions were drawn from various health lifelog domains. A randomized question pairing scheme was used to generate a semantic text similarity dataset consisting of 1758 question pairs. The similarity scores between each question pair were assigned by 2 human experts. The tagged dataset was then used to build 4 classifiers featuring bag-of-words, sentence-bidirectional encoder representations from transformers (SBERT) with bidirectional encoder representations from transformers (BERT)-based embeddings, SBERT with language-agnostic BERT sentence embedding (LaBSE), and GPT-4o. The algorithms were evaluated using traditional contingency statistics.
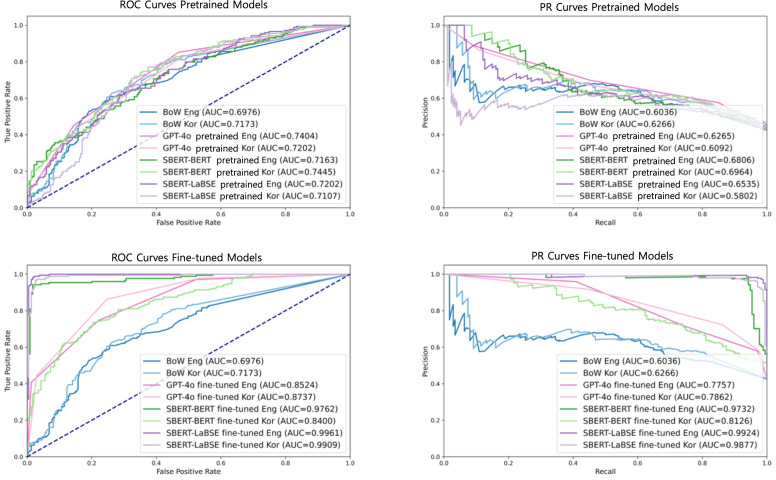
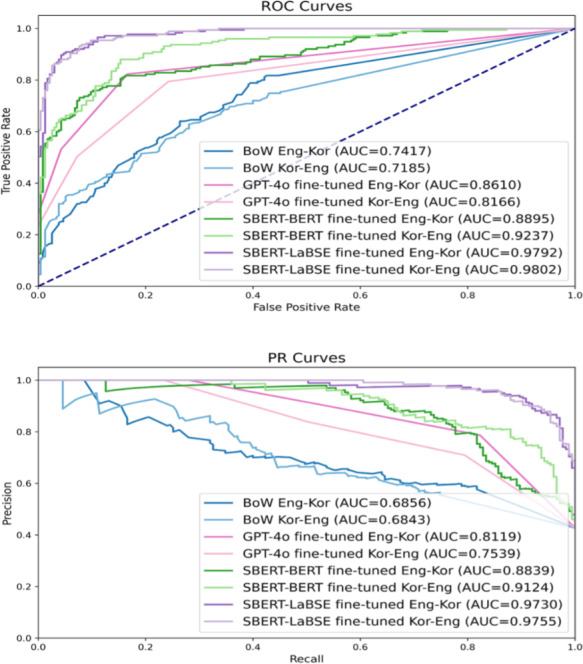
Results: Among the 3 algorithms, SBERT-LaBSE demonstrated the highest performance in assessing the question similarity across both languages, achieving area under the receiver operating characteristic and precision-recall curves of >0.99. Additionally, SBERT-LaBSE proved effective in identifying cross-lingual semantic similarities. The SBERT-LaBSE algorithm excelled at aligning semantically equivalent sentences across both languages but encountered challenges in capturing subtle nuances and maintaining computational efficiency. Future research should focus on testing with larger multilingual datasets and on calibrating and normalizing scores across the health lifelog domains to improve consistency.
Conclusions: This study introduces the SBERT-LaBSE algorithm for calculating the semantic similarity across 2 languages, showing that it outperforms BERT-based models, the GPT-4o model, and the bag-of-words approach, highlighting its potential in improving the semantic interoperability of survey-based PGHD across language barriers.
Keywords: BERT; LaBSE; PGHD; SBERT; bidirectional encoder representations from transformers; interoperability; language-agnostic BERT sentence embedding; person-generated health data; semantic similarity; sentence-bidirectional encoder representations from transformers.
© Sunghoon Kang, Hyewon Park, Ricky Taira, Hyeoneui Kim. Originally published in JMIR Medical Informatics (https://medinform.jmir.org).
Conflict of interest statement
Figures
References
-
- Shapiro M, Johnston D, Wald J, Mon D. Patient-generated health data. White paper. Official Website of the Assistant Secretary for Technology Policy/Office of the National Coordinator for Health IT. 2012. [31-05-2025]. https://www.healthit.gov/sites/default/files/rti_pghd_whitepaper_april_2... URL. Accessed.
-
- Patient-generated health data. Official Website of the Assistant Secretary for Technology Policy/Office of the National Coordinator for Health IT. [08-05-2025]. https://www.healthit.gov/topic/scientific-initiatives/pcor/patient-gener... URL. Accessed.
MeSH terms
LinkOut - more resources
Full Text Sources
