

Annotating neurophysiologic data at scale with optimized human input
- PMID: 40505672
- PMCID: PMC12223546
- DOI: 10.1088/1741-2552/ade402
Annotating neurophysiologic data at scale with optimized human input
Abstract
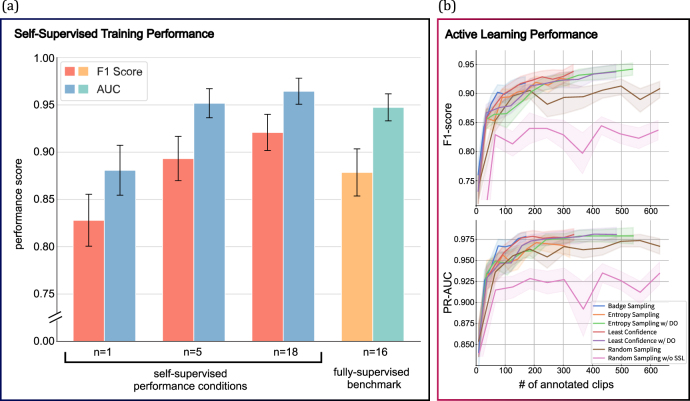
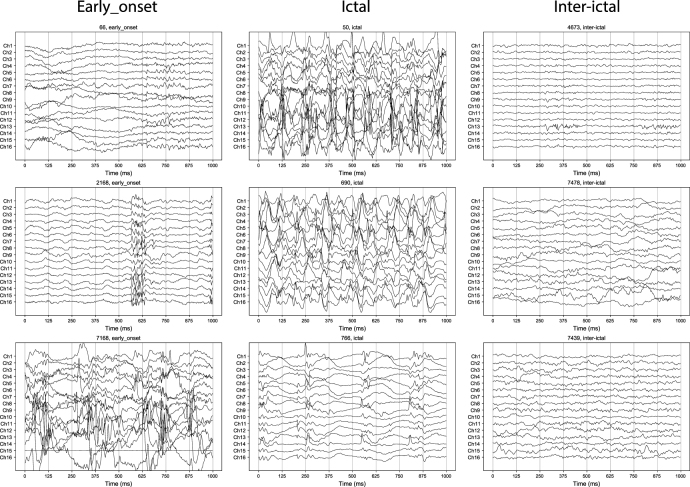
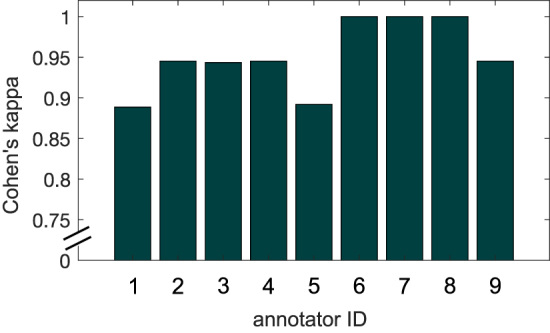
Objective.Neuroscience experiments and devices are generating unprecedented volumes of data, but analyzing and validating them presents practical challenges, particularly in annotation. While expert annotation remains the gold standard, it is time consuming to obtain and often poorly reproducible. Although automated annotation approaches exist, they rely on labeled data first to train machine learning algorithms, which limits their scalability. A semi-automated annotation approach that integrates human expertise while optimizing efficiency at scale is critically needed. To address this, we present Annotation Co-pilot, a human-in-the-loop solution that leverages deep active learning (AL) and self-supervised learning (SSL) to improve intracranial EEG (iEEG) annotation, significantly reducing the amount of human annotations.Approach.We automatically annotated iEEG recordings from 28 humans and 4 dogs with epilepsy implanted with two neurodevices that telemetered data to the cloud for analysis. We processed 1500 h of unlabeled iEEG recordings to train a deep neural network using a SSL method Swapping Assignments between View to generate robust, dataset-specific feature embeddings for the purpose of seizure detection. AL was used to select only the most informative data epochs for expert review. We benchmarked this strategy against standard methods.Main result.Over 80 000 iEEG clips, totaling 1176 h of recordings were analyzed. The algorithm matched the best published seizure detectors on two datasets (NeuroVista and NeuroPace responsive neurostimulation) but required, on average, only 1/6 of the human annotations to achieve similar accuracy (area under the ROC curve of 0.9628 ± 0.015) and demonstrated better consistency than human annotators (Cohen's Kappa of 0.95 ± 0.04).Significance. 'Annotation Co-pilot' demonstrated expert-level performance, robustness, and generalizability across two disparate iEEG datasets while reducing annotation time by an average of 83%. This method holds great promise for accelerating basic and translational research in electrophysiology, and potentially accelerating the pathway to clinical translation for AI-based algorithms and devices.
Keywords: active learning; annotation; epilepsy; human-in-the-loop; iEEG; seizure detection; self supervised learning.
Creative Commons Attribution license.
Figures






Similar articles
-
Leveraging a foundation model zoo for cell similarity search in oncological microscopy across devices.Front Oncol. 2025 Jun 18;15:1480384. doi: 10.3389/fonc.2025.1480384. eCollection 2025. Front Oncol. 2025. PMID: 40606969 Free PMC article.
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2021 Apr 19;4(4):CD011535. doi: 10.1002/14651858.CD011535.pub4. Cochrane Database Syst Rev. 2021. Update in: Cochrane Database Syst Rev. 2022 May 23;5:CD011535. doi: 10.1002/14651858.CD011535.pub5. PMID: 33871055 Free PMC article. Updated.
-
Semi-Supervised Learning Allows for Improved Segmentation With Reduced Annotations of Brain Metastases Using Multicenter MRI Data.J Magn Reson Imaging. 2025 Jun;61(6):2469-2479. doi: 10.1002/jmri.29686. Epub 2025 Jan 10. J Magn Reson Imaging. 2025. PMID: 39792624 Free PMC article.
-
Reliability of visual review of intracranial electroencephalogram in identifying the seizure onset zone: A systematic review and implications for the accuracy of automated methods.Epilepsia. 2023 Jan;64(1):6-16. doi: 10.1111/epi.17446. Epub 2022 Nov 10. Epilepsia. 2023. PMID: 36300659 Free PMC article.
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2017 Dec 22;12(12):CD011535. doi: 10.1002/14651858.CD011535.pub2. Cochrane Database Syst Rev. 2017. Update in: Cochrane Database Syst Rev. 2020 Jan 9;1:CD011535. doi: 10.1002/14651858.CD011535.pub3. PMID: 29271481 Free PMC article. Updated.
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources