

Evaluating and Improving Syndrome Differentiation Thinking Ability in Large Language Models: Method Development Study
- PMID: 40540614
- PMCID: PMC12204376
- DOI: 10.2196/75103
Evaluating and Improving Syndrome Differentiation Thinking Ability in Large Language Models: Method Development Study
Abstract
Background: A large language model (LLM) provides new opportunities to advance the intelligent development of traditional Chinese medicine (TCM). Syndrome differentiation thinking is an essential part of TCM and equipping LLMs with this capability represents a crucial step toward more effective clinical applications of TCM. However, given the complexity of TCM syndrome differentiation thinking, acquiring this ability is a considerable challenge for the model.
Objective: This study aims to evaluate the ability of LLMs for syndrome differentiation thinking and design a method to effectively enhance their performance in this area.
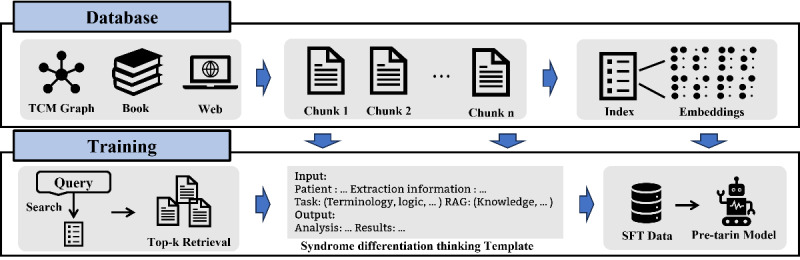
Methods: We decomposed the process of syndrome differentiation thinking in TCM into three core tasks: pathogenesis inference, syndrome inference, and diagnostic suggestion. To evaluate the performance of LLMs in these tasks, we constructed a high-quality evaluation dataset, forming a reliable foundation for quantitative assessment of their capabilities. Furthermore, we developed a methodology for generating instruction data based on the idea of an "open-book exam," customized three data templates, and dynamically retrieved task-relevant professional knowledge that was inserted into predefined positions within the templates. This approach effectively generates high-quality instruction data that aligns with the unique characteristics of TCM syndrome differentiation thinking. Leveraging this instruction data, we fine-tuned the base model, enhancing the syndrome differentiation thinking ability of the LLMs.
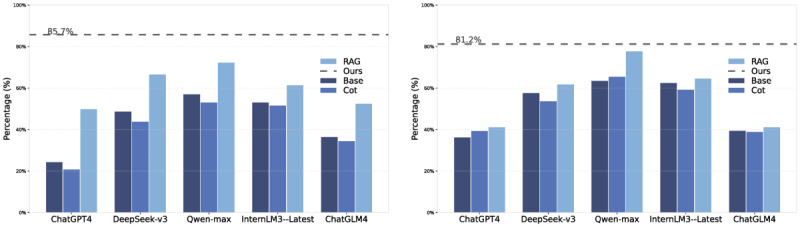
Results: We collected 200 medical cases for the evaluation dataset and standardized them into three types of task questions. We tested general and TCM-specific LLMs, comparing their performance with our proposed solution. The findings demonstrated that our method significantly enhanced LLMs' syndrome differentiation thinking. Our model achieved 85.7% in Task 1 and 81.2% accuracy in Task 2, surpassing the best-performing TCM and general LLMs by 26.3% and 15.8%, respectively. In Task 3, our model achieved a similarity score of 84.3, indicating that the model was remarkably similar to advice given by experts.
Conclusions: Existing general LLMs and TCM-specific LLMs continue to have significant limitations in the core task of syndrome differentiation thinking. Our research shows that fine-tuning LLMs by designing professional instruction templates and generating high-quality instruction data can significantly improve their performance on core tasks. The optimized LLMs show a high degree of similarity in reasoning results, consistent with the opinions of domain experts, indicating that they can simulate syndrome differentiation thinking to a certain extent. These findings have important theoretical and practical significance for in-depth interpretation of the complexity of the clinical diagnosis and treatment process of TCM.
Keywords: RAG; TCM LLMs; instruction tuning; large language model; syndrome differentiation thinking; traditional Chinese medicine.
© Chunliang Chen, Xinyu Wang, Ming Guan, Wenjing Yue, Yuanbin Wu, Ya Zhou, Xiaoling Wang. Originally published in JMIR Medical Informatics (https://medinform.jmir.org).
Conflict of interest statement
Figures

Similar articles
-
A Weighted Voting Approach for Traditional Chinese Medicine Formula Classification Using Large Language Models: Algorithm Development and Validation Study.JMIR Med Inform. 2025 Jul 24;13:e69286. doi: 10.2196/69286. JMIR Med Inform. 2025. PMID: 40705933 Free PMC article.
-
Evaluating and Enhancing Japanese Large Language Models for Genetic Counseling Support: Comparative Study of Domain Adaptation and the Development of an Expert-Evaluated Dataset.JMIR Med Inform. 2025 Jan 16;13:e65047. doi: 10.2196/65047. JMIR Med Inform. 2025. PMID: 39819819 Free PMC article.
-
Enhancing Pulmonary Disease Prediction Using Large Language Models With Feature Summarization and Hybrid Retrieval-Augmented Generation: Multicenter Methodological Study Based on Radiology Report.J Med Internet Res. 2025 Jun 11;27:e72638. doi: 10.2196/72638. J Med Internet Res. 2025. PMID: 40499132 Free PMC article.
-
Implementing Large Language Models in Health Care: Clinician-Focused Review With Interactive Guideline.J Med Internet Res. 2025 Jul 11;27:e71916. doi: 10.2196/71916. J Med Internet Res. 2025. PMID: 40644686 Free PMC article. Review.
-
Survivor, family and professional experiences of psychosocial interventions for sexual abuse and violence: a qualitative evidence synthesis.Cochrane Database Syst Rev. 2022 Oct 4;10(10):CD013648. doi: 10.1002/14651858.CD013648.pub2. Cochrane Database Syst Rev. 2022. PMID: 36194890 Free PMC article.
Cited by
-
Artificial Intelligence in Traditional Chinese Medicine: Multimodal Fusion and Machine Learning for Enhanced Diagnosis and Treatment Efficacy.Curr Med Sci. 2025 Aug 7. doi: 10.1007/s11596-025-00103-6. Online ahead of print. Curr Med Sci. 2025. PMID: 40773005 Review.
-
Assessing the adherence of large language models to clinical practice guidelines in Chinese medicine: a content analysis.Front Pharmacol. 2025 Jul 25;16:1649041. doi: 10.3389/fphar.2025.1649041. eCollection 2025. Front Pharmacol. 2025. PMID: 40786055 Free PMC article.
References
-
- Pal S, Bhattacharya M, Islam MA, Chakraborty C. ChatGPT or LLM in next-generation drug discovery and development: pharmaceutical and biotechnology companies can make use of the artificial intelligence-based device for a faster way of drug discovery and development. Int J Surg. 2023 Dec 1;109(12):4382–4384. doi: 10.1097/JS9.0000000000000719. doi. Medline. - DOI - PMC - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
