

A multimodal visual-language foundation model for computational ophthalmology
- PMID: 40542189
- PMCID: PMC12181238
- DOI: 10.1038/s41746-025-01772-2
A multimodal visual-language foundation model for computational ophthalmology
Abstract
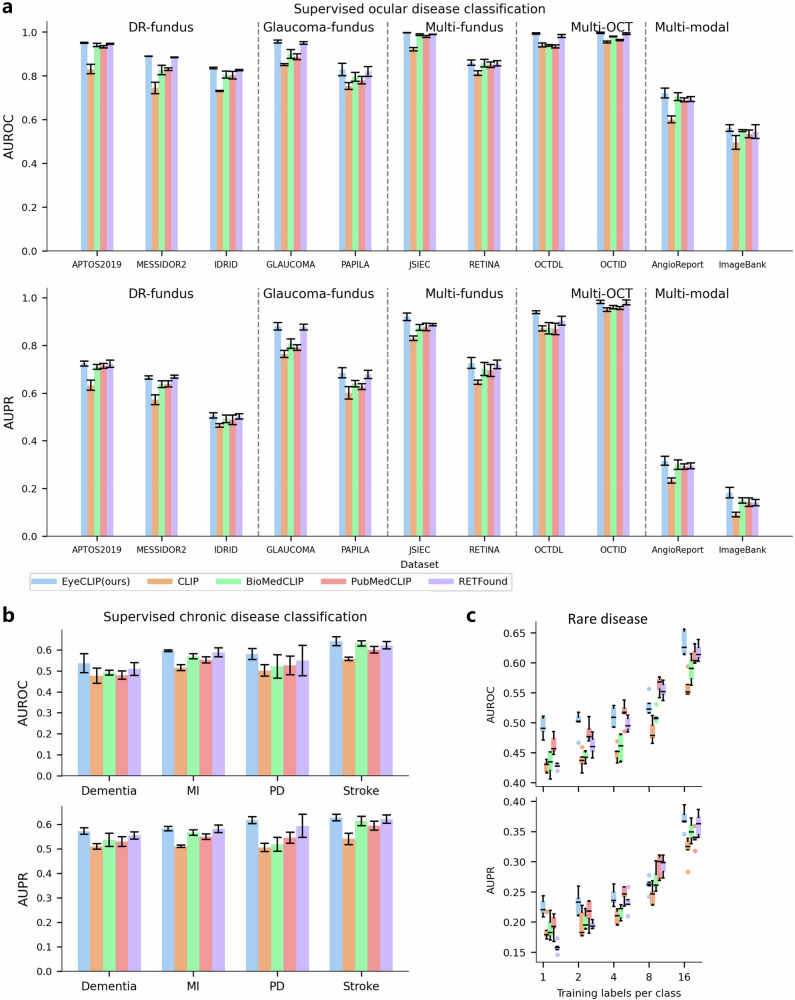
Early detection of eye diseases is vital for preventing vision loss. Existing ophthalmic artificial intelligence models focus on single modalities, overlooking multi-view information and struggling with rare diseases due to long-tail distributions. We propose EyeCLIP, a multimodal visual-language foundation model trained on 2.77 million ophthalmology images from 11 modalities with partial clinical text. Our novel pretraining strategy combines self-supervised reconstruction, multimodal image contrastive learning, and image-text contrastive learning to capture shared representations across modalities. EyeCLIP demonstrates robust performance across 14 benchmark datasets, excelling in disease classification, visual question answering, and cross-modal retrieval. It also exhibits strong few-shot and zero-shot capabilities, enabling accurate predictions in real-world, long-tail scenarios. EyeCLIP offers significant potential for detecting both ocular and systemic diseases, and bridging gaps in real-world clinical applications.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures




Similar articles
-
VIIDA and InViDe: computational approaches for generating and evaluating inclusive image paragraphs for the visually impaired.Disabil Rehabil Assist Technol. 2025 Jul;20(5):1470-1495. doi: 10.1080/17483107.2024.2437567. Epub 2024 Dec 11. Disabil Rehabil Assist Technol. 2025. PMID: 39661561
-
Social Reasoning-Aware Trajectory Prediction via Multimodal Language Model.IEEE Trans Pattern Anal Mach Intell. 2025 Jun 20;PP. doi: 10.1109/TPAMI.2025.3582000. Online ahead of print. IEEE Trans Pattern Anal Mach Intell. 2025. PMID: 40540377
-
Mixture of prompts learning for vision-language models.Front Artif Intell. 2025 Jun 10;8:1580973. doi: 10.3389/frai.2025.1580973. eCollection 2025. Front Artif Intell. 2025. PMID: 40556640 Free PMC article.
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
Interventions for eye movement disorders due to acquired brain injury.Cochrane Database Syst Rev. 2018 Mar 5;3(3):CD011290. doi: 10.1002/14651858.CD011290.pub2. Cochrane Database Syst Rev. 2018. PMID: 29505103 Free PMC article.
Cited by
-
Artificial Intelligence Improves Patient Follow-Up in a Diabetic Retinopathy Screening Program [Letter].Clin Ophthalmol. 2025 Aug 9;19:2659-2660. doi: 10.2147/OPTH.S537960. eCollection 2025. Clin Ophthalmol. 2025. PMID: 40823159 Free PMC article. No abstract available.
References
Grants and funding
LinkOut - more resources
Full Text Sources
