

Public Versus Academic Discourse on ChatGPT in Health Care: Mixed Methods Study
- PMID: 40550010
- PMCID: PMC12208614
- DOI: 10.2196/64509
Public Versus Academic Discourse on ChatGPT in Health Care: Mixed Methods Study
Abstract
Background: The rapid emergence of artificial intelligence-based large language models (LLMs) in 2022 has initiated extensive discussions within the academic community. While proponents highlight LLMs' potential to improve writing and analytical tasks, critics caution against the ethical and cultural implications of widespread reliance on these models. Existing literature has explored various aspects of LLMs, including their integration, performance, and utility, yet there is a gap in understanding the nature of these discussions and how public perception contrasts with expert opinion in the field of public health.
Objective: This study sought to explore how the general public's views and sentiments regarding LLMs, using OpenAI's ChatGPT as an example, differ from those of academic researchers and experts in the field, with the goal of gaining a more comprehensive understanding of the future role of LLMs in health care.
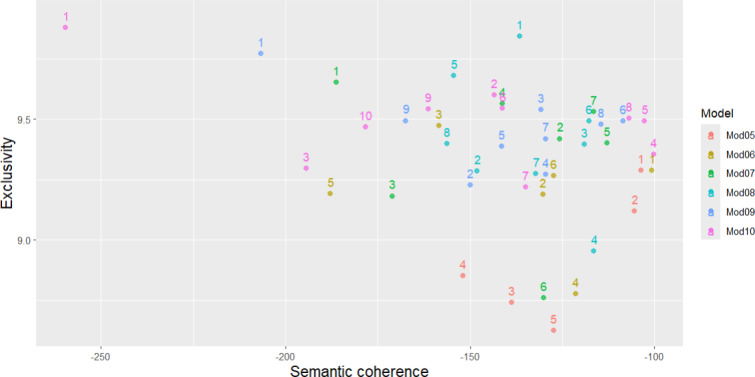
Methods: We used a hybrid sentiment analysis approach, integrating the Syuzhet package in R (R Core Team) with GPT-3.5, achieving an 84% accuracy rate in sentiment classification. Also, structural topic modeling was applied to identify and analyze 8 key discussion topics, capturing both optimistic and critical perspectives on LLMs.
Results: Findings revealed a predominantly positive sentiment toward LLM integration in health care, particularly in areas such as patient care and clinical decision-making. However, concerns were raised regarding their suitability for mental health support and patient communication, highlighting potential limitations and ethical challenges.
Conclusions: This study underscores the transformative potential of LLMs in public health while emphasizing the need to address ethical and practical concerns. By comparing public discourse with academic perspectives, our findings contribute to the ongoing scholarly debate on the opportunities and risks associated with LLM adoption in health care.
Keywords: ethics, medical; health knowledge, attitudes, practice; large language models; natural language processing; sentiment analysis; social media discourse; structural topic modeling.
© Patrick Baxter, Meng-Hao Li, Jiaxin Wei, Naoru Koizumi. Originally published in JMIR Infodemiology (https://infodemiology.jmir.org).
Conflict of interest statement
Figures
References
-
- Oehler A, Horn M. Does ChatGPT provide better advice than robo-advisors? Finance Research Letters. 2024 Feb;60:104898. doi: 10.1016/j.frl.2023.104898. doi. - DOI
-
- Rawas S. ChatGPT: Empowering lifelong learning in the digital age of higher education. Educ Inf Technol. 2024 Apr;29(6):6895–6908. doi: 10.1007/s10639-023-12114-8. doi. - DOI
-
- Ságodi Z, Siket I, Ferenc R. Methodology for code synthesis evaluation of LLMs presented by a case study of ChatGPT and copilot. IEEE Access. 2024;12:72303–72316. doi: 10.1109/ACCESS.2024.3403858. doi. - DOI
-
- Kim J, Lee J, Jang KM, Lourentzou I. Exploring the limitations in how ChatGPT introduces environmental justice issues in the United States: A case study of 3,108 counties. Telematics and Informatics. 2024 Feb;86:102085. doi: 10.1016/j.tele.2023.102085. doi. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
