

Mixture of prompts learning for vision-language models
- PMID: 40556640
- PMCID: PMC12185420
- DOI: 10.3389/frai.2025.1580973
Mixture of prompts learning for vision-language models
Abstract
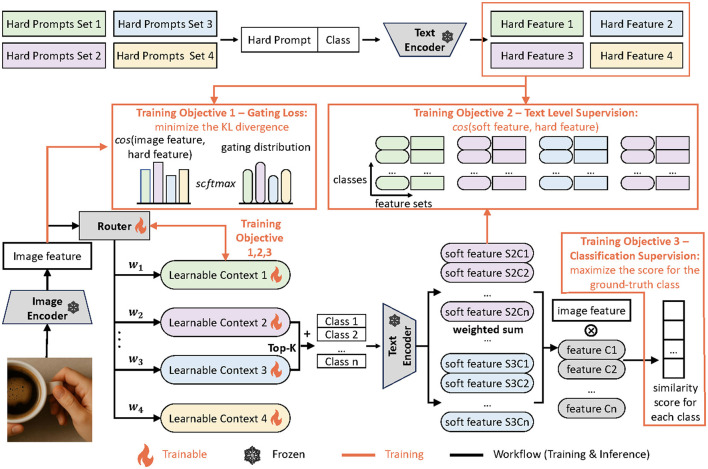
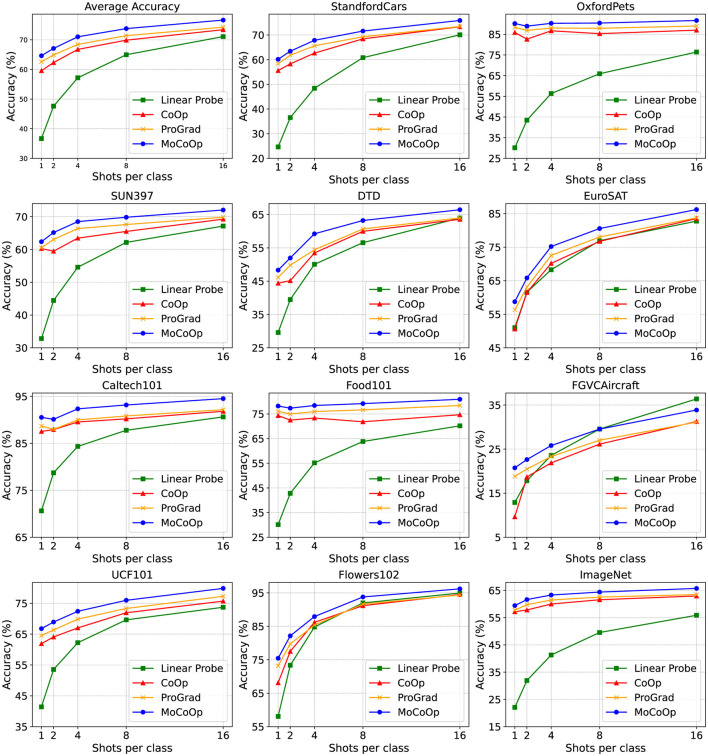
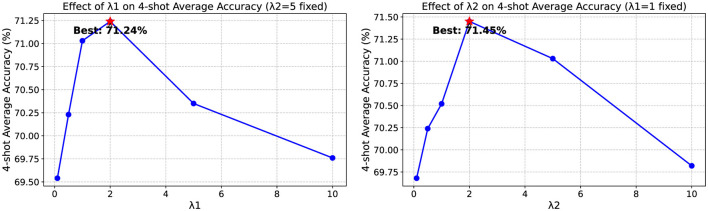
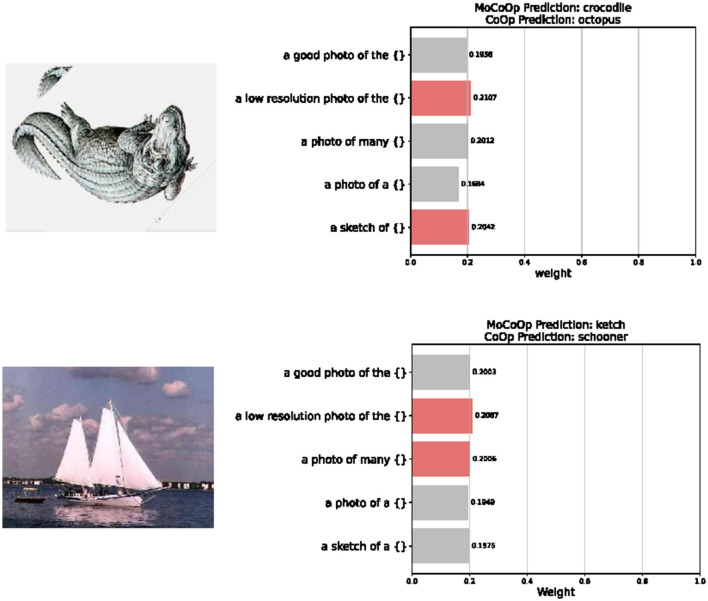
As powerful pre-trained vision-language models (VLMs) like CLIP gain prominence, numerous studies have attempted to combine VLMs for downstream tasks. Among these, prompt learning has been validated as an effective method for adapting to new tasks, which only requires a small number of parameters. However, current prompt learning methods face two challenges: first, a single soft prompt struggles to capture the diverse styles and patterns within a dataset; second, fine-tuning soft prompts is prone to overfitting. To address these challenges, we propose a mixture-of-prompts learning method incorporating a routing module. This module is able to capture a dataset's varied styles and dynamically select the most suitable prompts for each instance. Additionally, we introduce a novel gating mechanism to ensure the router selects prompts based on their similarity to hard prompt templates, which both retains knowledge from hard prompts and improves selection accuracy. We also implement semantically grouped text-level supervision, initializing each soft prompt with the token embeddings of manually designed templates from its group and applying a contrastive loss between the resulted text feature and hard prompt encoded text feature. This supervision ensures that the text features derived from soft prompts remain close to those from their corresponding hard prompts, preserving initial knowledge and mitigating overfitting. Our method has been validated on 11 datasets, demonstrating evident improvements in few-shot learning, domain generalization, and base-to-new generalization scenarios compared to existing baselines. Our approach establishes that multi-prompt specialization with knowledge-preserving routing effectively bridges the adaptability-generalization tradeoff in VLM deployment. The code will be available at https://github.com/dyabel/mocoop.
Keywords: few-shot classification; mixture-of-experts; multi-modal; prompt learning; vision-language model.
Copyright © 2025 Du, Niu and Zhao.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
![Diagram illustrating the categorization of images with different styles into hard prompts, including people's activities, art and renditions, low-quality photos, and cropped photos. Each category contains specific examples, such as “A photo of a person doing [class]” and “Art of the [class].” A flowchart below this shows how soft prompts combine with image features to determine the class.](https://cdn.ncbi.nlm.nih.gov/pmc/blobs/4a0a/12185420/f7c595c9361a/frai-08-1580973-g0001.jpg)
Similar articles
-
MCPL: Multi-Modal Collaborative Prompt Learning for Medical Vision-Language Model.IEEE Trans Med Imaging. 2024 Dec;43(12):4224-4235. doi: 10.1109/TMI.2024.3418408. Epub 2024 Dec 2. IEEE Trans Med Imaging. 2024. PMID: 38913527
-
Medical Knowledge Intervention Prompt Tuning for Medical Image Classification.IEEE Trans Med Imaging. 2025 Jul 1;PP. doi: 10.1109/TMI.2025.3584841. Online ahead of print. IEEE Trans Med Imaging. 2025. PMID: 40591469
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2021 Apr 19;4(4):CD011535. doi: 10.1002/14651858.CD011535.pub4. Cochrane Database Syst Rev. 2021. Update in: Cochrane Database Syst Rev. 2022 May 23;5:CD011535. doi: 10.1002/14651858.CD011535.pub5. PMID: 33871055 Free PMC article. Updated.
-
The educational effects of portfolios on undergraduate student learning: a Best Evidence Medical Education (BEME) systematic review. BEME Guide No. 11.Med Teach. 2009 Apr;31(4):282-98. doi: 10.1080/01421590902889897. Med Teach. 2009. PMID: 19404891
References
-
- Achiam J., Adler S., Agarwal S., Ahmad L., Akkaya I., Aleman F. L., et al. (2023). Gpt-4 technical report. arXiv preprint arXiv:2303.08774. 10.48550/arXiv.2303.08774 - DOI
-
- Bossard L., Guillaumin M., Van Gool L. (2014). “Food-101-mining discriminative components with random forests,” in Computer vision-ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part VI 13 (Springer: New York; ), 446–461. 10.1007/978-3-319-10599-4_29 - DOI
-
- Bulat A., Tzimiropoulos G. (2022). Lasp: text-to-text optimization for language-aware soft prompting of vision and language models. arXiv preprint arXiv:2210.01115. 10.1109/CVPR52729.2023.02225 - DOI
-
- Cimpoi M., Maji S., Kokkinos I., Mohamed S., Vedaldi A. (2014). “Describing textures in the wild,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Piscataway, NJ: IEEE; ), 3606–3613. 10.1109/CVPR.2014.461 - DOI
-
- Crowson K., Biderman S., Kornis D., Stander D., Hallahan E., Castricato L., et al. (2022). “Vqgan-clip: open domain image generation and editing with natural language guidance,” in European Conference on Computer Vision (Springer: New York; ), 88–105. 10.1007/978-3-031-19836-6_6 - DOI
LinkOut - more resources
Full Text Sources
Research Materials