

Research on Plant RNA-Binding Protein Prediction Method Based on Improved Ensemble Learning
- PMID: 40563923
- PMCID: PMC12189372
- DOI: 10.3390/biology14060672
Research on Plant RNA-Binding Protein Prediction Method Based on Improved Ensemble Learning
Abstract
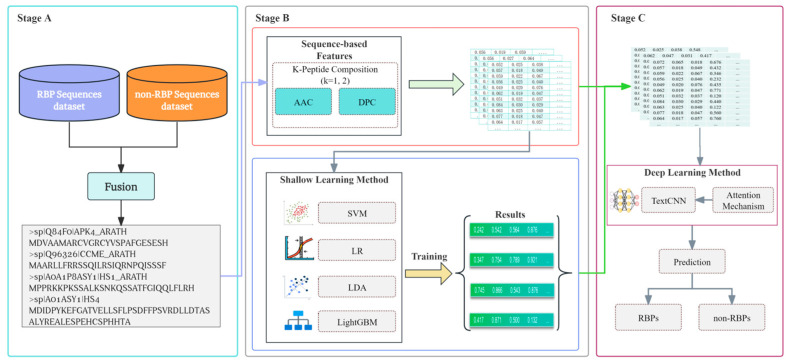
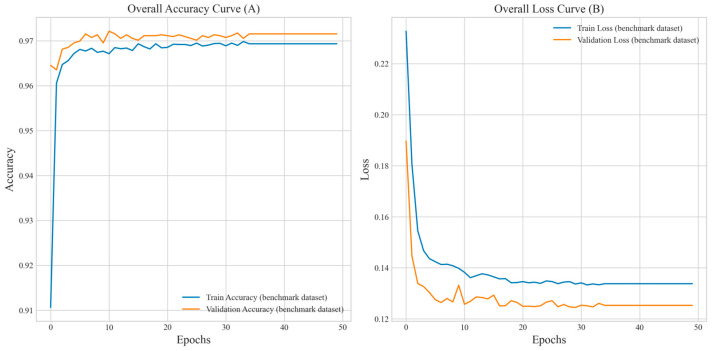
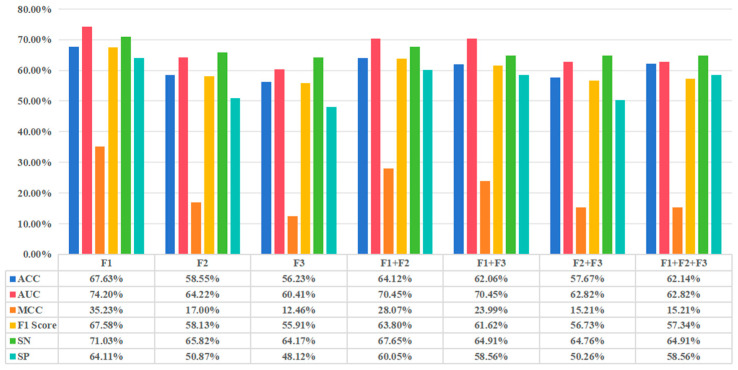
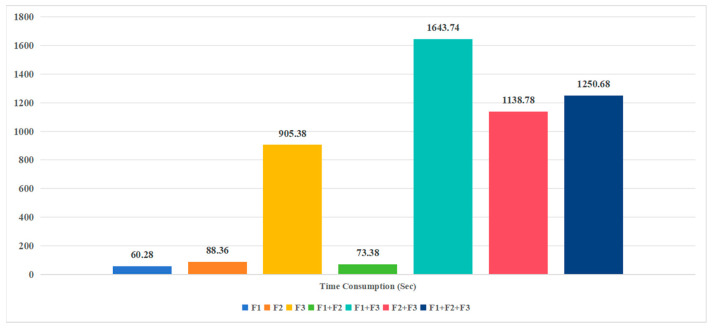
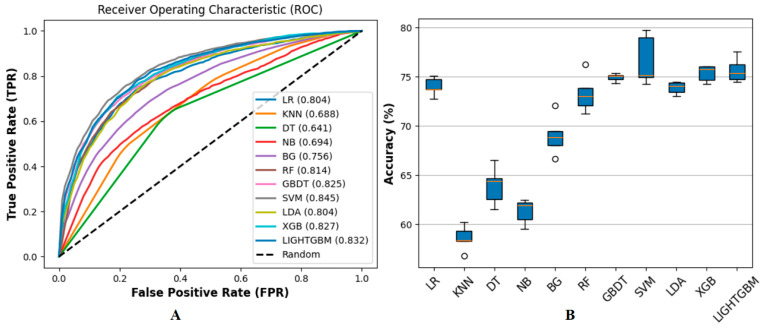
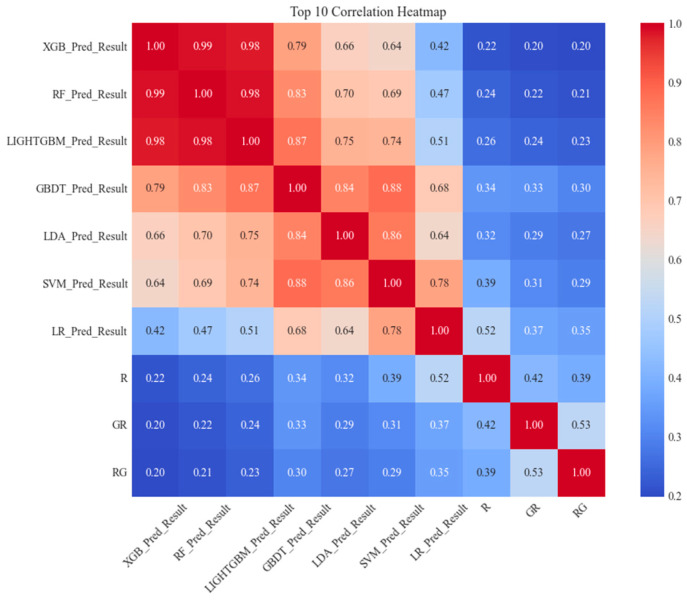
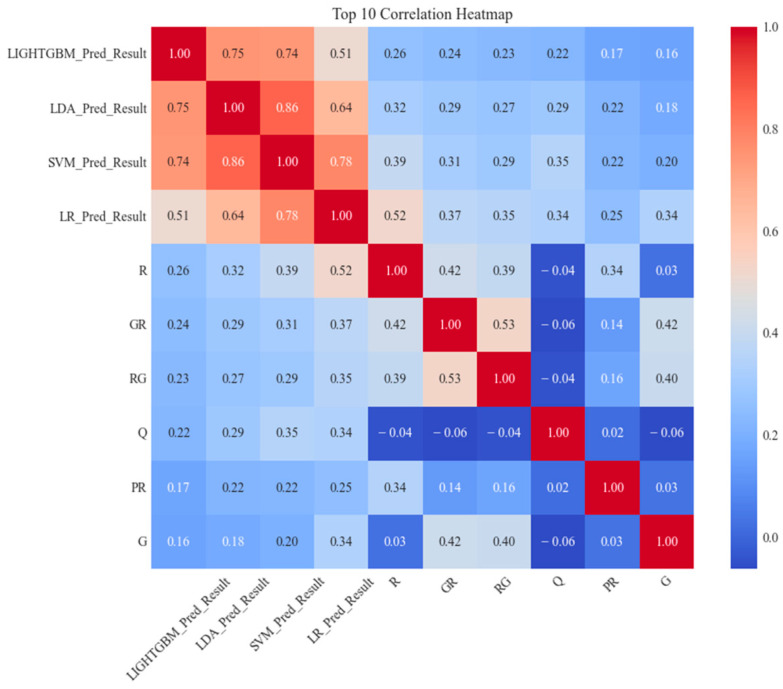
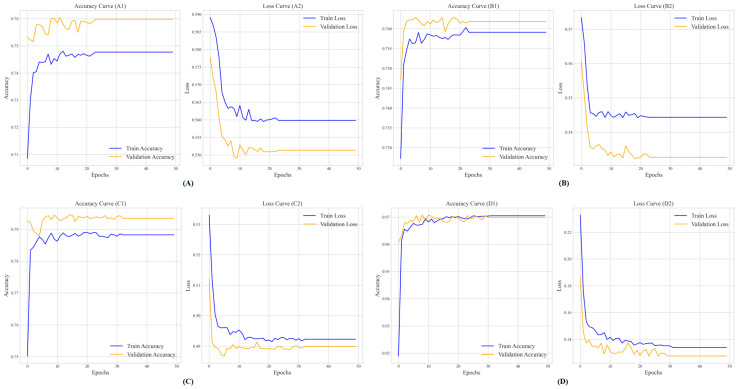
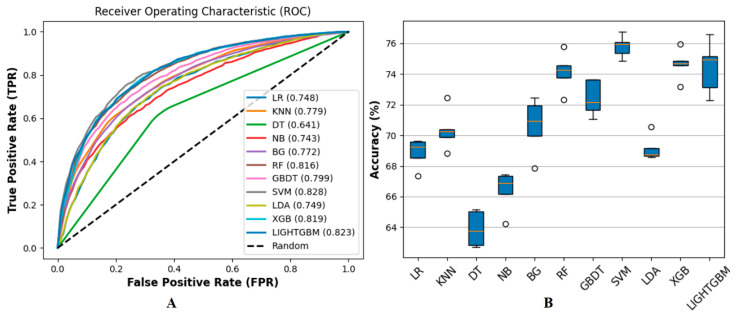
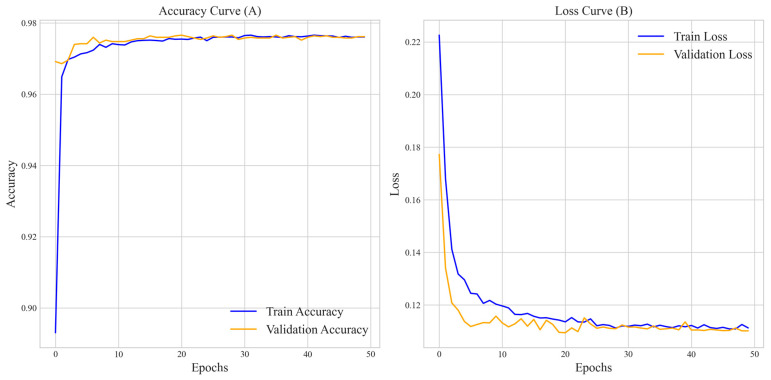
(1) RNA-binding proteins (RBPs) play a crucial role in regulating gene expression in plants, affecting growth, development, and stress responses. Accurate prediction of plant-specific RBPs is vital for understanding gene regulation and enhancing genetic improvement. (2) Methods: We propose an ensemble learning method that integrates shallow and deep learning. It integrates prediction results from SVM, LR, LDA, and LightGBM into an enhanced TextCNN, using K-Peptide Composition (KPC) encoding (k = 1, 2) to form a 420-dimensional feature vector, extended to 424 dimensions by including those four prediction outputs. Redundancy is minimized using a Pearson correlation threshold of 0.80. (3) Results: On the benchmark dataset of 4992 sequences, our method achieved an ACC of 97.20% and 97.06% under 5-fold and 10-fold cross-validation, respectively. On an independent dataset of 1086 sequences, our method attained an ACC of 99.72%, an F1score of 99.72%, an MCC of 99.45%, an SN of 99.63%, and an SP of 99.82%, outperforming RBPLight by 12.98 percentage points in ACC and the original TextCNN by 25.23 percentage points. (4) Conclusions: These results highlight our method's superior accuracy and efficiency over PSSM-based approaches, enabling large-scale plant RBP prediction.
Keywords: RBPs; RNA-binding proteins; TextCNN; ensemble learning; plant.
Conflict of interest statement
The authors declare no conflicts of interest.
Figures
Similar articles
-
ToxinPred 3.0: An improved method for predicting the toxicity of peptides.Comput Biol Med. 2024 Sep;179:108926. doi: 10.1016/j.compbiomed.2024.108926. Epub 2024 Jul 21. Comput Biol Med. 2024. PMID: 39038391
-
Interventions to reduce harm from continued tobacco use.Cochrane Database Syst Rev. 2016 Oct 13;10(10):CD005231. doi: 10.1002/14651858.CD005231.pub3. Cochrane Database Syst Rev. 2016. PMID: 27734465 Free PMC article.
-
Cost-effectiveness of using prognostic information to select women with breast cancer for adjuvant systemic therapy.Health Technol Assess. 2006 Sep;10(34):iii-iv, ix-xi, 1-204. doi: 10.3310/hta10340. Health Technol Assess. 2006. PMID: 16959170
-
Enhancing Pulmonary Disease Prediction Using Large Language Models With Feature Summarization and Hybrid Retrieval-Augmented Generation: Multicenter Methodological Study Based on Radiology Report.J Med Internet Res. 2025 Jun 11;27:e72638. doi: 10.2196/72638. J Med Internet Res. 2025. PMID: 40499132 Free PMC article.
-
Stacked Ensemble Learning for Classification of Parkinson's Disease Using Telemonitoring Vocal Features.Diagnostics (Basel). 2025 Jun 9;15(12):1467. doi: 10.3390/diagnostics15121467. Diagnostics (Basel). 2025. PMID: 40564788 Free PMC article.
References
-
- Koletsou E., Huppertz I. RNA-binding proteins as versatile metabolic regulators. Npj Metab. Health Disease. 2025;3:1. doi: 10.1038/s44324-024-00044-z. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
