

Facial Landmark-Driven Keypoint Feature Extraction for Robust Facial Expression Recognition
- PMID: 40573649
- PMCID: PMC12196885
- DOI: 10.3390/s25123762
Facial Landmark-Driven Keypoint Feature Extraction for Robust Facial Expression Recognition
Abstract
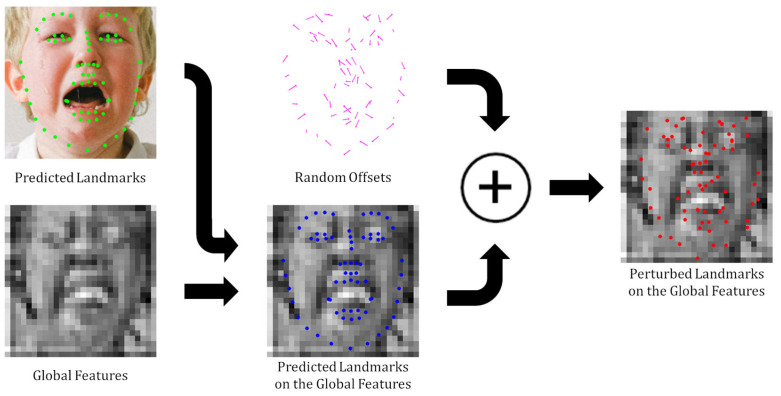
Facial expression recognition (FER) is a core technology that enables computers to understand and react to human emotions. In particular, the use of face alignment algorithms as a preprocessing step in image-based FER is important for accurately normalizing face images in terms of scale, rotation, and translation to improve FER accuracy. Recently, FER studies have been actively leveraging feature maps computed by face alignment networks to enhance FER performance. However, previous studies were limited in their ability to effectively apply information from specific facial regions that are important for FER, as they either only used facial landmarks during the preprocessing step or relied solely on the feature maps from the face alignment networks. In this paper, we propose the use of Keypoint Features extracted from feature maps at the coordinates of facial landmarks. To effectively utilize Keypoint Features, we further propose a Keypoint Feature regularization method using landmark perturbation for robustness, and an attention mechanism that emphasizes all Keypoint Features using representative Keypoint Features derived from a nasal base landmark, which carries information for the whole face, to improve performance. We performed experiments on the AffectNet, RAF-DB, and FERPlus datasets using a simply designed network to validate the effectiveness of the proposed method. As a result, the proposed method achieved a performance of 68.17% on AffectNet-7, 64.87% on AffectNet-8, 93.16% on RAF-DB, and 91.44% on FERPlus. Furthermore, the network pretrained on AffectNet-8 had improved performances of 94.04% on RAF-DB and 91.66% on FERPlus. These results demonstrate that the proposed Keypoint Features can achieve comparable results to those of the existing methods, highlighting their potential for enhancing FER performance through the effective utilization of key facial region features.
Keywords: deep neural network; face alignment; facial expression recognition; feature attention.
Conflict of interest statement
The authors declare no conflicts of interest.
Figures









Similar articles
-
Enhanced AlexNet with Gabor and Local Binary Pattern Features for Improved Facial Emotion Recognition.Sensors (Basel). 2025 Jun 19;25(12):3832. doi: 10.3390/s25123832. Sensors (Basel). 2025. PMID: 40573719 Free PMC article.
-
Facial Emotion Recognition of 16 Distinct Emotions From Smartphone Videos: Comparative Study of Machine Learning and Human Performance.J Med Internet Res. 2025 Jul 2;27:e68942. doi: 10.2196/68942. J Med Internet Res. 2025. PMID: 40601921 Free PMC article.
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
New Trends in Emotion Recognition Using Image Analysis by Neural Networks, A Systematic Review.Sensors (Basel). 2023 Aug 10;23(16):7092. doi: 10.3390/s23167092. Sensors (Basel). 2023. PMID: 37631629 Free PMC article.
-
Education support services for improving school engagement and academic performance of children and adolescents with a chronic health condition.Cochrane Database Syst Rev. 2023 Feb 8;2(2):CD011538. doi: 10.1002/14651858.CD011538.pub2. Cochrane Database Syst Rev. 2023. PMID: 36752365 Free PMC article.
References
-
- Zheng C., Mendieta M., Chen C. POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops; Paris, France. 2–6 October 2023; pp. 3146–3155.
-
- Mao J., Xu R., Yin X., Chang Y., Nie B., Huang A., Wang Y. Poster++: A simpler and stronger Facial Expression Recognition network. Pattern Recognit. 2024;148:110951. doi: 10.1016/j.patcog.2024.110951. - DOI
-
- Zhang Y., Wang C., Ling X., Deng W. Learn from all: Erasing attention consistency for noisy label facial expression recognition; Proceedings of the European Conference on Computer Vision (ECCV); Tel Aviv, Israel. 23–27 October 2022; pp. 418–434.
-
- Zhao Z., Liu Q., Zhou F. Robust lightweight Facial Expression Recognition network with label distribution training; Proceedings of the AAAI Conference on Artificial Intelligence (AAAI); Online. 2–9 February 2021; pp. 3510–3519.
-
- Mollahosseini A., Hasani B., Mahoor M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017;10:18–31. doi: 10.1109/TAFFC.2017.2740923. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous
