

From Biased Selective Labels to Pseudo-Labels: An Expectation-Maximization Framework for Learning from Biased Decisions
- PMID: 40574796
- PMCID: PMC12199211
From Biased Selective Labels to Pseudo-Labels: An Expectation-Maximization Framework for Learning from Biased Decisions
Abstract
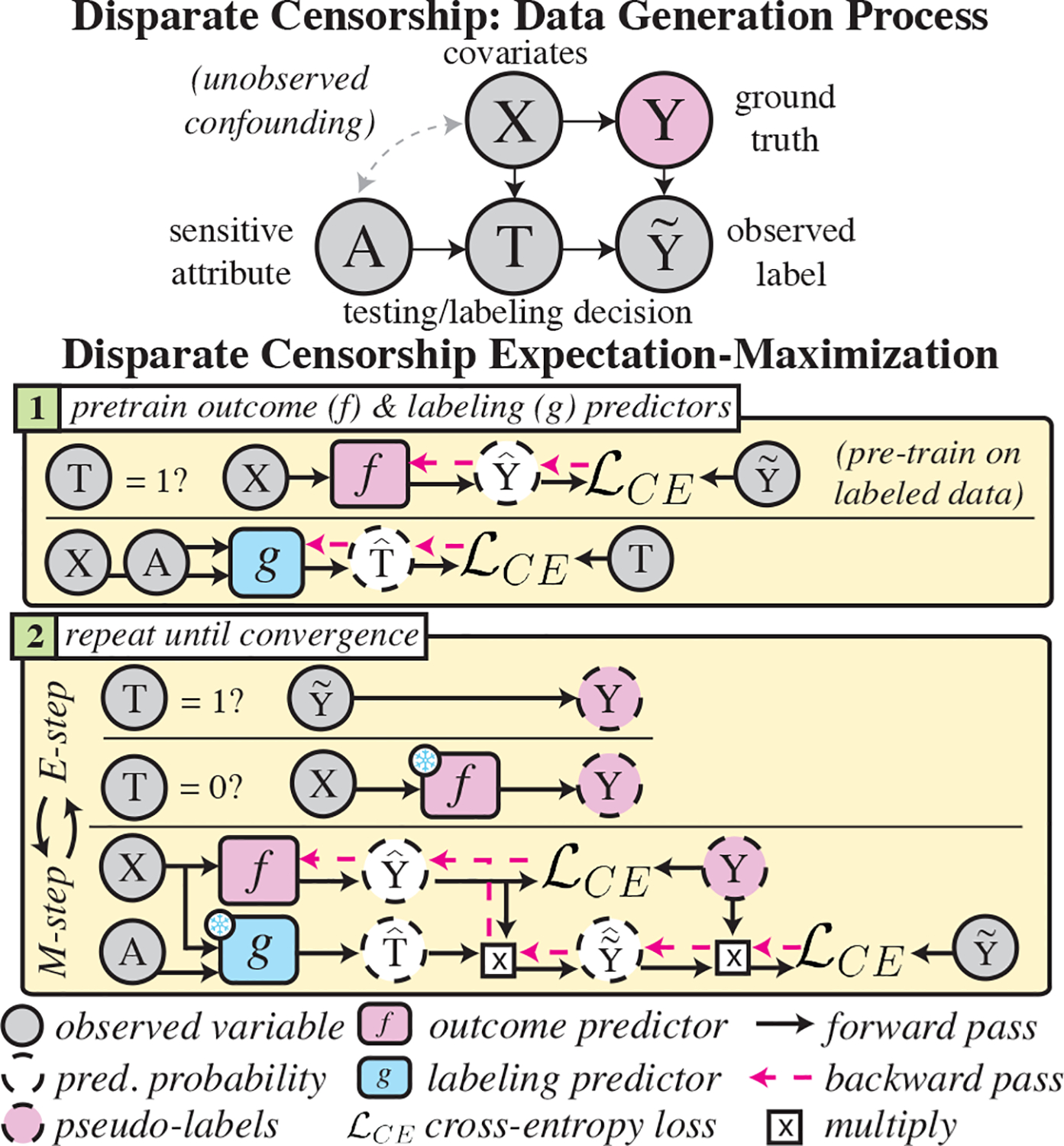
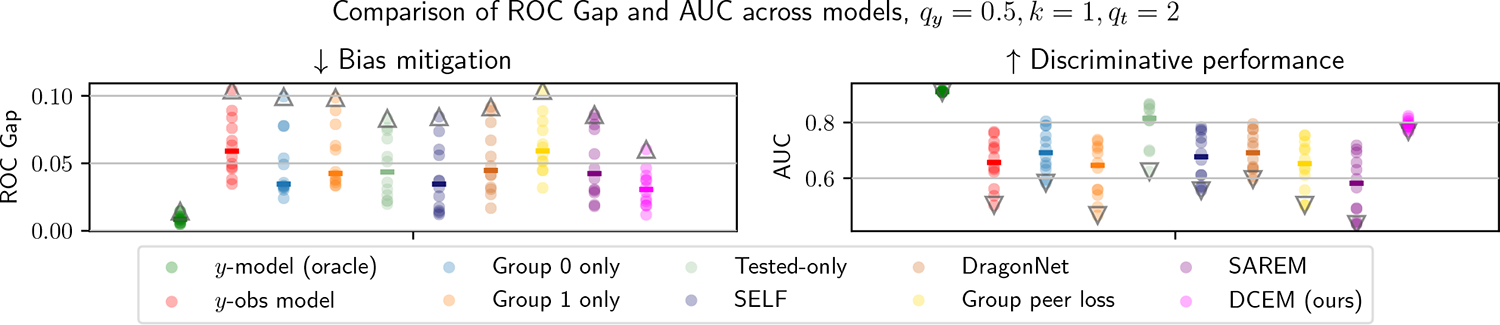
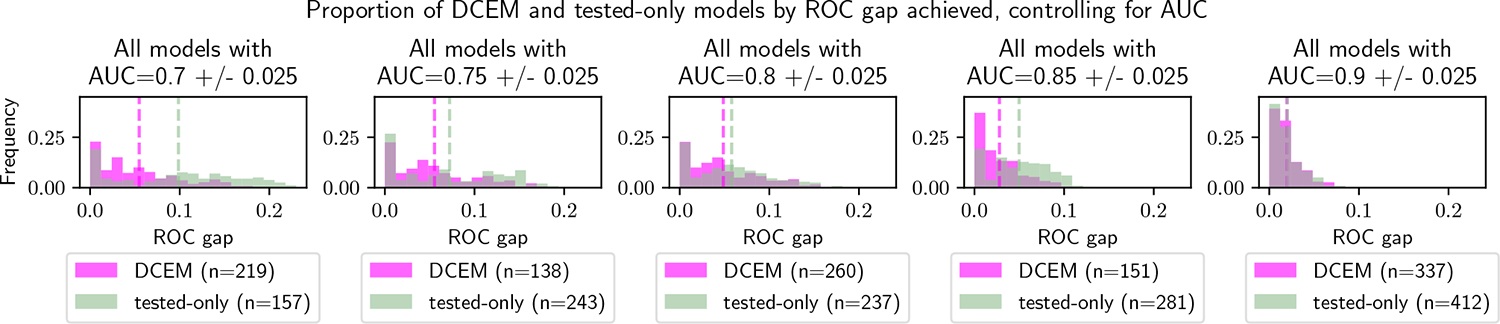
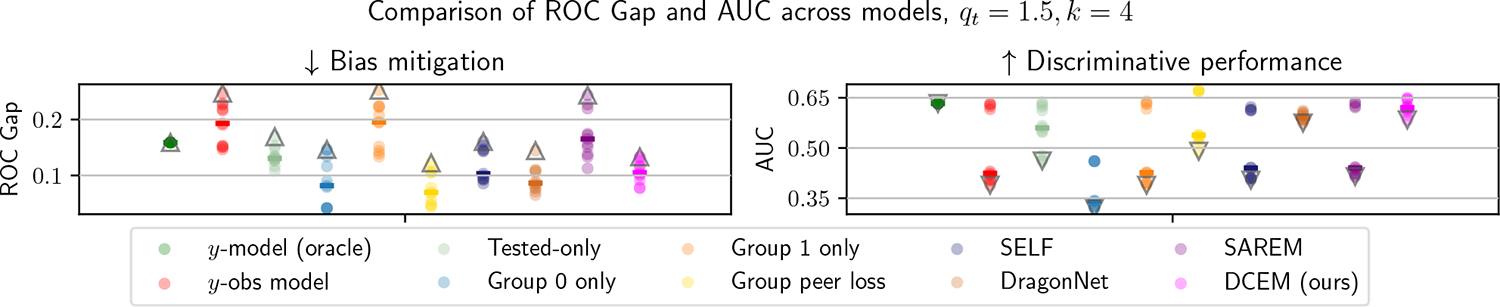
Selective labels occur when label observations are subject to a decision-making process; e.g., diagnoses that depend on the administration of laboratory tests. We study a clinically-inspired selective label problem called disparate censorship, where labeling biases vary across subgroups and unlabeled individuals are imputed as "negative" (i.e., no diagnostic test = no illness). Machine learning models naïvely trained on such labels could amplify labeling bias. Inspired by causal models of selective labels, we propose Disparate Censorship Expectation-Maximization (DCEM), an algorithm for learning in the presence of disparate censorship. We theoretically analyze how DCEM mitigates the effects of disparate censorship on model performance. We validate DCEM on synthetic data, showing that it improves bias mitigation (area between ROC curves) without sacrificing discriminative performance (AUC) compared to baselines. We achieve similar results in a sepsis classification task using clinical data.
Figures
Similar articles
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
Control interventions in randomised trials among people with mental health disorders.Cochrane Database Syst Rev. 2022 Apr 4;4(4):MR000050. doi: 10.1002/14651858.MR000050.pub2. Cochrane Database Syst Rev. 2022. PMID: 35377466 Free PMC article.
-
Cost-effectiveness of using prognostic information to select women with breast cancer for adjuvant systemic therapy.Health Technol Assess. 2006 Sep;10(34):iii-iv, ix-xi, 1-204. doi: 10.3310/hta10340. Health Technol Assess. 2006. PMID: 16959170
-
Eliciting adverse effects data from participants in clinical trials.Cochrane Database Syst Rev. 2018 Jan 16;1(1):MR000039. doi: 10.1002/14651858.MR000039.pub2. Cochrane Database Syst Rev. 2018. PMID: 29372930 Free PMC article.
-
Artificial intelligence for detecting keratoconus.Cochrane Database Syst Rev. 2023 Nov 15;11(11):CD014911. doi: 10.1002/14651858.CD014911.pub2. Cochrane Database Syst Rev. 2023. PMID: 37965960 Free PMC article.
References
-
- Adams R, Henry KE, Sridharan A, Soleimani H, Zhan A, Rawat N, Johnson L, Hager DN, Cosgrove SE, Markowski A, et al. Prospective, multi-site study of patient outcomes after implementation of the trews machine learning-based early warning system for sepsis. Nature Medicine, pp. 1–6, 2022. - PubMed
-
- Ambroise C and Govaert G EM algorithm for partially known labels. In Data Analysis, Classification, and Related Methods, pp. 161–166. Springer, 2000.
-
- Arazo E, Ortego D, Albert P, O’Connor NE, and McGuinness K Pseudo-labeling and confirmation bias in deep semi-supervised learning. In 2020 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. IEEE, 2020.
-
- Arpit D, Jastrzebski S, Ballas N, Krueger D, Bengio E, Kanwal MS, Maharaj T, Fischer A, Courville A, Bengio Y, and Lacoste-Julien S A closer look at memorization in deep networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp. 233–242, 2017.
-
- Bahadori MT, Chalupka K, Choi E, Chen R, Stewart WF, and Sun J Causal regularization. arXiv preprint arXiv:1702.02604, 2017.
Grants and funding
LinkOut - more resources
Full Text Sources