

This is a preprint.
Diverse Genomes, Shared Health: Insights from a Health System Biobank
- PMID: 40585105
- PMCID: PMC12204455
- DOI: 10.1101/2025.06.11.25329386
Diverse Genomes, Shared Health: Insights from a Health System Biobank
Abstract
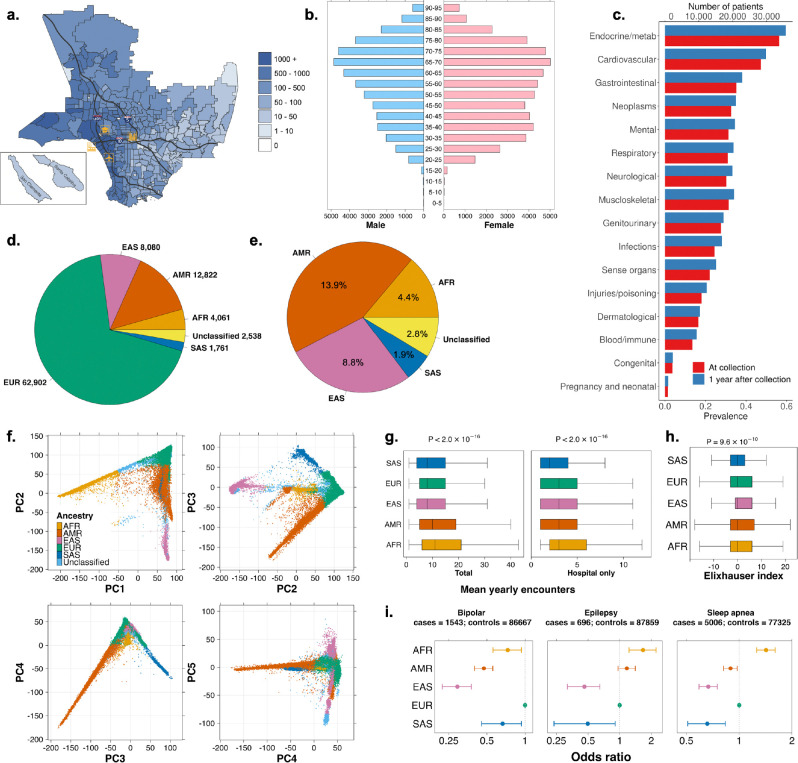
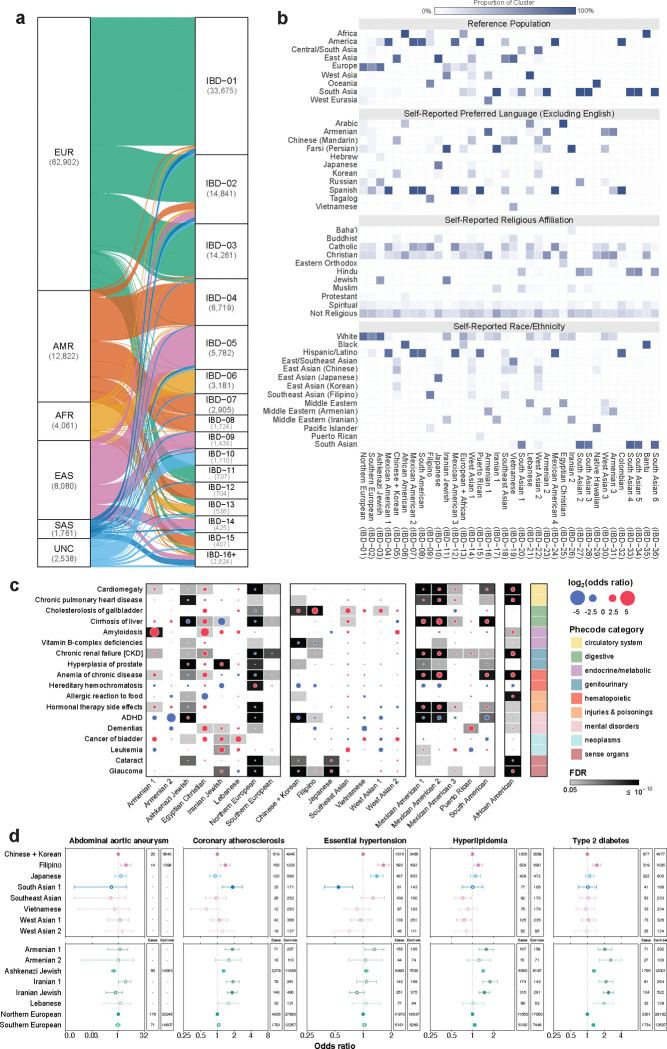
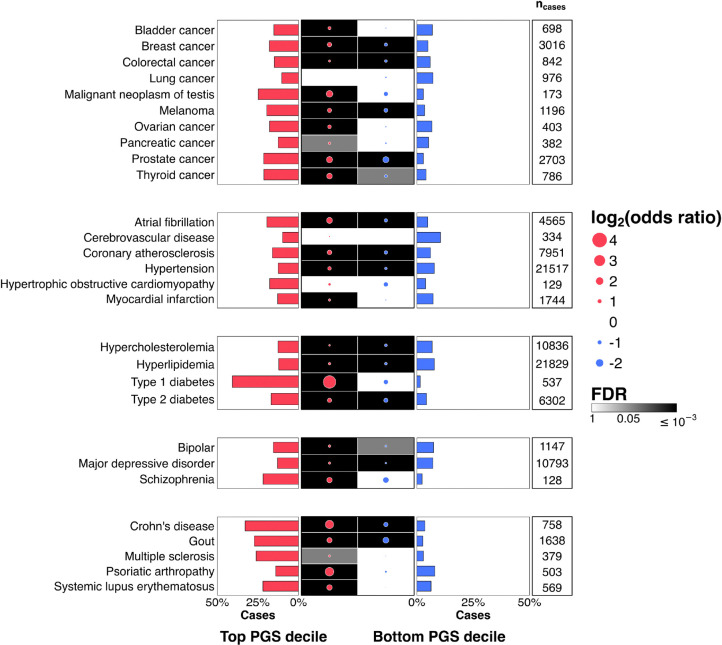
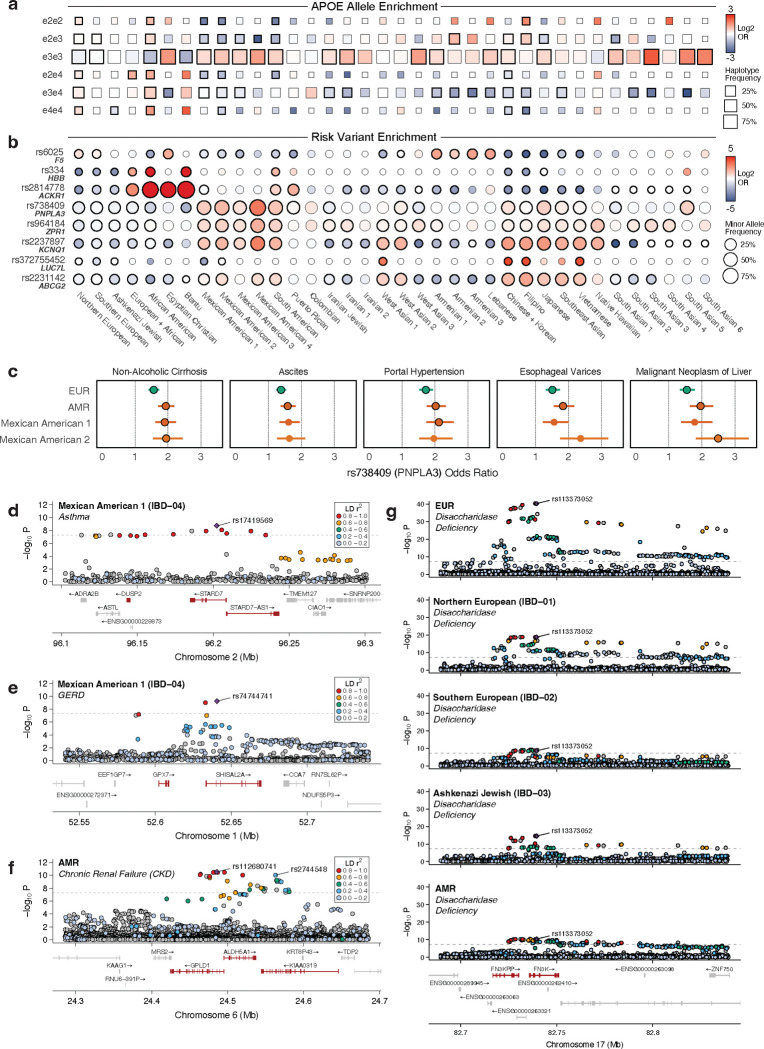
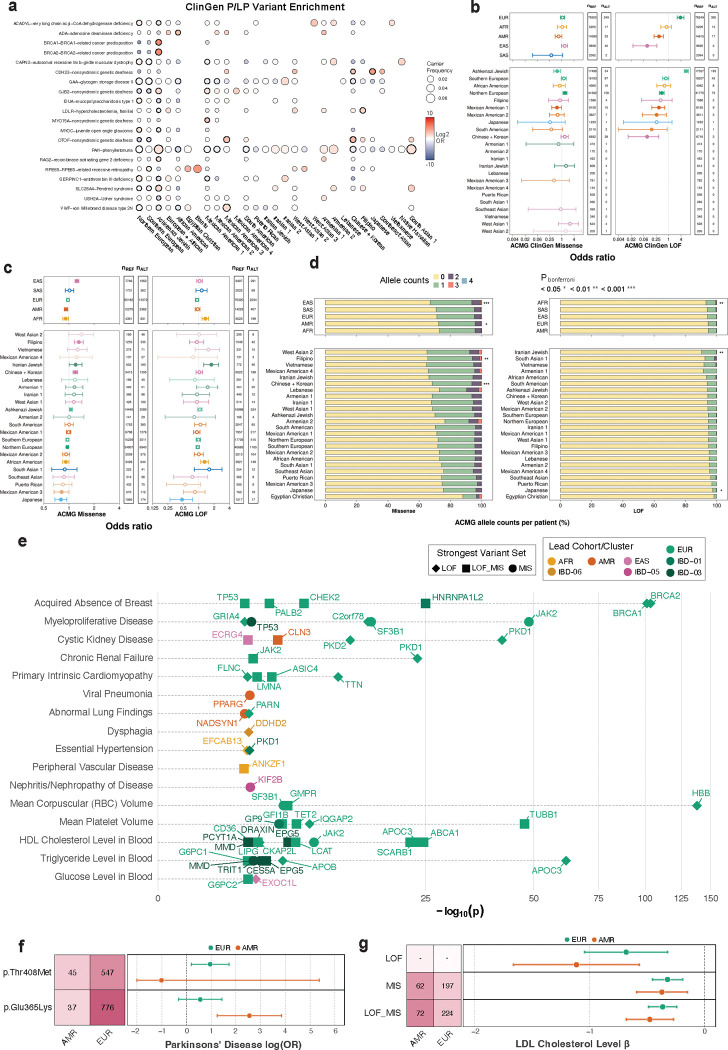
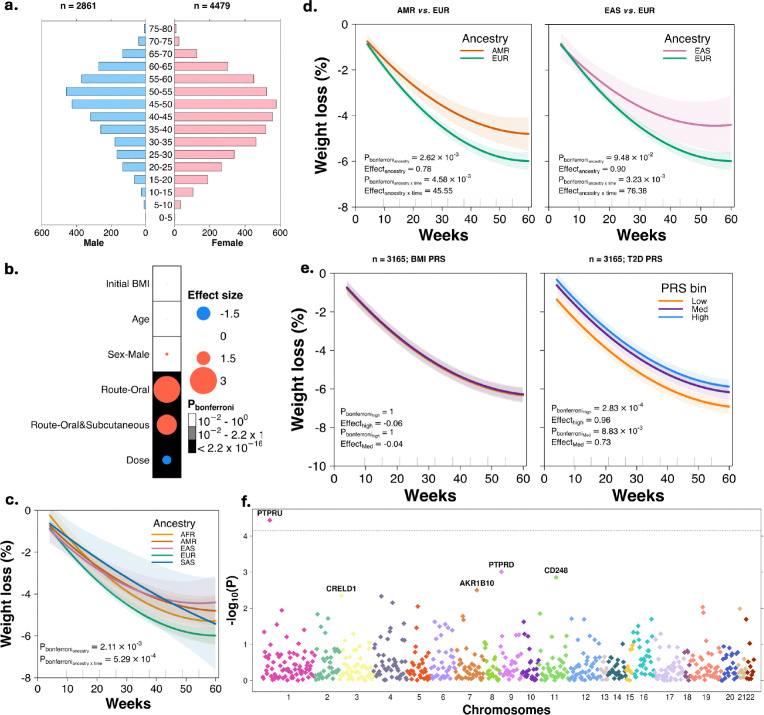
Coupling genetic profiling with electronic health records from hospital biobanks is a foundational resource for precision medicine. However, lack of ancestral heterogeneity limits discovery and generalizability. We leveraged the UCLA ATLAS Community Health Initiative, a diverse biobank with >35% non-European participants in a single health system, to inform disease prevalence and genetic risk across five continental and 36 fine-scale ancestry groups. Analyzing clinical and genetic data for 93,937 individuals, 61,797 with whole-exome sequencing (WES), we identified novel associations between genetic variants and phenotypes, including STARD7 with asthma risk in Mexican Americans and FN3K with intestinal disaccharidase deficiency across Europeans and Admixed Americans. Top decile polygenic scores (PGS) predicted patient status for many common diseases (40% of patients with Type 1 diabetes); an effect markedly diminished in non-Europeans. Exploring the distribution of ACMG ClinGen rare variants across populations demonstrated European bias in curated clinical variants. Mitigating this bias using computationally predicted deleterious variants, we identified new gene-disease associations, including EXOC1L and blood glucose level in East Asians. We identified PTPRU as a modulator of semaglutide's effects on weight loss, and additionally found variability across ancestries and a relationship with type-2-diabetes PGS. We provide an interactive web portal for accessing cross-ancestry associations at atlas-phewas.mednet.ucla.edu. Collectively, our findings support the value of ancestral diversity in advancing precision health across a broad spectrum of populations.
Conflict of interest statement
Competing Interests P.S is a consultant for 10X Genomics, Illumina, Foresight Diagnostics, Natera, and Twinstrand. P.C.B. sits on the scientific advisory boards of Sage Bionetworks, Intersect Diagnostics and BioSymetric. All other authors declare no conflict of interest.
Figures
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources