

Self-Contrastive Forward-Forward algorithm
- PMID: 40595637
- PMCID: PMC12217723
- DOI: 10.1038/s41467-025-61037-0
Self-Contrastive Forward-Forward algorithm
Abstract
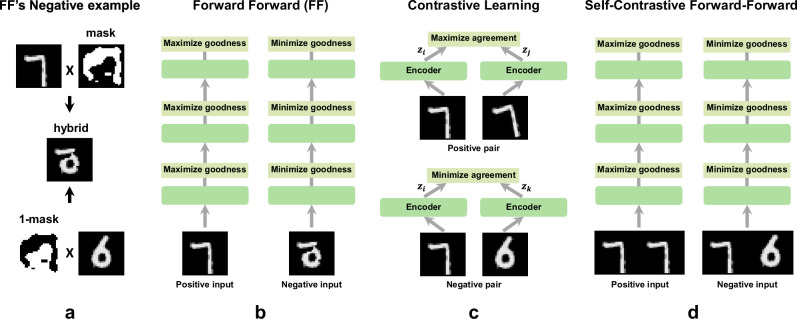
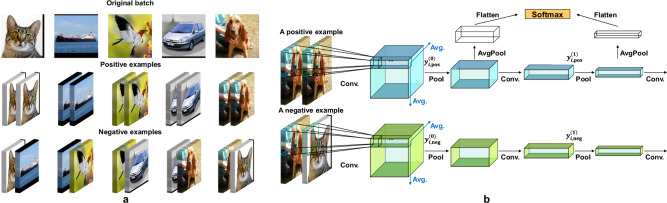
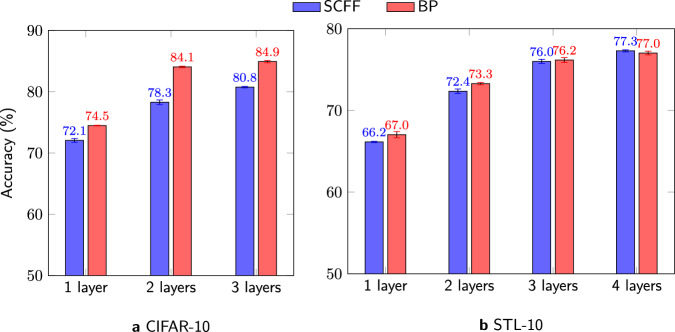
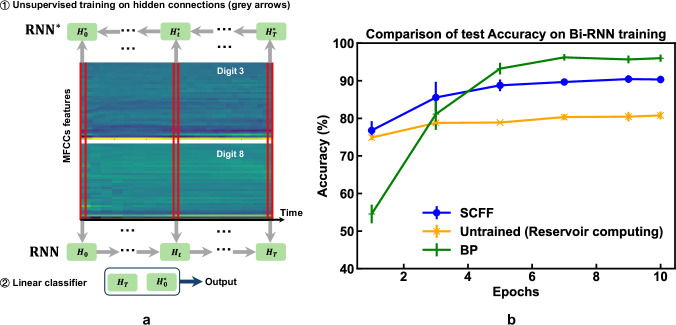
Agents that operate autonomously benefit from lifelong learning capabilities. However, compatible training algorithms must comply with the decentralized nature of these systems which imposes constraints on both the parameters counts and the computational resources. The Forward-Forward (FF) algorithm is one of these. FF relies only on feedforward operations, the same used for inference, for optimizing layer-wise objectives. This purely forward approach eliminates the need for transpose operations required in traditional backpropagation. Despite its potential, FF has failed to reach state-of-the-art performance on most standard benchmark tasks, in part due to unreliable negative data generation methods for unsupervised learning. In this work, we propose Self-Contrastive Forward-Forward (SCFF) algorithm, a competitive training method aimed at closing this performance gap. Inspired by standard self-supervised contrastive learning for vision tasks, SCFF generates positive and negative inputs applicable across various datasets. The method demonstrates superior performance compared to existing unsupervised local learning algorithms on several benchmark datasets, including MNIST, CIFAR-10, STL-10 and Tiny ImageNet. We extend FF's application to training recurrent neural networks, expanding its utility to sequential data tasks. These findings pave the way for high-accuracy, real-time learning on resource-constrained edge devices.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures
Similar articles
-
Leveraging a foundation model zoo for cell similarity search in oncological microscopy across devices.Front Oncol. 2025 Jun 18;15:1480384. doi: 10.3389/fonc.2025.1480384. eCollection 2025. Front Oncol. 2025. PMID: 40606969 Free PMC article.
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2021 Apr 19;4(4):CD011535. doi: 10.1002/14651858.CD011535.pub4. Cochrane Database Syst Rev. 2021. Update in: Cochrane Database Syst Rev. 2022 May 23;5:CD011535. doi: 10.1002/14651858.CD011535.pub5. PMID: 33871055 Free PMC article. Updated.
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
Self-Supervised Contrastive Learning for Medical Time Series: A Systematic Review.Sensors (Basel). 2023 Apr 23;23(9):4221. doi: 10.3390/s23094221. Sensors (Basel). 2023. PMID: 37177423 Free PMC article.
-
Diagnostic tests and algorithms used in the investigation of haematuria: systematic reviews and economic evaluation.Health Technol Assess. 2006 Jun;10(18):iii-iv, xi-259. doi: 10.3310/hta10180. Health Technol Assess. 2006. PMID: 16729917
References
-
- Nahavandi, D., Alizadehsani, R., Khosravi, A. & Acharya, U. R. Application of artificial intelligence in wearable devices: opportunities and challenges. Comput. Methods Prog. Biomed.213, 106541 (2022). - PubMed
-
- Cardinale, M. & Varley, M. C. Wearable training-monitoring technology: applications, challenges, and opportunities. Int. J. Sports Physiol. Perform.12, 2–55 (2017). - PubMed
-
- Shi, W., Cao, J., Zhang, Q., Li, Y. & Xu, L. Edge computing: vision and challenges. IEEE Internet Things J.3, 637–646 (2016).
-
- Khouas, A. R., Bouadjenek, M. R., Hacid, H. & Aryal, S. Training machine learning models at the edge: a survey. Preprint at https://arxiv.org/abs/2403.02619 (2024).
LinkOut - more resources
Full Text Sources
Miscellaneous
