

A publicly available benchmark for assessing large language models' ability to predict how humans balance self-interest and the interest of others
- PMID: 40595689
- PMCID: PMC12216366
- DOI: 10.1038/s41598-025-01715-7
A publicly available benchmark for assessing large language models' ability to predict how humans balance self-interest and the interest of others
Abstract
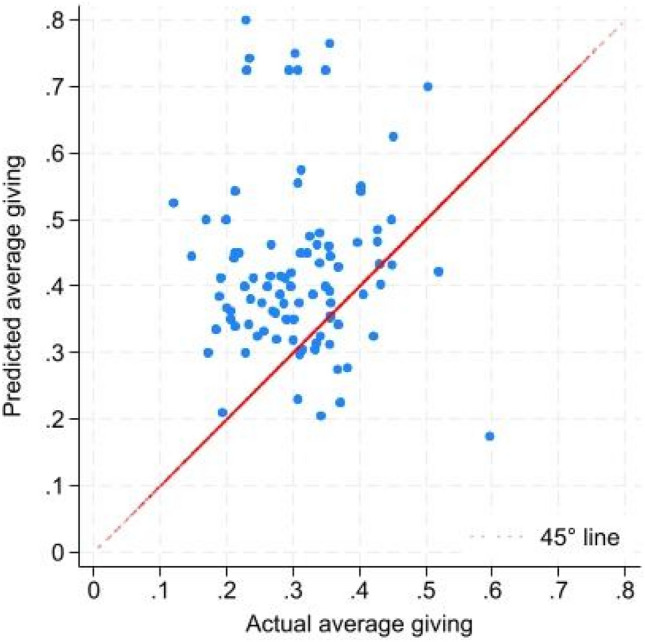
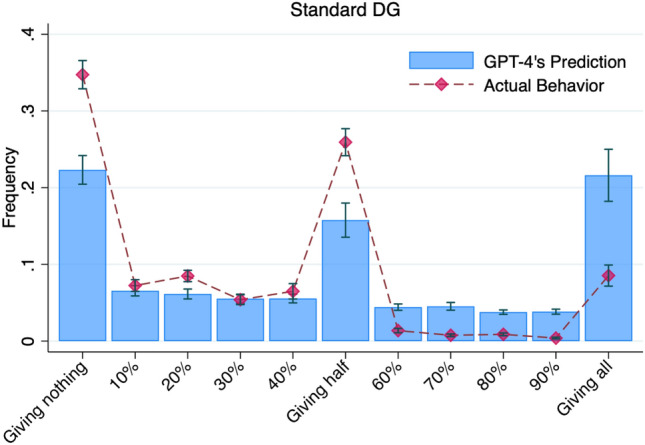
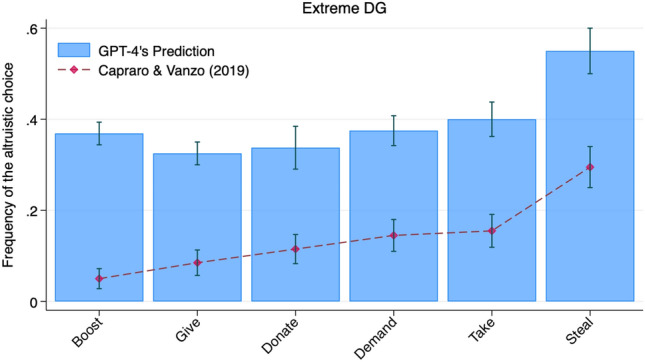
Large language models (LLMs) hold enormous potential to assist humans in decision-making processes, from everyday to high-stake scenarios. However, as many human decisions carry social implications, for LLMs to be reliable assistants a necessary prerequisite is that they are able to capture how humans balance self-interest and the interest of others. Here we introduce a novel, publicly available, benchmark to test LLM's ability to predict how humans balance monetary self-interest and the interest of others. This benchmark consists of 106 textual instructions from dictator games experiments conducted with human participants from 12 countries, alongside with a compendium of actual human behavior in each experiment. We investigate the ability of four advanced chatbots against this benchmark. We find that none of these chatbots meet the benchmark. In particular, only GPT-4 and GPT-4o (not Bard nor Bing) correctly capture qualitative behavioral patterns, identifying three major classes of behavior: self-interested, inequity-averse, and fully altruistic. Nonetheless, GPT-4 and GPT-4o consistently underestimate self-interest, while overestimating altruistic behavior. In sum, this article introduces a publicly available resource for testing the capacity of LLMs to estimate human other-regarding preferences in economic decisions and reveals an "optimistic bias" in current versions of GPT.
Keywords: Altruism; Dictator game; Economic games; Generative artificial intelligence; Human behavior.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures

Similar articles
-
The potential of Generative Pre-trained Transformer 4 (GPT-4) to analyse medical notes in three different languages: a retrospective model-evaluation study.Lancet Digit Health. 2025 Jan;7(1):e35-e43. doi: 10.1016/S2589-7500(24)00246-2. Lancet Digit Health. 2025. PMID: 39722251 Free PMC article.
-
The experience of adults who choose watchful waiting or active surveillance as an approach to medical treatment: a qualitative systematic review.JBI Database System Rev Implement Rep. 2016 Feb;14(2):174-255. doi: 10.11124/jbisrir-2016-2270. JBI Database System Rev Implement Rep. 2016. PMID: 27536798
-
Comparison of ChatGPT and Internet Research for Clinical Research and Decision-Making in Occupational Medicine: Randomized Controlled Trial.JMIR Form Res. 2025 May 20;9:e63857. doi: 10.2196/63857. JMIR Form Res. 2025. PMID: 40393042 Free PMC article. Clinical Trial.
-
Parents' and informal caregivers' views and experiences of communication about routine childhood vaccination: a synthesis of qualitative evidence.Cochrane Database Syst Rev. 2017 Feb 7;2(2):CD011787. doi: 10.1002/14651858.CD011787.pub2. Cochrane Database Syst Rev. 2017. PMID: 28169420 Free PMC article.
-
Quality assessment of large language models' output in maternal health.Sci Rep. 2025 Jul 2;15(1):22474. doi: 10.1038/s41598-025-03501-x. Sci Rep. 2025. PMID: 40593918 Free PMC article.
Cited by
-
Evaluating the ability of large Language models to predict human social decisions.Sci Rep. 2025 Sep 2;15(1):32290. doi: 10.1038/s41598-025-17188-7. Sci Rep. 2025. PMID: 40897780 Free PMC article.
References
-
- Epstein, Z. et al. Art and the science of generative AI. Science380, 1110–1111 (2023). - PubMed
-
- Xing, F. Z., Cambria, E. & Welsch, R. E. Natural language based financial forecasting: A survey. Artif. Intell. Rev.50, 49–73 (2018).
-
- Lee, P., Bubeck, S. & Petro, J. Benefits, limits, and risks of GPT-4 as an AI chatbot for medicine. N. Engl. J. Med.388, 1233–1239 (2023). - PubMed
-
- Noy, S. & Zhang, W. Experimental evidence on the productivity effects of generative artificial intelligence. Science381, 187–192 (2023). - PubMed
-
- Brynjolfsson, E., Li, D. & Raymond, L. R. Generative AI at work. Natl. Bur. Econ. Res. (2023).
MeSH terms
LinkOut - more resources
Full Text Sources
