

Large language models provide discordant information compared to ophthalmology guidelines
- PMID: 40596239
- PMCID: PMC12218404
- DOI: 10.1038/s41598-025-06404-z
Large language models provide discordant information compared to ophthalmology guidelines
Abstract
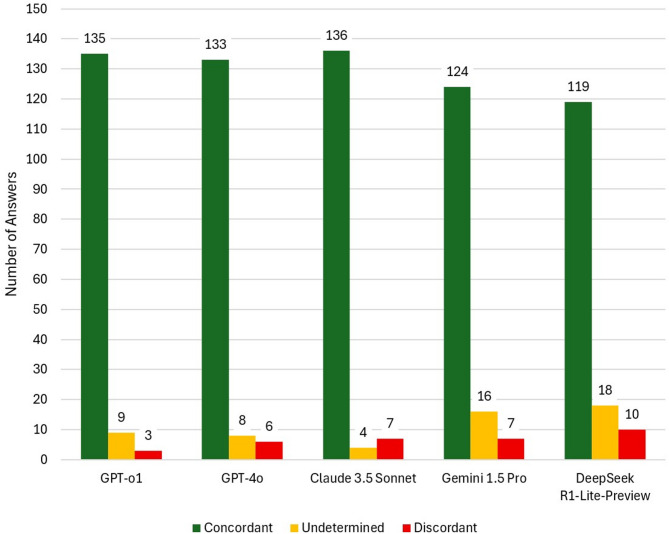
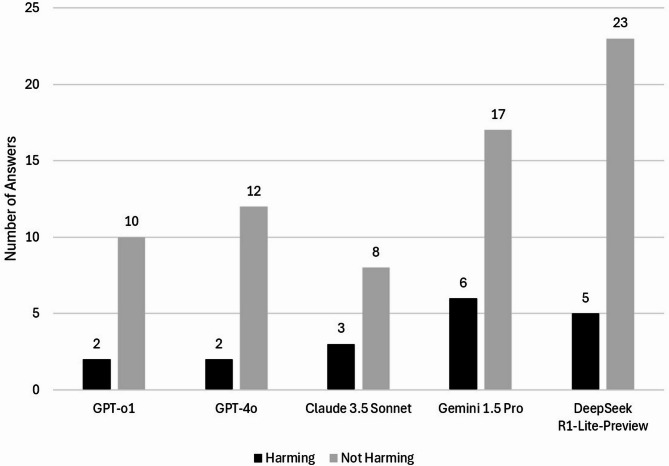
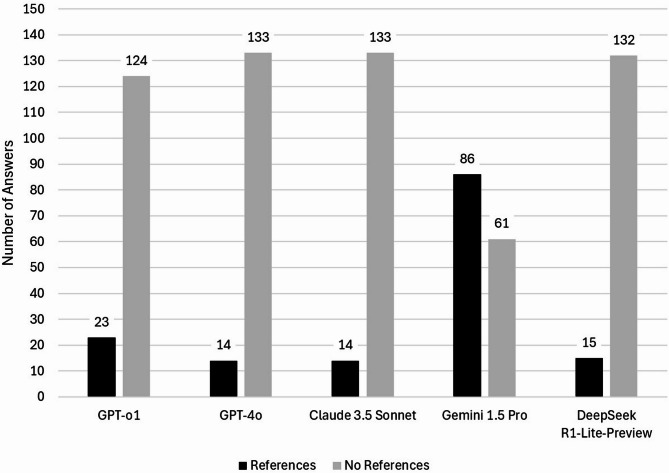
To evaluate the agreement of LLMs with the Preferred Practice Patterns® (PPP) guidelines developed by the American Academy of Ophthalmology (AAO). Open questions based on the AAO PPP were submitted to five LLMs: GPT-o1 and GPT-4o by OpenAI, Claude 3.5 Sonnet by Anthropic, Gemini 1.5 Pro by Google, and DeepSeek-R1-Lite-Preview. Questions were classified as "open" or "confirmatory with positive/negative ground-truth answer". Three blinded investigators classified responses as "concordant", "undetermined", or "discordant" compared to the AAO PPP. Undetermined and discordant answers were analyzed to assess harming potential for patients. Responses referencing peer-reviewed articles were reported. In total, 147 questions were submitted to the LLMs. Concordant answers were 135 (91.8%) for GPT-o1, 133 (90.5%) for GPT-4o, 136 (92.5%) for Claude 3.5 Sonnet, 124 (84.4%) for Gemini 1.5 Pro, and 119 (81.0%) for DeepSeek-R1-Lite-Preview (P = 0.006). The highest number of harmful answers was reported for Gemini 1.5 Pro (n = 6, 4.1%), followed by DeepSeek-R1-Lite-Preview (n = 5, 3.4%). Gemini 1.5 Pro was the most transparent model (86 references, 58.5%). Other LLMs referenced papers in 9.5-15.6% of their responses. LLMs can provide discordant answers compared to ophthalmology guidelines, potentially harming patients by delaying diagnosis or recommending suboptimal treatments.
Keywords: AAO; American Academy of Ophthalmology; Artificial intelligence; Guidelines; Large language model; Preferred practice patterns.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests. Ethical approval: The research did not involve humans or animals.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
