

Darling (v2.0): Mining disease-related databases for the detection of biomedical entity associations
- PMID: 40599243
- PMCID: PMC12212154
- DOI: 10.1016/j.csbj.2025.06.025
Darling (v2.0): Mining disease-related databases for the detection of biomedical entity associations
Abstract
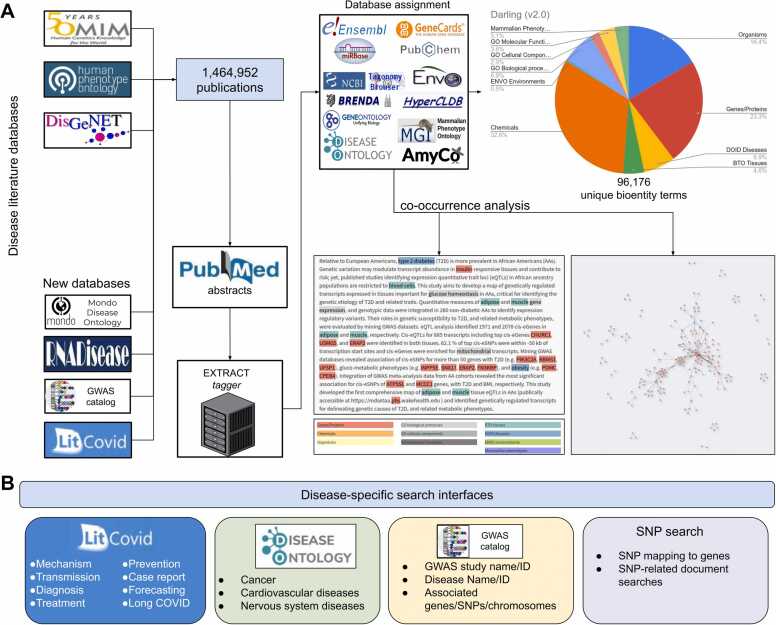
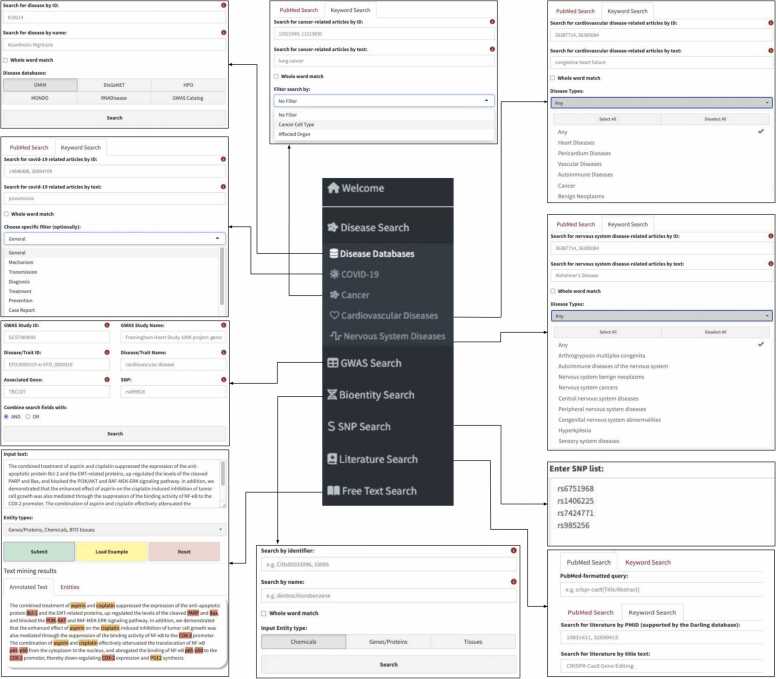
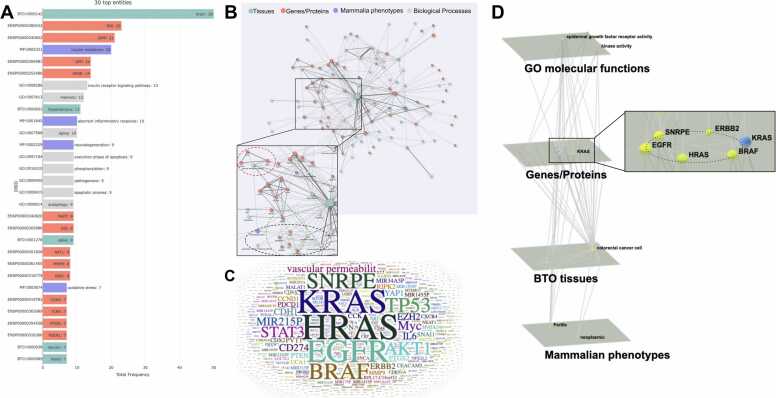
Darling is a web application that employs literature mining to detect disease-related biomedical entity associations. Darling can detect sentence-based cooccurrences of biomedical entities such as genes, proteins, chemicals, functions, tissues, diseases, environments, and phenotypes from biomedical literature found in six disease-centric databases. In this version, we deploy additional query channels focusing on COVID-19, GWAS studies, cardiovascular, neurodegenerative, and cancer diseases. Compared to its predecessor, users now have extended query options including searches with PubMed identifiers, disease records, entity names, titles, single nucleotide polymorphisms, or the Entrez syntax. Furthermore, after applying named entity recognition, one can retrieve and mine the relevant literature from recognized terms for a free input text. Term associations are captured in customizable networks which can be further filtered by either term or co-occurrence frequency and visualized in 2D as weighted graphs or in 3D as multi-layered networks. The fetched terms are organized in searchable tables and clustered annotated documents. The reported genes can be further analyzed for functional enrichment using external applications called from within Darling. The Darling databases, including terms and their associations, are updated annually. Darling is available at: https://www.darling-miner.org/.
Keywords: Co-occurrence analysis; Literature mining; Named entity recognition; Network analysis; Text mining.
© 2025 The Authors.
Conflict of interest statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures

Similar articles
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
Education support services for improving school engagement and academic performance of children and adolescents with a chronic health condition.Cochrane Database Syst Rev. 2023 Feb 8;2(2):CD011538. doi: 10.1002/14651858.CD011538.pub2. Cochrane Database Syst Rev. 2023. PMID: 36752365 Free PMC article.
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2021 Apr 19;4(4):CD011535. doi: 10.1002/14651858.CD011535.pub4. Cochrane Database Syst Rev. 2021. Update in: Cochrane Database Syst Rev. 2022 May 23;5:CD011535. doi: 10.1002/14651858.CD011535.pub5. PMID: 33871055 Free PMC article. Updated.
-
Drugs for preventing postoperative nausea and vomiting in adults after general anaesthesia: a network meta-analysis.Cochrane Database Syst Rev. 2020 Oct 19;10(10):CD012859. doi: 10.1002/14651858.CD012859.pub2. Cochrane Database Syst Rev. 2020. PMID: 33075160 Free PMC article.
-
Prognosis of adults and children following a first unprovoked seizure.Cochrane Database Syst Rev. 2023 Jan 23;1(1):CD013847. doi: 10.1002/14651858.CD013847.pub2. Cochrane Database Syst Rev. 2023. PMID: 36688481 Free PMC article.
References
-
- Cheerkoot-Jalim S., Khedo K.K. A systematic review of text mining approaches applied to various application areas in the biomedical domain. JKM. 2021;25:642–668. doi: 10.1108/JKM-09-2019-0524. - DOI
LinkOut - more resources
Full Text Sources