

The analysis of deep reinforcement learning for dynamic graphical games under artificial intelligence
- PMID: 40604017
- PMCID: PMC12223108
- DOI: 10.1038/s41598-025-05192-w
The analysis of deep reinforcement learning for dynamic graphical games under artificial intelligence
Abstract
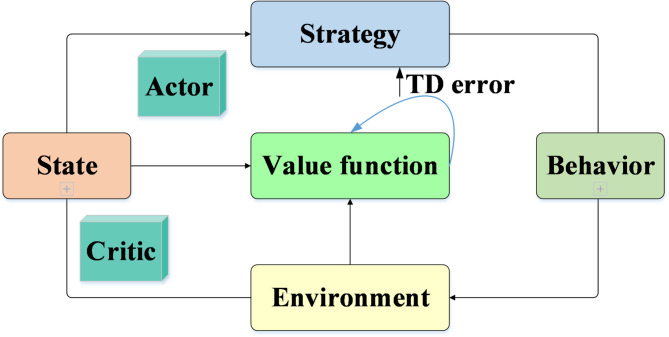
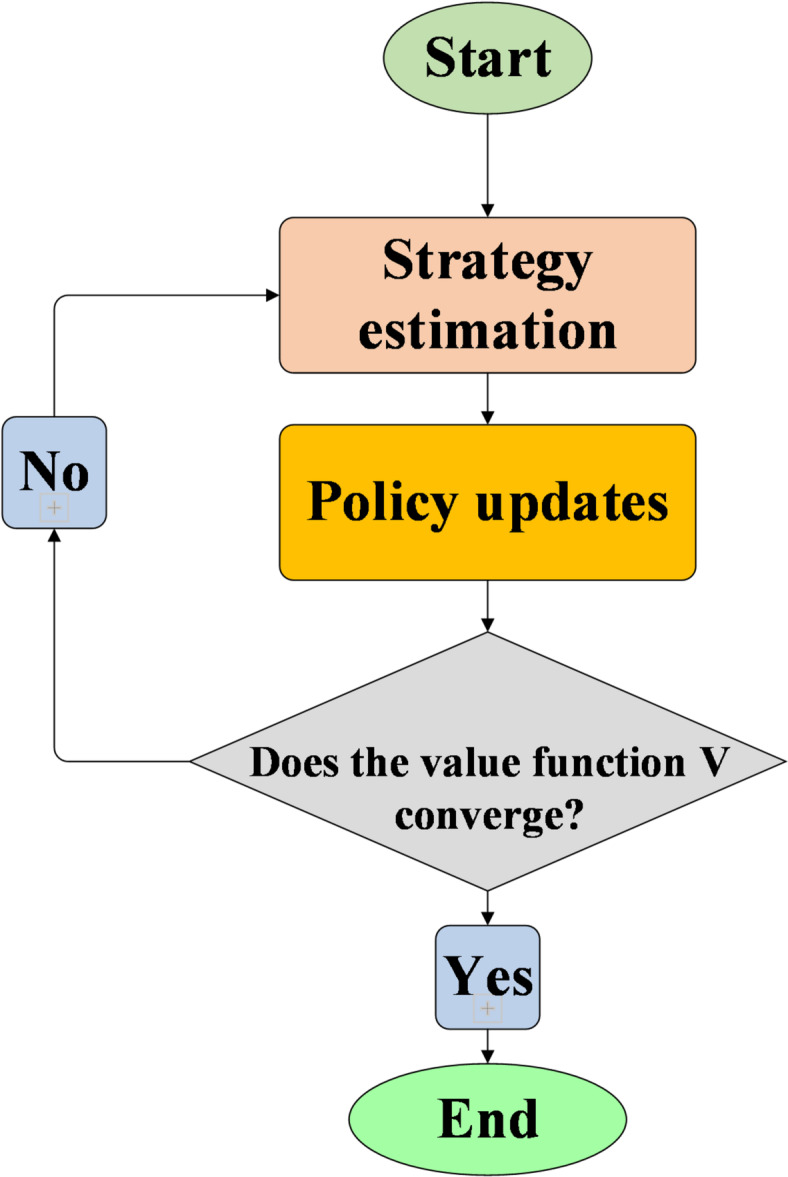
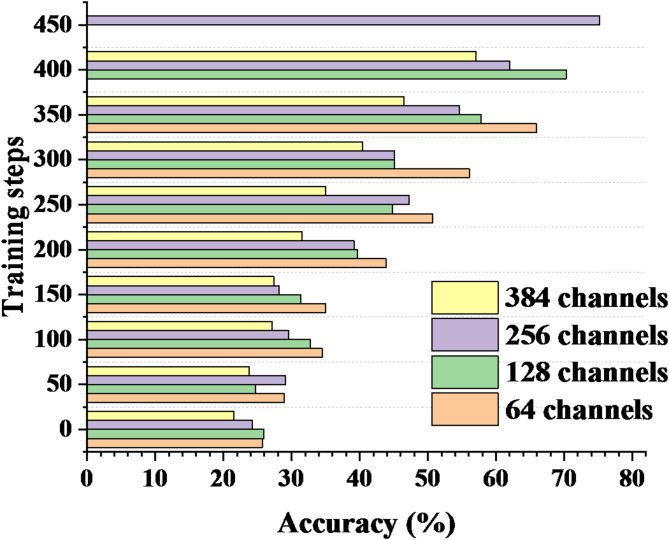
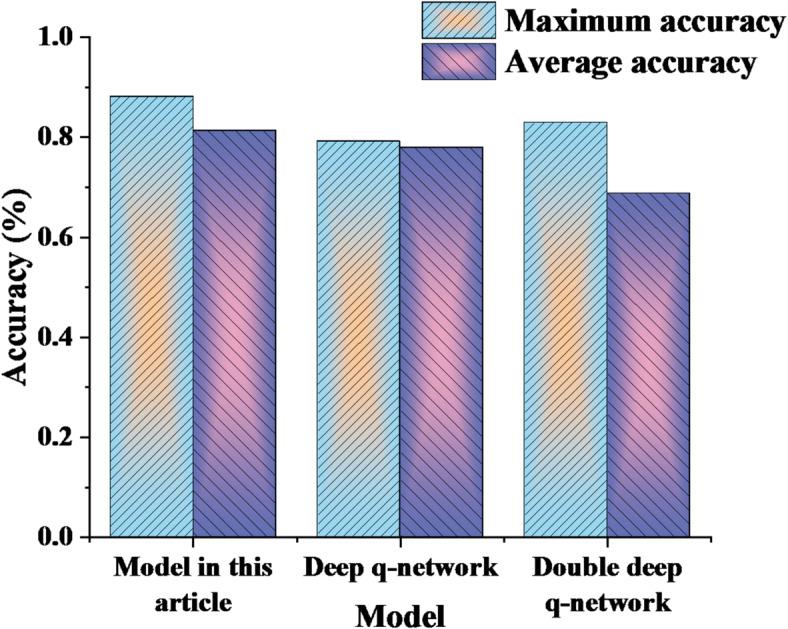
This paper explores the use of deep reinforcement learning (DRL) to enable autonomous decision-making and strategy optimization in dynamic graphical games. The proposed approach consists of several key components. First, local performance metrics are defined to reduce computational complexity and minimize information exchange among agents. Second, an online iterative algorithm is developed, leveraging Deep Neural Networks to solve dynamic graphical games with input constraints. This algorithm employs an Actor-Critic framework, where the Actor network learns optimal policies and the Critic network estimates value functions. Third, a distributed policy iteration mechanism allows each intelligent agent to make decisions based solely on local information. Finally, experimental results validate the effectiveness of the proposed method. The findings show that the DRL-based online iterative algorithm significantly improves decision accuracy and convergence speed, reduces computational complexity, and demonstrates strong performance and scalability in addressing optimal control problems in dynamic graphical intelligent games.
Keywords: Actor-critic; Artificial intelligence; Deep reinforcement learning; Dynamic graphical games; Online iterative algorithm.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests. Ethics approval: The studies involving human participants were reviewed and approved by School of Education, Guangzhou University Ethics Committee (Approval Number: 2022.02510032). The participants provided their written informed consent to participate in this study. All methods were performed in accordance with relevant guidelines and regulations.
Figures

Similar articles
-
Optimal Evolution Strategy for Continuous Strategy Games on Complex Networks via Reinforcement Learning.IEEE Trans Neural Netw Learn Syst. 2025 Jul;36(7):12827-12839. doi: 10.1109/TNNLS.2024.3453385. IEEE Trans Neural Netw Learn Syst. 2025. PMID: 39302801
-
Enterprise fission path optimization and dynamic capability construction based on the soft actor-critic algorithm.Sci Rep. 2025 Jul 1;15(1):20942. doi: 10.1038/s41598-025-06180-w. Sci Rep. 2025. PMID: 40594679 Free PMC article.
-
GAPO: A Graph Attention-Based Reinforcement Learning Algorithm for Congestion-Aware Task Offloading in Multi-Hop Vehicular Edge Computing.Sensors (Basel). 2025 Aug 6;25(15):4838. doi: 10.3390/s25154838. Sensors (Basel). 2025. PMID: 40808002 Free PMC article.
-
Home treatment for mental health problems: a systematic review.Health Technol Assess. 2001;5(15):1-139. doi: 10.3310/hta5150. Health Technol Assess. 2001. PMID: 11532236
-
Assessing the comparative effects of interventions in COPD: a tutorial on network meta-analysis for clinicians.Respir Res. 2024 Dec 21;25(1):438. doi: 10.1186/s12931-024-03056-x. Respir Res. 2024. PMID: 39709425 Free PMC article. Review.
References
-
- Wang, L. et al. Deep reinforcement learning based dynamic trajectory control for UAV-assisted mobile edge computing. IEEE Trans. Mob. Comput.21(10), 3536–3550 (2021).
-
- Oroojlooyjadid, A. et al. A deep q-network for the beer game: Deep reinforcement learning for inventory optimization. Manuf. Serv. Oper. Manag.24(1), 285–304 (2022).
-
- Xie, Y. et al. Virtualized network function forwarding graph placing in SDN and NFV-enabled IoT networks: A graph neural network assisted deep reinforcement learning method. IEEE Trans. Netw. Serv. Manag.19(1), 524–537 (2021).
-
- Du, X. et al. Multi-agent reinforcement learning for dynamic resource management in 6G in-X subnetworks. IEEE Trans. Wirel. Commun.22(3), 1900–1914 (2022).
-
- Song, W. et al. Flexible job-shop scheduling via graph neural network and deep reinforcement learning. IEEE Trans. Ind. Inf.19(2), 1600–1610 (2022).
LinkOut - more resources
Full Text Sources
