

A foundation model to predict and capture human cognition
- PMID: 40604288
- PMCID: PMC12390832
- DOI: 10.1038/s41586-025-09215-4
A foundation model to predict and capture human cognition
Abstract
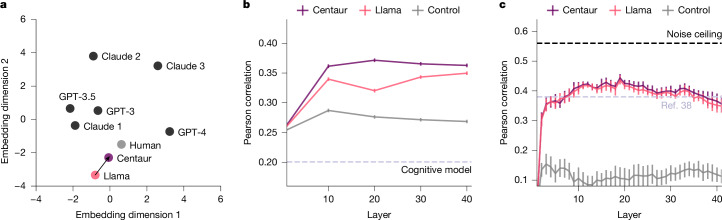
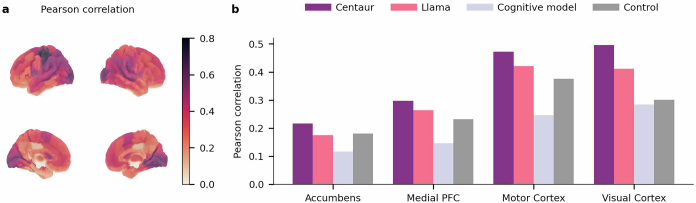
Establishing a unified theory of cognition has been an important goal in psychology1,2. A first step towards such a theory is to create a computational model that can predict human behaviour in a wide range of settings. Here we introduce Centaur, a computational model that can predict and simulate human behaviour in any experiment expressible in natural language. We derived Centaur by fine-tuning a state-of-the-art language model on a large-scale dataset called Psych-101. Psych-101 has an unprecedented scale, covering trial-by-trial data from more than 60,000 participants performing in excess of 10,000,000 choices in 160 experiments. Centaur not only captures the behaviour of held-out participants better than existing cognitive models, but it also generalizes to previously unseen cover stories, structural task modifications and entirely new domains. Furthermore, the model's internal representations become more aligned with human neural activity after fine-tuning. Taken together, our results demonstrate that it is possible to discover computational models that capture human behaviour across a wide range of domains. We believe that such models provide tremendous potential for guiding the development of cognitive theories, and we present a case study to demonstrate this.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: F.J.T. consults for Immunai, CytoReason, Cellarity, BioTuring and Genbio.AI, and has an ownership interest in Dermagnostix and Cellarity. The remaining authors declare no competing interests.
Figures










References
-
- Anderson, J. The Architecture of Cognition (Harvard Univ. Press, 1983).
-
- Newell, A. Unified Theories of Cognition (Harvard Univ. Press, 1990).
-
- Lake, B. M., Ullman, T. D., Tenenbaum, J. B. & Gershman, S. J. Building machines that learn and think like people. Behav. Brain Sci.40, e253 (2017). - PubMed
-
- Lake, B. M., Salakhutdinov, R. & Tenenbaum, J. B. Human-level concept learning through probabilistic program induction. Science350, 1332–1338 (2015). - PubMed
-
- Goddu, M. K. & Gopnik, A. The development of human causal learning and reasoning. Nat. Rev. Psychol.10.1038/s44159-024-00300-5 (2024).
MeSH terms
LinkOut - more resources
Full Text Sources
