

Comparative Performance of Medical Students, ChatGPT-3.5 and ChatGPT-4.0 in Answering Questions From a Brazilian National Medical Exam: Cross-Sectional Questionnaire Study
- PMID: 40607498
- PMCID: PMC12223693
- DOI: 10.2196/66552
Comparative Performance of Medical Students, ChatGPT-3.5 and ChatGPT-4.0 in Answering Questions From a Brazilian National Medical Exam: Cross-Sectional Questionnaire Study
Abstract
Background: Artificial intelligence has advanced significantly in various fields, including medicine, where tools like ChatGPT (GPT) have demonstrated remarkable capabilities in interpreting and synthesizing complex medical data. Since its launch in 2019, GPT has evolved, with version 4.0 offering enhanced processing power, image interpretation, and more accurate responses. In medicine, GPT has been used for diagnosis, research, and education, achieving significant milestones like passing the United States Medical Licensing Examination. Recent studies show that GPT 4.0 outperforms earlier versions and even medical students on medical exams.
Objective: This study aimed to evaluate and compare the performance of GPT versions 3.5 and 4.0 on Brazilian Progress Tests (PT) from 2021 to 2023, analyzing their accuracy compared to medical students.
Methods: A cross-sectional observational study was conducted using 333 multiple-choice questions from the PT, excluding questions with images and those nullified or repeated. All questions were presented sequentially without modification to their structure. The performance of GPT versions was compared using statistical methods and medical students' scores were included for context.
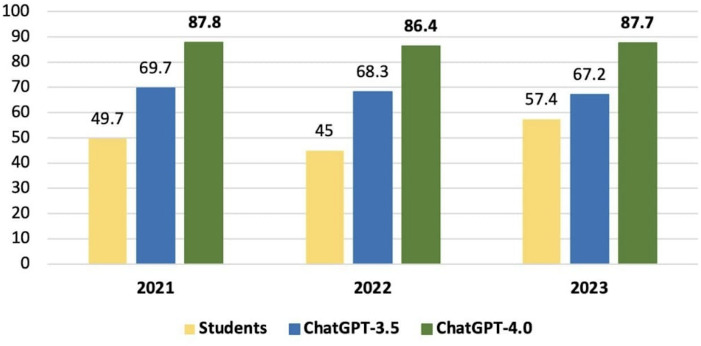
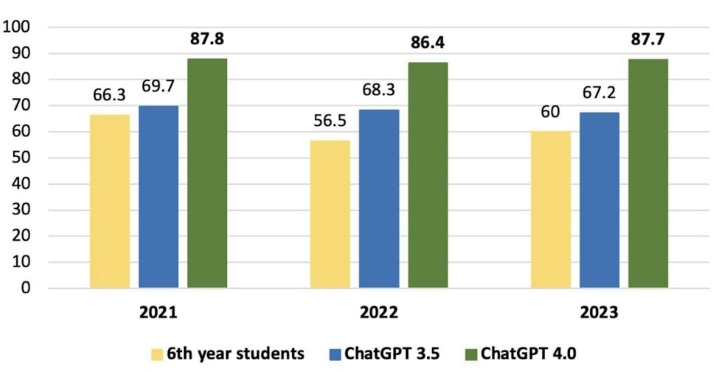
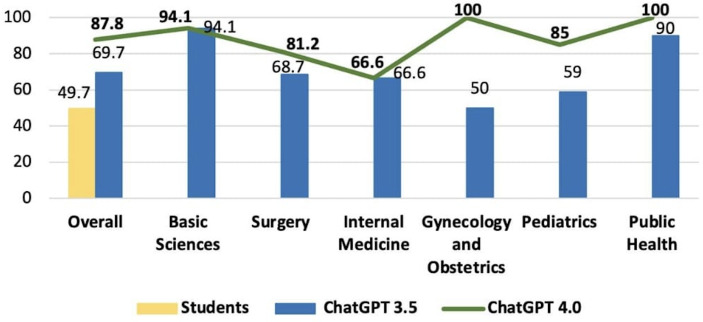
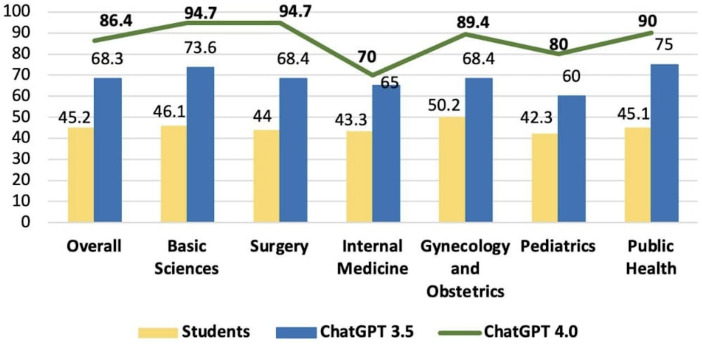
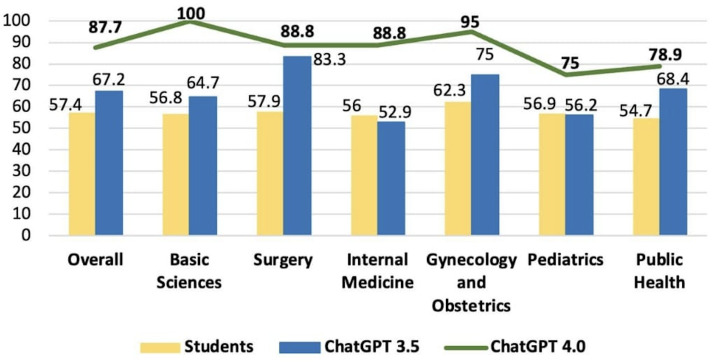
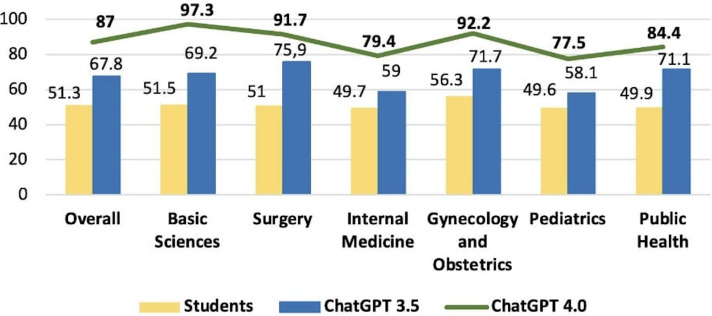
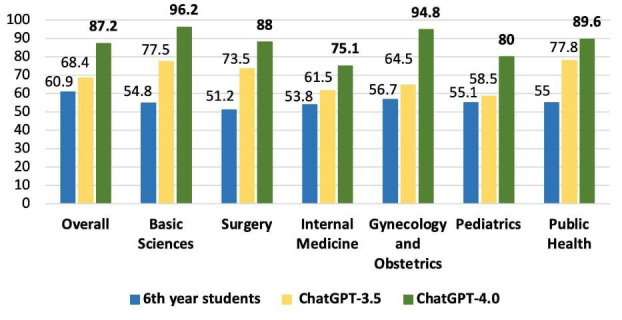
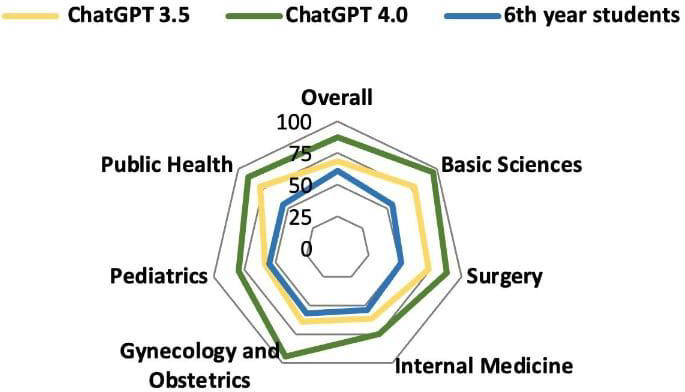
Results: There was a statistically significant difference in total performance scores across the 2021, 2022, and 2023 exams between GPT-3.5 and GPT-4.0 (P=.03). However, this significance did not remain after Bonferroni correction. On average, GPT v3.5 scored 68.4%, whereas v4.0 achieved 87.2%, reflecting an absolute improvement of 18.8% and a relative increase of 27.4% in accuracy. When broken down by subject, the average scores for GPT-3.5 and GPT-4.0, respectively, were as follows: surgery (73.5% vs 88.0%, P=.03), basic sciences (77.5% vs 96.2%, P=.004), internal medicine (61.5% vs 75.1%, P=.14), gynecology and obstetrics (64.5% vs 94.8%, P=.002), pediatrics (58.5% vs 80.0%, P=.02), and public health (77.8% vs 89.6%, P=.02). After Bonferroni correction, only basic sciences and gynecology and obstetrics retained statistically significant differences.
Conclusions: GPT-4.0 demonstrates superior accuracy compared to its predecessor in answering medical questions on the PT. These results are similar to other studies, indicating that we are approaching a new revolution in medicine.
Keywords: AI; ChatGPT; academic performance; accuracy; artificial intelligence; biomedical technology; ethics; exam questions; intelligent systems; medical data; medical education; medical ethics; medical exam; medical school; medical student; observational study.
© Mateus Rodrigues Alessi, Heitor Augusto Gomes, Gabriel Oliveira, Matheus Lopes de Castro, Fabiano Grenteski, Leticia Miyashiro, Camila do Valle, Leticia Tozzini Tavares da Silva, Cristina Okamoto. Originally published in JMIR AI (https://ai.jmir.org).
Conflict of interest statement
Figures
Similar articles
-
Unveiling GPT-4V's hidden challenges behind high accuracy on USMLE questions: Observational Study.J Med Internet Res. 2025 Feb 7;27:e65146. doi: 10.2196/65146. J Med Internet Res. 2025. PMID: 39919278 Free PMC article.
-
Performance of ChatGPT Across Different Versions in Medical Licensing Examinations Worldwide: Systematic Review and Meta-Analysis.J Med Internet Res. 2024 Jul 25;26:e60807. doi: 10.2196/60807. J Med Internet Res. 2024. PMID: 39052324 Free PMC article.
-
Evaluating Bard Gemini Pro and GPT-4 Vision Against Student Performance in Medical Visual Question Answering: Comparative Case Study.JMIR Form Res. 2024 Dec 17;8:e57592. doi: 10.2196/57592. JMIR Form Res. 2024. PMID: 39714199 Free PMC article.
-
Performance of ChatGPT-3.5 and GPT-4 in national licensing examinations for medicine, pharmacy, dentistry, and nursing: a systematic review and meta-analysis.BMC Med Educ. 2024 Sep 16;24(1):1013. doi: 10.1186/s12909-024-05944-8. BMC Med Educ. 2024. PMID: 39285377 Free PMC article.
-
Comparative performance of ChatGPT, Gemini, and final-year emergency medicine clerkship students in answering multiple-choice questions: implications for the use of AI in medical education.Int J Emerg Med. 2025 Aug 7;18(1):146. doi: 10.1186/s12245-025-00949-6. Int J Emerg Med. 2025. PMID: 40775272 Free PMC article.
References
-
- ChatGPT 2024. [28-07-2024]. https://chatgpt.com URL. Accessed.
LinkOut - more resources
Full Text Sources
