

This is a preprint.
GAME: Genomic API for Model Evaluation
- PMID: 40672207
- PMCID: PMC12265512
- DOI: 10.1101/2025.07.04.663250
GAME: Genomic API for Model Evaluation
Abstract
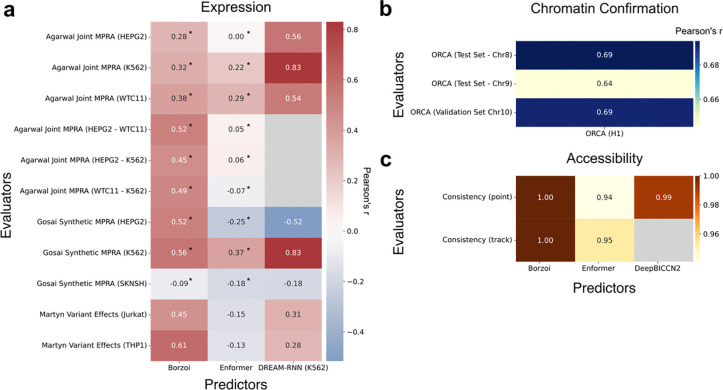
The rapid expansion of genomics datasets and the application of machine learning has produced sequence-to-activity genomics models with ever-expanding capabilities. However, benchmarking these models on practical applications has been challenging because individual projects evaluate their models in ad hoc ways, and there is substantial heterogeneity of both model architectures and benchmarking tasks. To address this challenge, we have created GAME, a system for large-scale, community-led standardized model benchmarking on user-defined evaluation tasks. We borrow concepts from the Application Programming Interface (API) paradigm to allow for seamless communication between pre-trained models and benchmarking tasks, ensuring consistent evaluation protocols. Because all models and benchmarks are inherently compatible in this framework, the continual addition of new models and new benchmarks is easy. We also developed a Matcher module powered by a large language model (LLM) to automate ambiguous task alignment between benchmarks and models. Containerization of these modules enhances reproducibility and facilitates the deployment of models and benchmarks across computing platforms. By focusing on predicting underlying biochemical phenomena (e.g. gene expression, open chromatin, DNA binding), we ensure that tasks remain technology-independent. We provide examples of benchmarks and models implementing this framework, and anticipate that the community will contribute their own, leading to an ever-expanding and evolving set of models and evaluation tasks. This resource will accelerate genomics research by illuminating the best models for a given task, motivating novel functional genomic benchmarks, and providing a more nuanced understanding of model abilities.
Conflict of interest statement
Competing Interests V.A. is an employee of Sanofi. A.L. is an employee of Genentech, inc. The remaining authors declare no competing interests.
Figures

References
-
- Guerrini M. M., Oguchi A., Suzuki A. & Murakawa Y. Cap analysis of gene expression (CAGE) and noncoding regulatory elements. Semin Immunopathol 44, 127–136 (2022). - PubMed
-
- Tang Z., Toneyan S. & Koo P. K. Current approaches to genomic deep learning struggle to fully capture human genetic variation. Nat Genet 55, 2021–2022 (2023). - PubMed
-
- Sasse A. et al. Benchmarking of deep neural networks for predicting personal gene expression from DNA sequence highlights shortcomings. Nat Genet 55, 2060–2064 (2023). - PubMed
-
- robson eyes s. & Ioannidis N. M. GUANinE v1.0: Benchmark Datasets for Genomic AI Sequence-to-Function Models. bioRxiv 2023.10.12.562113 (2024) doi: 10.1101/2023.10.12.562113. - DOI
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources