

Multicriteria Optimization of Language Models for Heart Failure With Preserved Ejection Fraction Symptom Detection in Spanish Electronic Health Records: Comparative Modeling Study
- PMID: 40674251
- PMCID: PMC12288768
- DOI: 10.2196/76433
Multicriteria Optimization of Language Models for Heart Failure With Preserved Ejection Fraction Symptom Detection in Spanish Electronic Health Records: Comparative Modeling Study
Abstract
Background: Heart failure with preserved ejection fraction (HFpEF) is a major clinical manifestation of cardiac amyloidosis, a condition frequently underdiagnosed due to its nonspecific symptomatology. Electronic health records (EHRs) offer a promising avenue for supporting early symptom detection through natural language processing. However, identifying relevant clinical cues within unstructured narratives, particularly in Spanish, remains a significant challenge due to the scarcity of annotated corpora and domain-specific models. This study proposes and evaluates a Transformer-based natural language processing framework for automated detection of HFpEF-related symptoms in Spanish EHRs.
Objective: The aim of this study is to assess the feasibility of leveraging unstructured clinical narratives to support early identification of heart failure phenotypes indicative of cardiac amyloidosis. It also examines how domain-specific language models and clinically guided optimization strategies can improve the reliability, sensitivity, and generalizability of symptom detection in real-world EHRs.
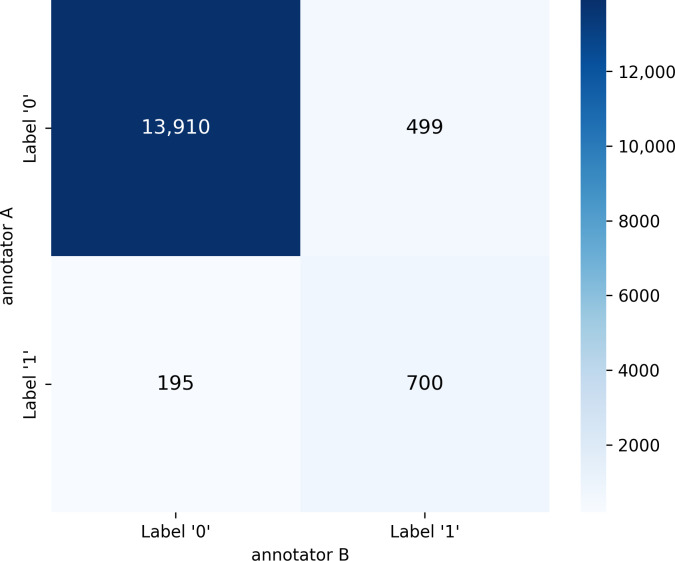
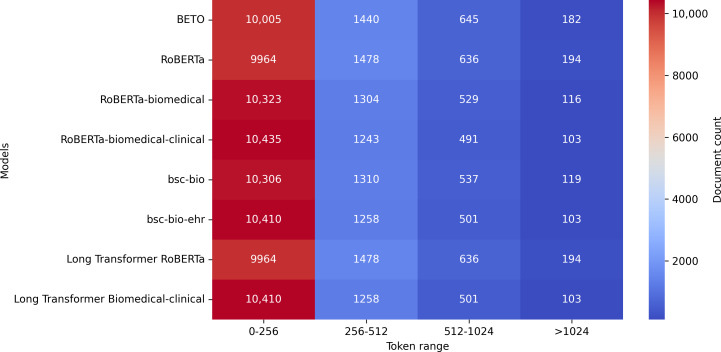
Methods: A novel corpus of 15,304 Spanish clinical documents was manually annotated and validated by cardiology experts. The corpus was derived from the records of 262 patients (173 with suspected cardiac amyloidosis and 89 without). In total, 8 Transformer-based language models were evaluated, including general-purpose models, biomedical-specialized variants, and Longformers. Three clinically motivated optimization strategies were implemented to align models' behavior with different diagnostic priorities: maximizing area under the curve (AUC) to enhance overall discrimination, optimizing F1-score to balance sensitivity and precision, and prioritizing sensitivity to minimize false negatives. These strategies were independently applied during the fine-tuning of the models to assess their impact on performance under different clinical constraints. To ensure robust evaluation, testing was conducted on a dataset composed exclusively of previously unseen patients, allowing performance to be assessed under realistic and generalizable conditions.
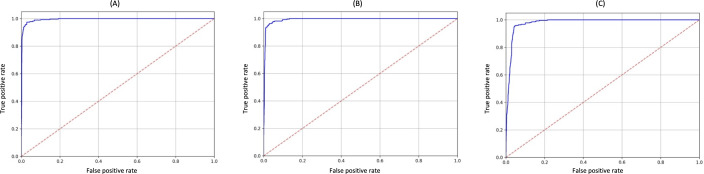
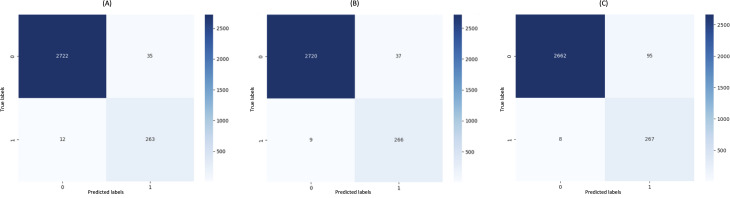
Results: All models achieved high performance, with AUC values above 0.940. The best-performing model, Longformer Biomedical-clinical, reached an AUC of 0.987, F1-score of 0.985, sensitivity of 0.987, and specificity of 0.987 on the test dataset. Models optimized for sensitivity reduced the false-negative rate to under 3%, a key threshold for clinical safety. Comparative analyses confirmed that domain-adapted, long-sequence models are better suited for the semantic and structural complexity of Spanish clinical texts than general-purpose models.
Conclusions: Transformer-based models can reliably detect HFpEF-related symptoms from Spanish EHRs, even in the presence of class imbalance and substantial linguistic complexity. The results show that combining domain-specific pretraining with long-context modeling architectures and clinically aligned optimization strategies leads to substantial gains in classification performance, particularly in sensitivity. These models not only achieve high accuracy and generalization on unseen patients but also demonstrate robustness in handling the semantic nuances and narrative structure of real-world clinical documentation. These findings support the potential deployment of Transformer-based systems as effective screening tools to prioritize patients at risk for cardiac amyloidosis in Spanish-speaking health care settings.
Keywords: clinical language models; early diagnosis support; manual corpus annotation; natural language processing; symptom extraction; transformer.
© Jacinto Mata, Victoria Pachón, Ana Manovel, Manuel J Maña, Manuel de la Villa. Originally published in the Journal of Medical Internet Research (https://www.jmir.org).
Conflict of interest statement
Figures
Similar articles
-
Comparison of Two Modern Survival Prediction Tools, SORG-MLA and METSSS, in Patients With Symptomatic Long-bone Metastases Who Underwent Local Treatment With Surgery Followed by Radiotherapy and With Radiotherapy Alone.Clin Orthop Relat Res. 2024 Dec 1;482(12):2193-2208. doi: 10.1097/CORR.0000000000003185. Epub 2024 Jul 23. Clin Orthop Relat Res. 2024. PMID: 39051924
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
Automated devices for identifying peripheral arterial disease in people with leg ulceration: an evidence synthesis and cost-effectiveness analysis.Health Technol Assess. 2024 Aug;28(37):1-158. doi: 10.3310/TWCG3912. Health Technol Assess. 2024. PMID: 39186036 Free PMC article.
-
Sexual Harassment and Prevention Training.2024 Mar 29. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. 2024 Mar 29. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. PMID: 36508513 Free Books & Documents.
-
[Volume and health outcomes: evidence from systematic reviews and from evaluation of Italian hospital data].Epidemiol Prev. 2013 Mar-Jun;37(2-3 Suppl 2):1-100. Epidemiol Prev. 2013. PMID: 23851286 Italian.
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
