

Clinical Performance and Communication Skills of ChatGPT Versus Physicians in Emergency Medicine: Simulated Patient Study
- PMID: 40674718
- PMCID: PMC12289221
- DOI: 10.2196/68409
Clinical Performance and Communication Skills of ChatGPT Versus Physicians in Emergency Medicine: Simulated Patient Study
Abstract
Background: Emergency medicine can benefit from artificial intelligence (AI) due to its unique challenges, such as high patient volume and the need for urgent interventions. However, it remains difficult to assess the applicability of AI systems to real-world emergency medicine practice, which requires not only medical knowledge but also adaptable problem-solving and effective communication skills.
Objective: We aimed to evaluate ChatGPT's (OpenAI) performance in comparison to human doctors in simulated emergency medicine settings, using the framework of clinical performance examination and written examinations.
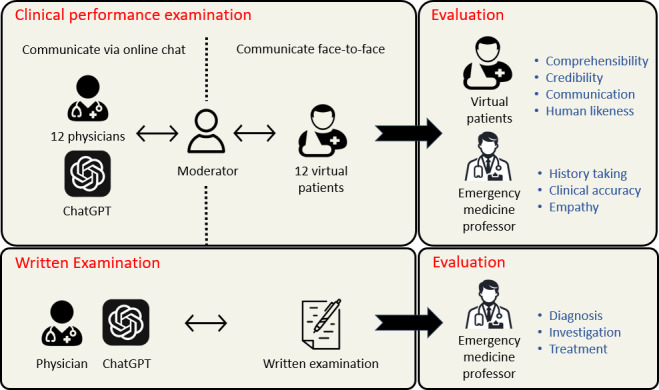
Methods: In total, 12 human doctors were recruited to represent the medical professionals. Both ChatGPT and the human doctors were instructed to manage each case like real clinical settings with 12 simulated patients. After the clinical performance examination sessions, the conversation records were evaluated by an emergency medicine professor on history taking, clinical accuracy, and empathy on a 5-point Likert scale. Simulated patients completed a 5-point scale survey including overall comprehensibility, credibility, and concern reduction for each case. In addition, they evaluated whether the doctor they interacted with was similar to a human doctor. An additional evaluation was performed using vignette-based written examinations to assess diagnosis, investigation, and treatment planning. The mean scores from ChatGPT were then compared with those of the human doctors.
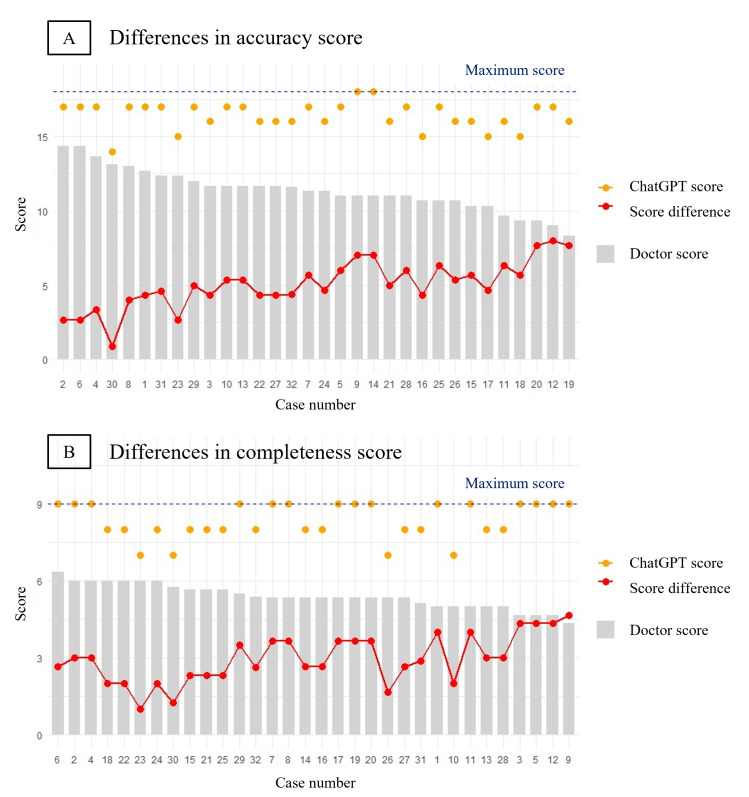
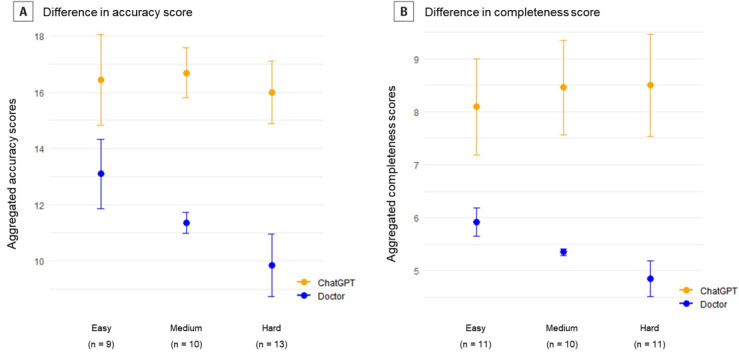
Results: ChatGPT scored significantly higher than the physicians in both history-taking (mean score 3.91, SD 0.67 vs mean score 2.67, SD 0.78, P<.001) and empathy (mean score 4.50, SD 0.67 vs mean score 1.75, SD 0.62, P<.001). However, there was no significant difference in clinical accuracy. In the survey conducted with simulated patients, ChatGPT scored higher for concern reduction (mean score 4.33, SD 0.78 vs mean score 3.58, SD 0.90, P=.04). For comprehensibility and credibility, ChatGPT showed better performance, but the difference was not significant. In the similarity assessment score, no significant difference was observed (mean score 3.50, SD 1.78 vs mean score 3.25, SD 1.86, P=.71).
Conclusions: ChatGPT's performance highlights its potential as a valuable adjunct in emergency medicine, demonstrating comparable proficiency in knowledge application, efficiency, and empathetic patient interaction. These results suggest that a collaborative health care model, integrating AI with human expertise, could enhance patient care and outcomes.
Keywords: ChatGPT; artificial intelligence; clinical performance examination; clinical reasoning; emergency medicine; empathy; history taking; large language model; patient experience.
© ChulHyoung Park, Min Ho An, Gyubeom Hwang, Rae Woong Park, Juho An. Originally published in JMIR Medical Informatics (https://medinform.jmir.org).
Conflict of interest statement
Figures
Similar articles
-
Utility of Generative Artificial Intelligence for Japanese Medical Interview Training: Randomized Crossover Pilot Study.JMIR Med Educ. 2025 Aug 1;11:e77332. doi: 10.2196/77332. JMIR Med Educ. 2025. PMID: 40749190 Free PMC article. Clinical Trial.
-
Quality and Dependability of ChatGPT and DingXiangYuan Forums for Remote Orthopedic Consultations: Comparative Analysis.J Med Internet Res. 2024 Mar 14;26:e50882. doi: 10.2196/50882. J Med Internet Res. 2024. PMID: 38483451 Free PMC article.
-
Large Language Models and Empathy: Systematic Review.J Med Internet Res. 2024 Dec 11;26:e52597. doi: 10.2196/52597. J Med Internet Res. 2024. PMID: 39661968 Free PMC article.
-
Comparison of ChatGPT and Internet Research for Clinical Research and Decision-Making in Occupational Medicine: Randomized Controlled Trial.JMIR Form Res. 2025 May 20;9:e63857. doi: 10.2196/63857. JMIR Form Res. 2025. PMID: 40393042 Free PMC article. Clinical Trial.
-
Performance of ChatGPT Across Different Versions in Medical Licensing Examinations Worldwide: Systematic Review and Meta-Analysis.J Med Internet Res. 2024 Jul 25;26:e60807. doi: 10.2196/60807. J Med Internet Res. 2024. PMID: 39052324 Free PMC article.
References
-
- Sarraju A, Bruemmer D, Van Iterson E, Cho L, Rodriguez F, Laffin L. Appropriateness of cardiovascular disease prevention recommendations obtained from a popular online chat-based artificial intelligence model. JAMA. 2023 Mar 14;329(10):842–844. doi: 10.1001/jama.2023.1044. doi. Medline. - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
