

Adaptive multi-view learning method for enhanced drug repurposing using chemical-induced transcriptional profiles, knowledge graphs, and large language models
- PMID: 40678475
- PMCID: PMC12268076
- DOI: 10.1016/j.jpha.2025.101275
Adaptive multi-view learning method for enhanced drug repurposing using chemical-induced transcriptional profiles, knowledge graphs, and large language models
Abstract
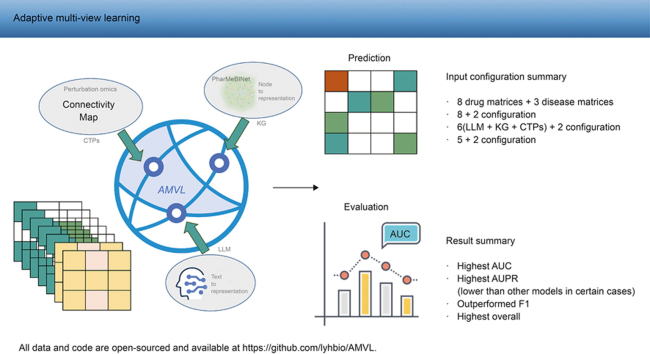
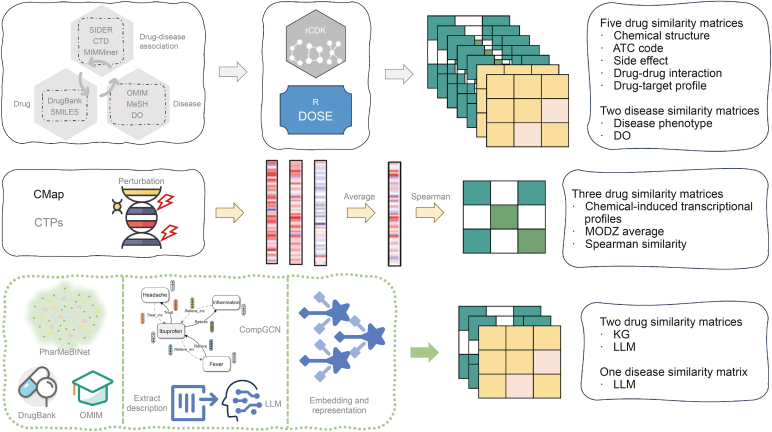
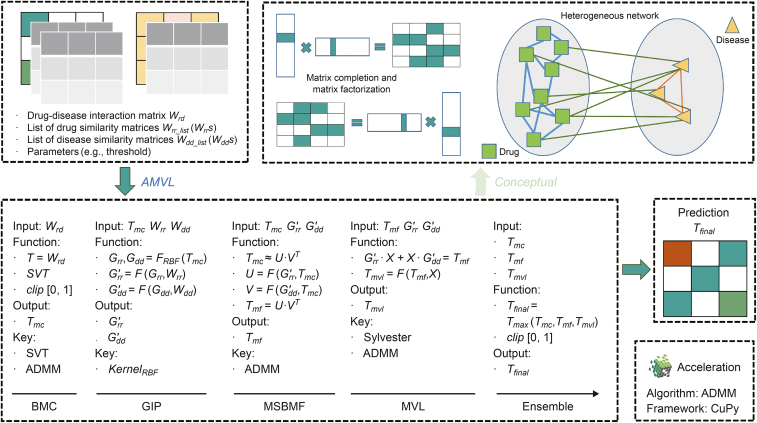
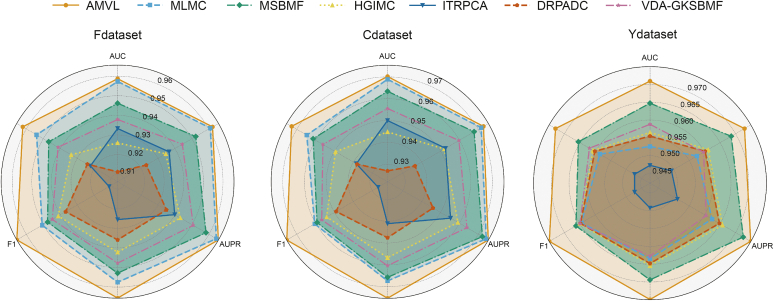
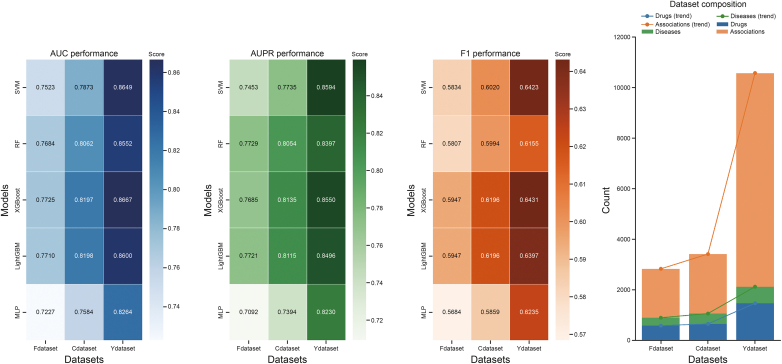
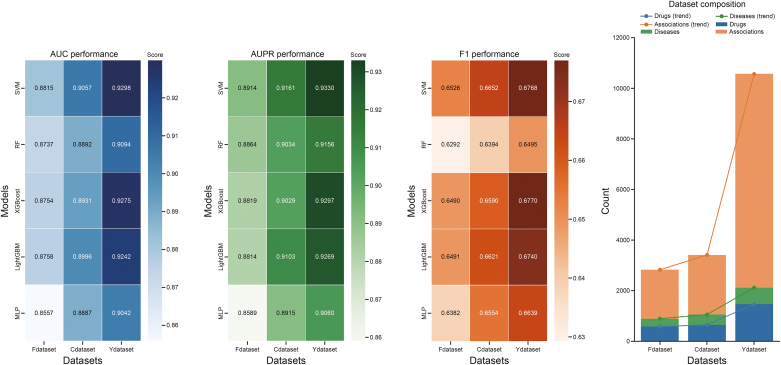
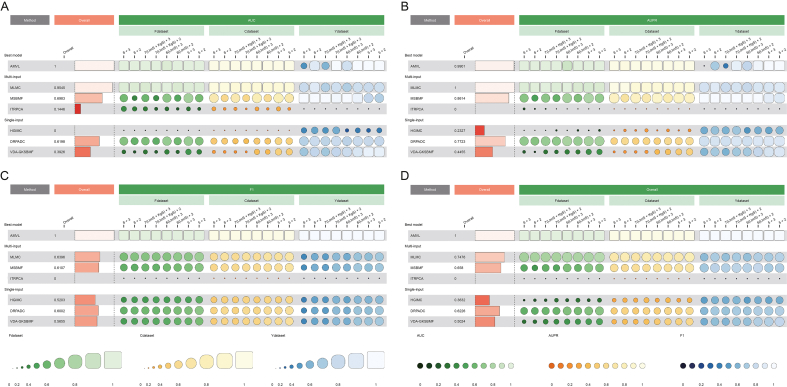
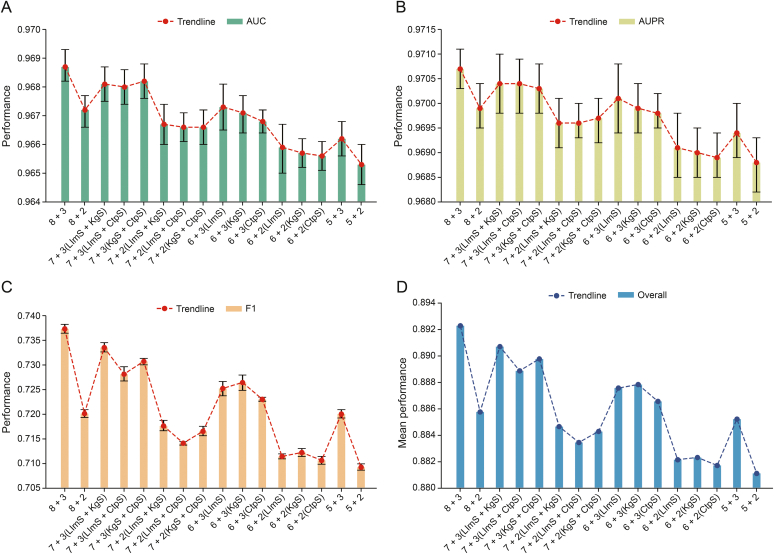
Drug repurposing offers a promising alternative to traditional drug development and significantly reduces costs and timelines by identifying new therapeutic uses for existing drugs. However, the current approaches often rely on limited data sources and simplistic hypotheses, which restrict their ability to capture the multi-faceted nature of biological systems. This study introduces adaptive multi-view learning (AMVL), a novel methodology that integrates chemical-induced transcriptional profiles (CTPs), knowledge graph (KG) embeddings, and large language model (LLM) representations, to enhance drug repurposing predictions. AMVL incorporates an innovative similarity matrix expansion strategy and leverages multi-view learning (MVL), matrix factorization, and ensemble optimization techniques to integrate heterogeneous multi-source data. Comprehensive evaluations on benchmark datasets (Fdataset, Cdataset, and Ydataset) and the large-scale iDrug dataset demonstrate that AMVL outperforms state-of-the-art (SOTA) methods, achieving superior accuracy in predicting drug-disease associations across multiple metrics. Literature-based validation further confirmed the model's predictive capabilities, with seven out of the top ten predictions corroborated by post-2011 evidence. To promote transparency and reproducibility, all data and codes used in this study were open-sourced, providing resources for processing CTPs, KG, and LLM-based similarity calculations, along with the complete AMVL algorithm and benchmarking procedures. By unifying diverse data modalities, AMVL offers a robust and scalable solution for accelerating drug discovery, fostering advancements in translational medicine and integrating multi-omics data. We aim to inspire further innovations in multi-source data integration and support the development of more precise and efficient strategies for advancing drug discovery and translational medicine.
Keywords: Chemical-induced transcriptional profile; Drug repurposing; Heterogeneous network; Knowledge graph; Large language model; Multi-view learning.
© 2025 The Author(s).
Conflict of interest statement
The authors declare that there are no conflicts of interest.
Figures

Similar articles
-
Stabilizing machine learning for reproducible and explainable results: A novel validation approach to subject-specific insights.Comput Methods Programs Biomed. 2025 Sep;269:108899. doi: 10.1016/j.cmpb.2025.108899. Epub 2025 Jun 21. Comput Methods Programs Biomed. 2025. PMID: 40570739
-
Psychometric Evaluation of Large Language Model Embeddings for Personality Trait Prediction.J Med Internet Res. 2025 Jul 8;27:e75347. doi: 10.2196/75347. J Med Internet Res. 2025. PMID: 40627556 Free PMC article.
-
A dataset and benchmark for hospital course summarization with adapted large language models.J Am Med Inform Assoc. 2025 Mar 1;32(3):470-479. doi: 10.1093/jamia/ocae312. J Am Med Inform Assoc. 2025. PMID: 39786555
-
Management of urinary stones by experts in stone disease (ESD 2025).Arch Ital Urol Androl. 2025 Jun 30;97(2):14085. doi: 10.4081/aiua.2025.14085. Epub 2025 Jun 30. Arch Ital Urol Androl. 2025. PMID: 40583613 Review.
-
Artificial intelligence for diagnosing exudative age-related macular degeneration.Cochrane Database Syst Rev. 2024 Oct 17;10(10):CD015522. doi: 10.1002/14651858.CD015522.pub2. Cochrane Database Syst Rev. 2024. PMID: 39417312
References
-
- Chong C.R., Sullivan D.J., Jr New uses for old drugs. Nature. 2007;448:645–646. - PubMed
-
- Pushpakom S., Iorio F., Eyers P.A., et al. Drug repurposing: Progress, challenges and recommendations. Nat. Rev. Drug Discov. 2019;18:41–58. - PubMed
-
- Tan S.Y., Grimes S. Paul Ehrlich (1854–1915): Man with the magic bullet. Singapore Med. J. 2010;51:842–843. - PubMed
LinkOut - more resources
Full Text Sources
