

A comparison of modeling approaches for static and dynamic prediction of central line-associated bloodstream infections using electronic health records (part 2): random forest models
- PMID: 40691852
- PMCID: PMC12278561
- DOI: 10.1186/s41512-025-00194-8
A comparison of modeling approaches for static and dynamic prediction of central line-associated bloodstream infections using electronic health records (part 2): random forest models
Abstract
Objective: Prognostic outcomes related to hospital admissions typically do not suffer from censoring, and can be modeled either categorically or as time-to-event. Competing events are common but often ignored. We compared the performance of static and dynamic random forest (RF) models to predict the risk of central line-associated bloodstream infections (CLABSI) using different outcome operationalizations.
Methods: We included data from 27,478 admissions to the University Hospitals Leuven, covering 30,862 catheter episodes (970 CLABSI, 1466 deaths and 28,426 discharges) to build static and dynamic RF models for binary (CLABSI vs no CLABSI), multinomial (CLABSI, discharge, death or no event), survival (time to CLABSI) and competing risks (time to CLABSI, discharge or death) outcomes to predict the 7-day CLABSI risk. Static models used information at the onset of the catheter episode, while dynamic models updated predictions daily for 30 days (landmark 0-30). We evaluated model performance across 100 train/test splits.
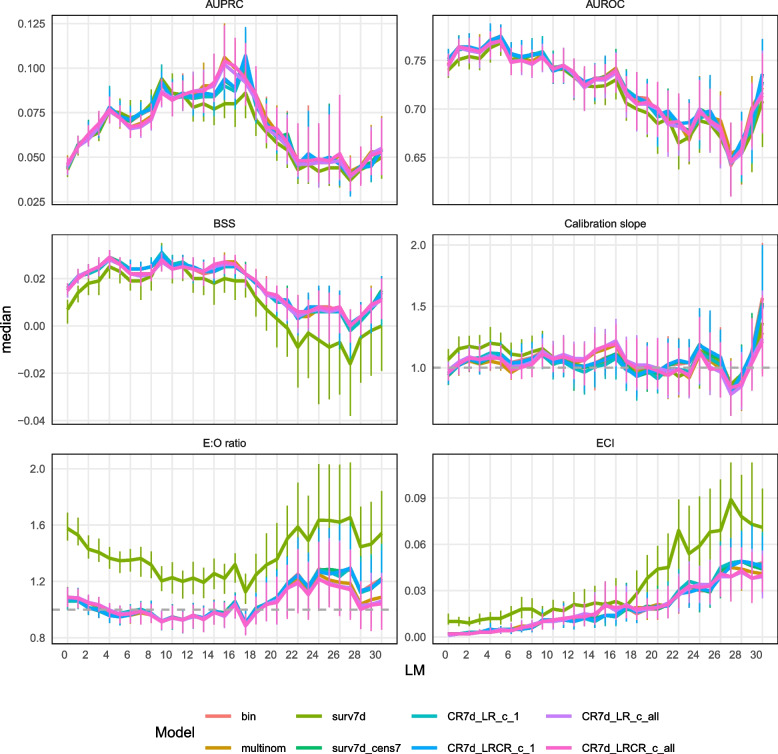
Results: Performance of binary, multinomial and competing risks models was similar: AUROC was 0.74 for predictions at catheter onset, rose to 0.77 for predictions at landmark 5, and decreased thereafter. Survival models overestimated the risk of CLABSI (E:O ratios between 1.2 and 1.6), and had AUROCs about 0.01 lower than other models. Binary and multinomial models had lowest computation times. Models including multiple outcome events (multinomial and competing risks) display a different internal structure compared to binary and survival models, choosing different variables for early splits in trees.
Discussion and conclusion: In the absence of censoring, complex modelling choices do not considerably improve the predictive performance compared to a binary model for CLABSI prediction in our studied settings. Survival models censoring the competing events at their time of occurrence should be avoided.
Keywords: CLABSI; Competing risks; Dynamic prediction; EHR; Random forests; Survival.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Ethics approval and consent to participate: The study was approved by the Ethics Committee Research UZ/KU Leuven (EC Research, https://admin.kuleuven.be/raden/en/ethics-committee-research-uz-kuleuven# ) on 19 January 2022 (S60891). The Ethics Committee Research UZ/KU Leuven waived the need to obtain informed consent from participants. All patient identifiers were coded using the pseudo-identifier in the data warehouse by the Management Information Reporting Department of UZ Leuven, according to the General Data Protection Regulation (GDPR). Consent for publication: Not applicable. Competing interests: The authors declare that they have no competing interests.
Figures



References
-
- Frondelius T, Atkova I, Miettunen J, Rello J, Vesty G, Chew HSJ, et al. Early prediction of ventilator-associated pneumonia with machine learning models: A systematic review and meta-analysis of prediction model performance. Eur J Intern Med. 2024;121:76-87. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources