

Comparative Analysis of Generative Artificial Intelligence Systems in Solving Clinical Pharmacy Problems: Mixed Methods Study
- PMID: 40705654
- PMCID: PMC12288765
- DOI: 10.2196/76128
Comparative Analysis of Generative Artificial Intelligence Systems in Solving Clinical Pharmacy Problems: Mixed Methods Study
Abstract
Background: Generative artificial intelligence (AI) systems are increasingly deployed in clinical pharmacy; yet, systematic evaluation of their efficacy, limitations, and risks across diverse practice scenarios remains limited.
Objective: This study aims to quantitatively evaluate and compare the performance of 8 mainstream generative AI systems across 4 core clinical pharmacy scenarios-medication consultation, medication education, prescription review, and case analysis with pharmaceutical care-using a multidimensional framework.
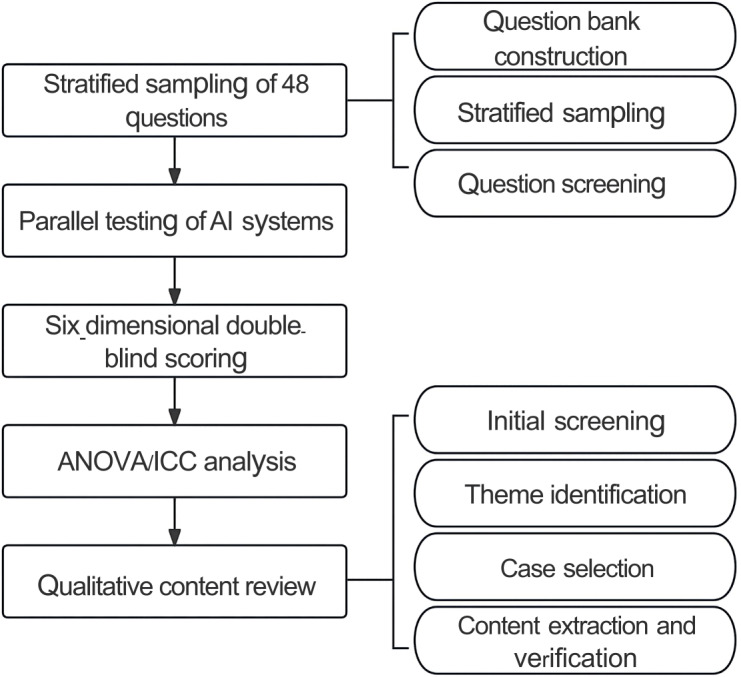
Methods: Forty-eight clinically validated questions were selected via stratified sampling from real-world sources (eg, hospital consultations, clinical case banks, and national pharmacist training databases). Three researchers simultaneously tested 8 different generative AI systems (ERNIE Bot, Doubao, Kimi, Qwen, GPT-4o, Gemini-1.5-Pro, Claude-3.5-Sonnet, and DeepSeek-R1) using standardized prompts within a single day (February 20, 2025). A double-blind scoring design was used, with 6 experienced clinical pharmacists (≥5 years experience) evaluating the AI responses across 6 dimensions: accuracy, rigor, applicability, logical coherence, conciseness, and universality, scored 0-10 per predefined criteria (eg, -3 for inaccuracy and -2 for incomplete rigor). Statistical analysis used one-way ANOVA with Tukey Honestly Significant Difference (HSD) post hoc testing and intraclass correlation coefficients (ICC) for interrater reliability (2-way random model). Qualitative thematic analysis identified recurrent errors and limitations.
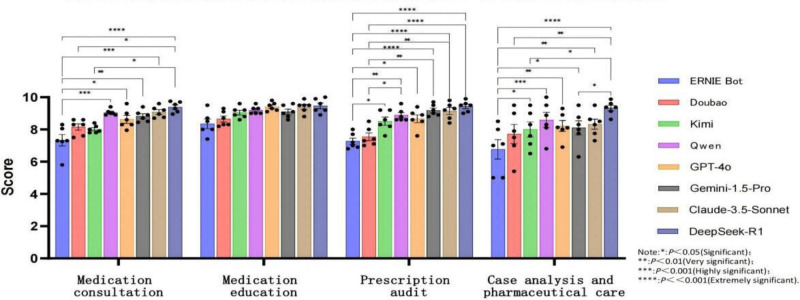
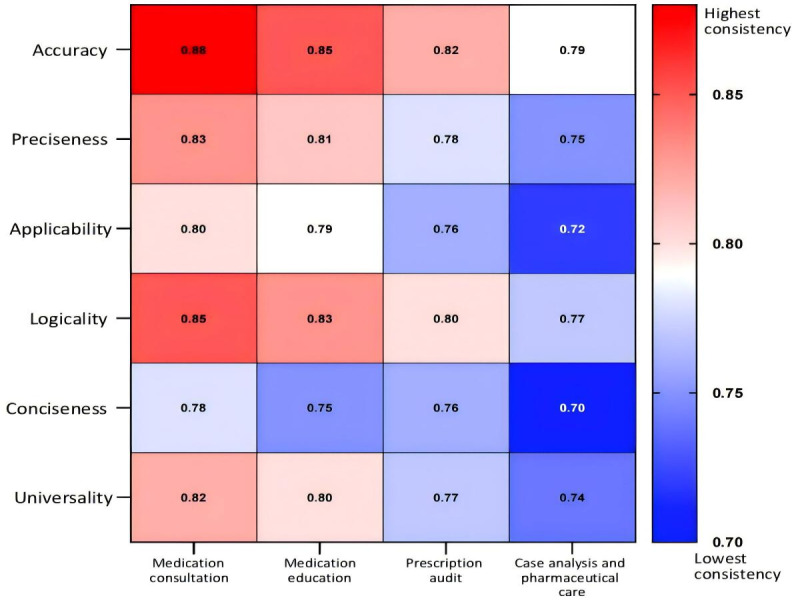
Results: DeepSeek-R1 (DeepSeek) achieved the highest overall performance (mean composite score: medication consultation 9.4, SD 1.0; case analysis 9.3, SD 1.0), significantly outperforming others in complex tasks (P<.05). Critical limitations were observed across models, including high-risk decision errors-75% omitted critical contraindications (eg, ethambutol in optic neuritis) and a lack of localization-90% erroneously recommended macrolides for drug-resistant Mycoplasma pneumoniae (China's high-resistance setting), while only DeepSeek-R1 aligned with updated American Academy of Pediatrics (AAP) guidelines for pediatric doxycycline. Complex reasoning deficits: only Claude-3.5-Sonnet detected a gender-diagnosis contradiction (prostatic hyperplasia in female); no model identified diazepam's 7-day prescription limit. Interrater consistency was lowest for conciseness in case analysis (ICC=0.70), reflecting evaluator disagreement on complex outputs. ERNIE Bot (Baidu) consistently underperformed (case analysis: 6.8, SD 1.5; P<.001 vs DeepSeek-R1).
Conclusions: While generative AI shows promise as a pharmacist assistance tool, significant limitations-including high-risk errors (eg, contraindication omissions), inadequate localization, and complex reasoning gaps-preclude autonomous clinical decision-making. Performance stratification highlights DeepSeek-R1's current advantage, but all systems require optimization in dynamic knowledge updating, complex scenario reasoning, and output interpretability. Future deployment must prioritize human oversight (human-AI co-review), ethical safeguards, and continuous evaluation frameworks.
Keywords: DeepSeek-R1; artificial intelligence; clinical pharmacy; comparative analysis; generative AI.
©Lulu Li, Pengqiang Du, Xiaojing Huang, Hongwei Zhao, Ming Ni, Meng Yan, Aifeng Wang. Originally published in JMIR Medical Informatics (https://medinform.jmir.org).
Conflict of interest statement
Figures
References
-
- Al-Ashwal FY, Zawiah M, Gharaibeh L, Abu-Farha R, Bitar AN. Evaluating the sensitivity, specificity, and accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard against conventional drug-drug interactions clinical tools. Drug Healthc Patient Saf. 2023;15:137–147. doi: 10.2147/DHPS.S425858. doi. Medline. - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
