

Assessing and enhancing the reliability of Chinese large language models in dental implantology
- PMID: 40713564
- PMCID: PMC12296590
- DOI: 10.1186/s12903-025-06648-1
Assessing and enhancing the reliability of Chinese large language models in dental implantology
Abstract
Background: This study aimed to evaluate the reliability of five representative Chinese large language models (LLMs) in dental implantology. It also explored effective strategies for model enhancement.
Methods: A dataset of 100 dental implant-related questions (50 multiple-choice and 50 open-ended) was developed, covering medical knowledge, complex reasoning, and safety and ethics. Standard answers were validated by experts. Five LLMs—A: BaiXiaoYing, B: ChatGLM-4, C: ERNIE Bot 3.5, D: Qwen 2.5, and E: Kimi.ai—were tested using two metrics: recall and hallucination rate. Two enhancement techniques, chain of thought (CoT) reasoning and long text modeling (LTM), were applied, and their effectiveness was analyzed by comparing the metrics before and after the application of these techniques. Data analysis was conducted using SPSS software. ANOVA with Tukey HSD tests compared recall and hallucination rates across models, while paired t-tests evaluated changes before and after enhancement strategies.
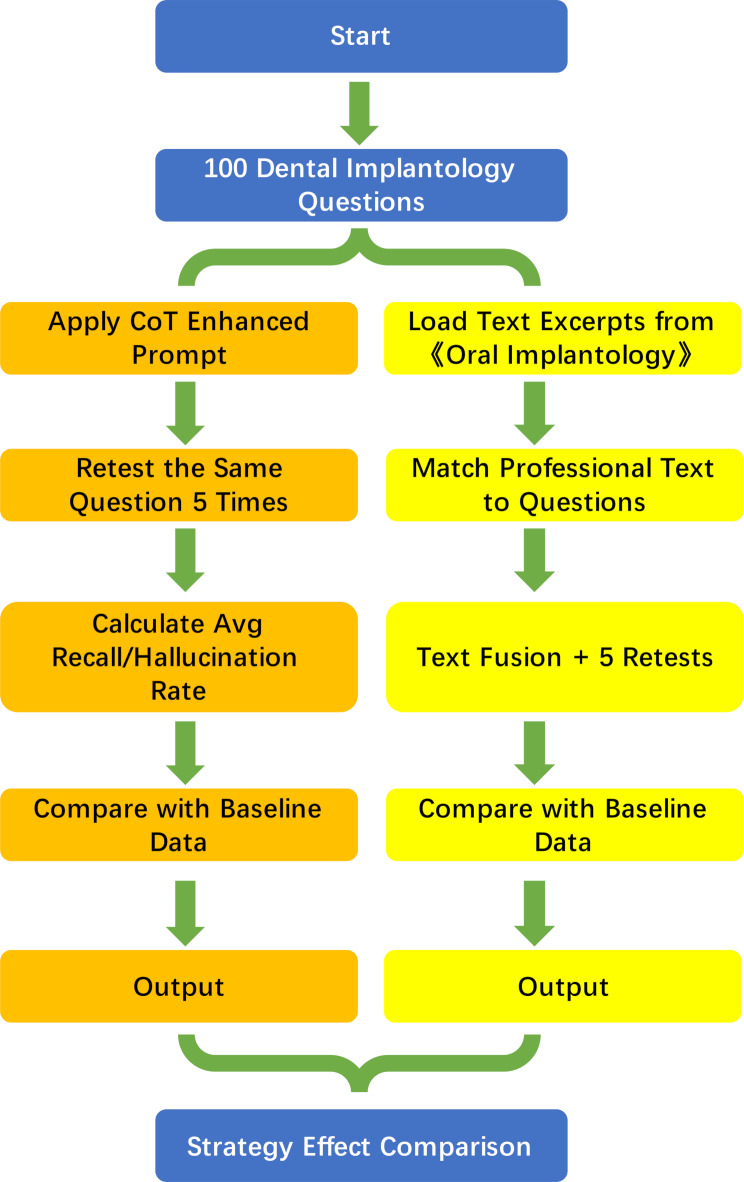
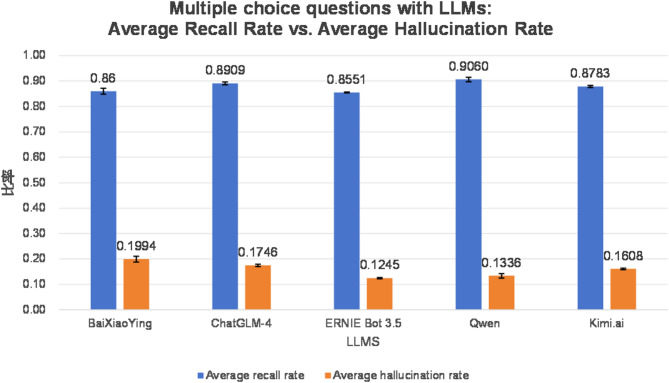
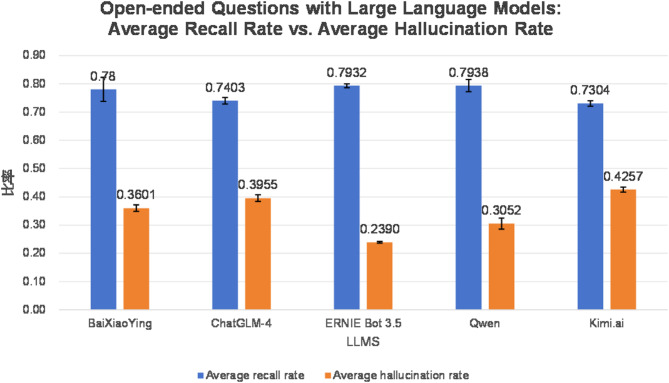
Results: For multiple-choice questions, Group D (Qwen 2.5) achieved the highest recall at 0.9060 ± 0.0087, while Group C (ERNIE Bot 3.5) had the lowest hallucination rate at 0.1245 ± 0.0022. For open-ended questions, Group D maintained the highest recall at 0.7938 ± 0.0216, and Group C exhibited the lowest hallucination rate at 0.2390 ± 0.0029. Among enhancement strategies, chain-of-thought (CoT) reasoning improved Group D’s recall by 0.0621 ± 0.1474 (P < 0.05) but caused a non-significant increase in hallucination rate (0.0390 ± 0.1639, P > 0.05). Long-text modeling (LTM) significantly enhanced recall by 0.1119 ± 0.2000 (P < 0.05) and reduced hallucination rate by 0.2985 ± 0.4220 (P < 0.05).
Conclusions: Qwen 2.5 and ERNIE Bot 3.5 demonstrated exceptional reliability in dental implantology, excelling in answer accuracy and minimizing misinformation across question types. Open-ended queries posed higher risks of hallucinations compared to structured multiple-choice tasks, highlighting the need for targeted validation in free-text scenarios. Chain-of-thought (CoT) reasoning modestly improved accuracy but carried the trade-off of potential hallucination increases, while long-text modeling (LTM) significantly enhanced both accuracy and reliability simultaneously. These findings underscore LTM’s utility in optimizing large language models for specialized dental applications, balancing depth of reasoning with factual grounding to support clinical decision-making and educational training.
Supplementary Information: The online version contains supplementary material available at 10.1186/s12903-025-06648-1.
Keywords: Chain-of-thought reasoning; Dental implantology; Hallucination rate; Large language models; Long-text modeling; Recall.
Conflict of interest statement
Declarations. Ethics approval and consent to participate: This study involved non-human subjects and did not require institutional review board (IRB) approval. All data used were de-identified and anonymized to protect patient privacy. The use of LLMs complied with the respective providers’ terms of service, including API access agreements and data security protocols. Specifically, no personal health information was input into the models, and all interactions were logged for audit purposes only. Consent for publication: Not applicable. Competing interests: The authors declare no competing interests. Clinical trial number: Not applicable.
Figures

Similar articles
-
Lingdan: enhancing encoding of traditional Chinese medicine knowledge for clinical reasoning tasks with large language models.J Am Med Inform Assoc. 2024 Sep 1;31(9):2019-2029. doi: 10.1093/jamia/ocae087. J Am Med Inform Assoc. 2024. PMID: 39038795 Free PMC article.
-
Performance of ChatGPT-4o and Four Open-Source Large Language Models in Generating Diagnoses Based on China's Rare Disease Catalog: Comparative Study.J Med Internet Res. 2025 Jun 18;27:e69929. doi: 10.2196/69929. J Med Internet Res. 2025. PMID: 40532199 Free PMC article.
-
Effectiveness of various general large language models in clinical consensus and case analysis in dental implantology: a comparative study.BMC Med Inform Decis Mak. 2025 Mar 26;25(1):147. doi: 10.1186/s12911-025-02972-2. BMC Med Inform Decis Mak. 2025. PMID: 40140812 Free PMC article.
-
Recall intervals for oral health in primary care patients.Cochrane Database Syst Rev. 2013 Dec 19;(12):CD004346. doi: 10.1002/14651858.CD004346.pub4. Cochrane Database Syst Rev. 2013. Update in: Cochrane Database Syst Rev. 2020 Oct 14;10:CD004346. doi: 10.1002/14651858.CD004346.pub5. PMID: 24353242 Updated.
-
Thirty Years of Translational Research in Zirconia Dental Implants: A Systematic Review of the Literature.J Oral Implantol. 2017 Aug;43(4):314-325. doi: 10.1563/aaid-joi-D-17-00016. Epub 2017 Jun 8. J Oral Implantol. 2017. PMID: 28594591
References
-
- Zhao J, Li X, Chen W, Wang Y. Survey on the availability of oral implantology training in primary healthcare facilities in China. Chin J Dent Res. 2022;25:234–45. 10.1016/j.cjdr.2022.04.003.
-
- Liu H, Wang Y, Li X, Chen W. Pilot program results of using Chinese large language models for continuing professional development in oral implantology. J Dent Educ. 2023;87:987–95. 10.1002/jdd.1361
-
- National Health Commission of China. Initiatives to promote the use of AI in medical training and practice. 2023. Available at: http://www.nhc.gov.cn/. Accessed September 6, 2024.
-
- Zhang Y, Liu H, Sun T. Evaluating the impact of chain of thought prompts on the performance of large language models in medical domains. Artif Intell Med. 2022;127:102167. 10.1016/j.artmed.2022.102167
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
