

Design of highly functional genome editors by modelling CRISPR-Cas sequences
- PMID: 40739342
- PMCID: PMC12422970
- DOI: 10.1038/s41586-025-09298-z
Design of highly functional genome editors by modelling CRISPR-Cas sequences
Abstract
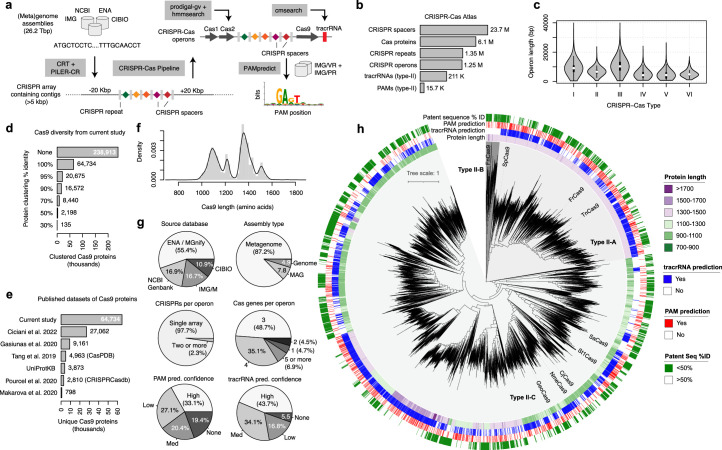
Gene editing has the potential to solve fundamental challenges in agriculture, biotechnology and human health. CRISPR-based gene editors derived from microorganisms, although powerful, often show notable functional tradeoffs when ported into non-native environments, such as human cells1. Artificial-intelligence-enabled design provides a powerful alternative with the potential to bypass evolutionary constraints and generate editors with optimal properties. Here, using large language models2 trained on biological diversity at scale, we demonstrate successful precision editing of the human genome with a programmable gene editor designed with artificial intelligence. To achieve this goal, we curated a dataset of more than 1 million CRISPR operons through systematic mining of 26 terabases of assembled genomes and metagenomes. We demonstrate the capacity of our models by generating 4.8× the number of protein clusters across CRISPR-Cas families found in nature and tailoring single-guide RNA sequences for Cas9-like effector proteins. Several of the generated gene editors show comparable or improved activity and specificity relative to SpCas9, the prototypical gene editing effector, while being 400 mutations away in sequence. Finally, we demonstrate that an artificial-intelligence-generated gene editor, denoted as OpenCRISPR-1, exhibits compatibility with base editing. We release OpenCRISPR-1 to facilitate broad, ethical use across research and commercial applications.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: All authors are current or former employees, contractors or executives of Profluent Bio Inc and may hold shares in Profluent Bio Inc.
Figures













References
-
- Pacesa, M., Pelea, O. & Jinek, M. Past, present, and future of crispr genome editing technologies. Cell187, 1076–1100 (2024). - PubMed
-
- Nijkamp, E., Ruffolo, J. A., Weinstein, E. N., Naik, N. & Madani, A. Progen2: exploring the boundaries of protein language models. Cell Syst.14, 968–978 (2023).
-
- Wu, Z. et al. Programmed genome editing by a miniature CRISPR–Cas12f nuclease. Nat. Chem. Biol.17, 1132–1138 (2021). - PubMed
-
- Chen, K. et al. Lung and liver editing by lipid nanoparticle delivery of a stable CRISPR–Cas9 ribonucleoprotein. Nat. Biotechnol.10.1038/s41587-024-02437-3 (2024).
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
