

Dynamic Network Plasticity and Sample Efficiency in Biological Neural Cultures: A Comparative Study with Deep Reinforcement Learning
- PMID: 40762022
- PMCID: PMC12320521
- DOI: 10.34133/cbsystems.0336
Dynamic Network Plasticity and Sample Efficiency in Biological Neural Cultures: A Comparative Study with Deep Reinforcement Learning
Abstract
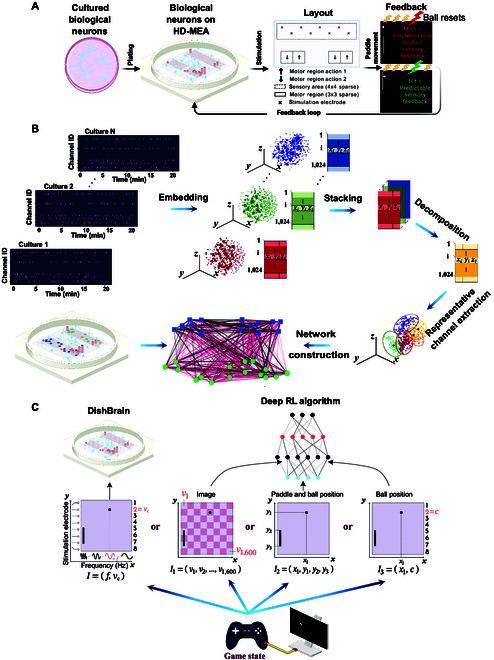
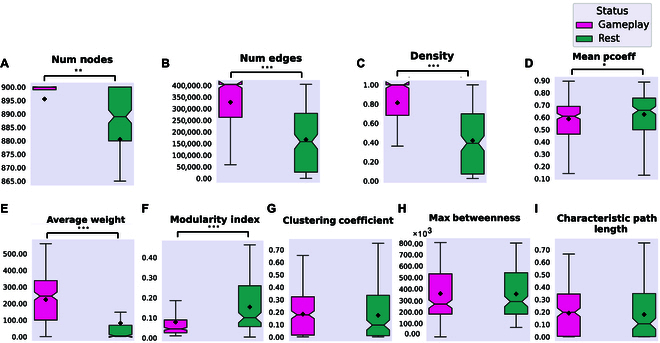
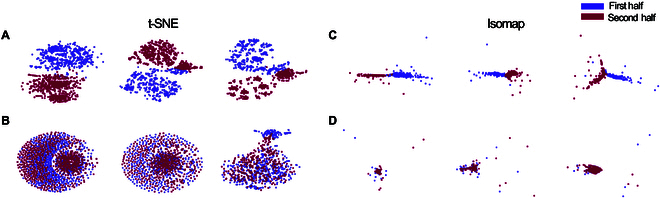
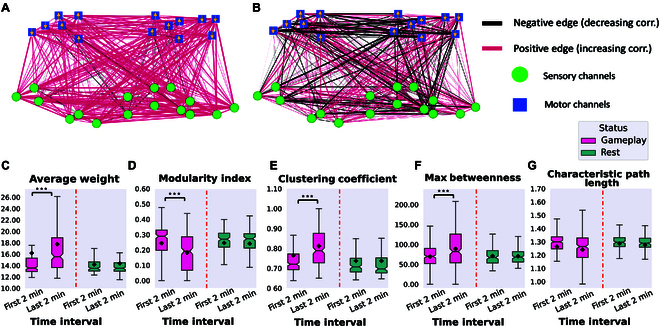
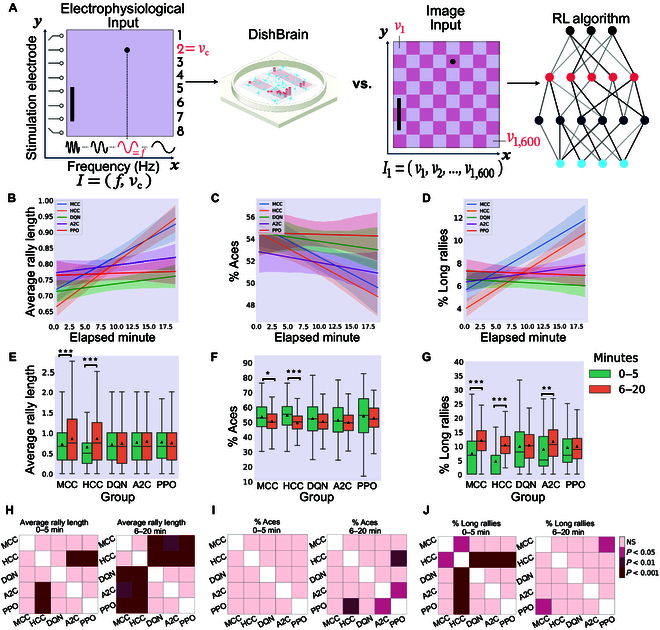
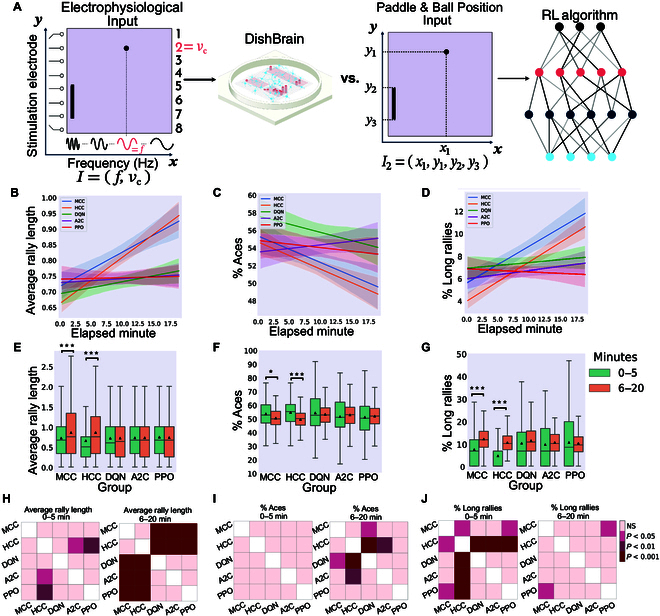
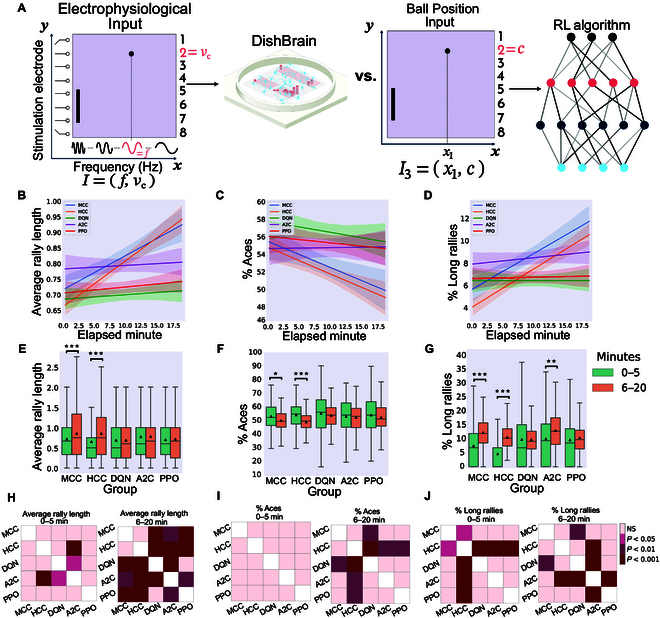
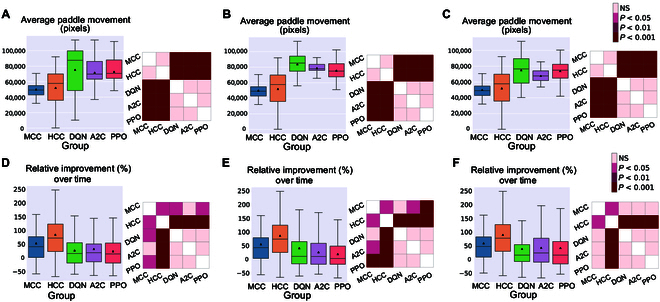
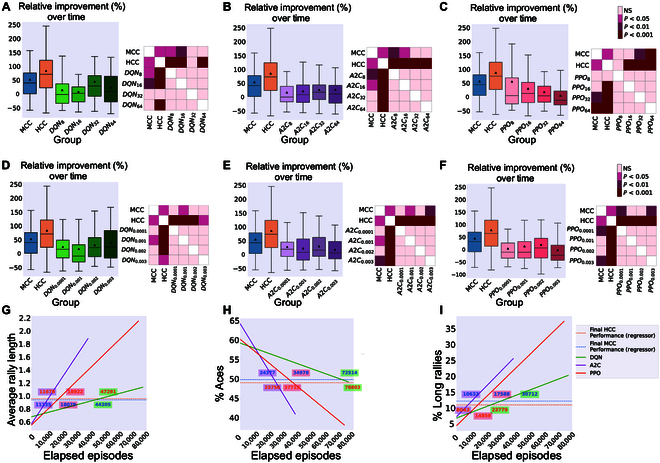
In this study, we investigate the complex network dynamics of in vitro neural systems using DishBrain, which integrates live neural cultures with high-density multi-electrode arrays in real-time, closed-loop game environments. By embedding spiking activity into lower-dimensional spaces, we distinguish between spontaneous activity (Rest) and Gameplay conditions, revealing underlying patterns crucial for real-time monitoring and manipulation. Our analysis highlights dynamic changes in connectivity during Gameplay, underscoring the highly sample efficient plasticity of these networks in response to stimuli. To explore whether this was meaningful in a broader context, we compared the learning efficiency of these biological systems with state-of-the-art deep reinforcement learning (RL) algorithms (Deep Q Network, Advantage Actor-Critic, and Proximal Policy Optimization) in a simplified Pong simulation. Through this, we introduce a meaningful comparison between biological neural systems and deep RL. We find that when samples are limited to a real-world time course, even these very simple biological cultures outperformed deep RL algorithms across various game performance characteristics, implying a higher sample efficiency.
Copyright © 2025 Moein Khajehnejad et al.
Conflict of interest statement
Competing interests: B.J.K., A.L., F.H., and M.K. were contracted or employed by Cortical Labs during the course of this research. B.J.K. has shares in Cortical Labs and an interest in patents related to this work. All other authors declare that they have no competing interests.
Figures
Similar articles
-
Short-Term Memory Impairment.2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. 2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. PMID: 31424720 Free Books & Documents.
-
Surgical interventions for treating extracapsular hip fractures in older adults: a network meta-analysis.Cochrane Database Syst Rev. 2022 Feb 10;2(2):CD013405. doi: 10.1002/14651858.CD013405.pub2. Cochrane Database Syst Rev. 2022. PMID: 35142366 Free PMC article.
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2017 Dec 22;12(12):CD011535. doi: 10.1002/14651858.CD011535.pub2. Cochrane Database Syst Rev. 2017. Update in: Cochrane Database Syst Rev. 2020 Jan 9;1:CD011535. doi: 10.1002/14651858.CD011535.pub3. PMID: 29271481 Free PMC article. Updated.
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2021 Apr 19;4(4):CD011535. doi: 10.1002/14651858.CD011535.pub4. Cochrane Database Syst Rev. 2021. Update in: Cochrane Database Syst Rev. 2022 May 23;5:CD011535. doi: 10.1002/14651858.CD011535.pub5. PMID: 33871055 Free PMC article. Updated.
-
Actor critic with experience replay-based automatic treatment planning for prostate cancer intensity modulated radiotherapy.Med Phys. 2025 Jul;52(7):e17915. doi: 10.1002/mp.17915. Epub 2025 May 31. Med Phys. 2025. PMID: 40450383 Free PMC article.
Cited by
-
Human neural organoid microphysiological systems show the building blocks necessary for basic learning and memory.Commun Biol. 2025 Aug 16;8(1):1237. doi: 10.1038/s42003-025-08632-5. Commun Biol. 2025. PMID: 40819006 Free PMC article.
References
-
- Ramchandran K, Zeien E, Andreasen NC. Distributed neural efficiency: Intelligence and age modulate adaptive allocation of resources in the brain. Trends Neurosci Educ. 2019;15:48–61. - PubMed
-
- Kudithipudi D, Aguilar-Simon M, Babb J, Bazhenov M, Blackiston D, Bongard J, Brna AP, Raja SC, Cheney N, Clune J, et al. Biological underpinnings for lifelong learning machines. Nat Mach Intell. 2022;4(3):196–210.
-
- Lake BM, Ullman TD, Tenenbaum JB, Gershman SJ. Building machines that learn and think like people. Behav Brain Sci. 2017;40: Article e253. - PubMed
-
- Hassabis D, Kumaran D, Summerfield C, Botvinick M. Neuroscience-inspired artificial intelligence. Neuron. 2017;95(2):245–258. - PubMed
-
- Sutton RS, Barto AG. Reinforcement learning: An introduction. MIT Press; 2018.
LinkOut - more resources
Full Text Sources
