

Multimodal reasoning agent for enhanced ophthalmic decision-making: a preliminary real-world clinical validation
- PMID: 40772224
- PMCID: PMC12325206
- DOI: 10.3389/fcell.2025.1642539
Multimodal reasoning agent for enhanced ophthalmic decision-making: a preliminary real-world clinical validation
Abstract
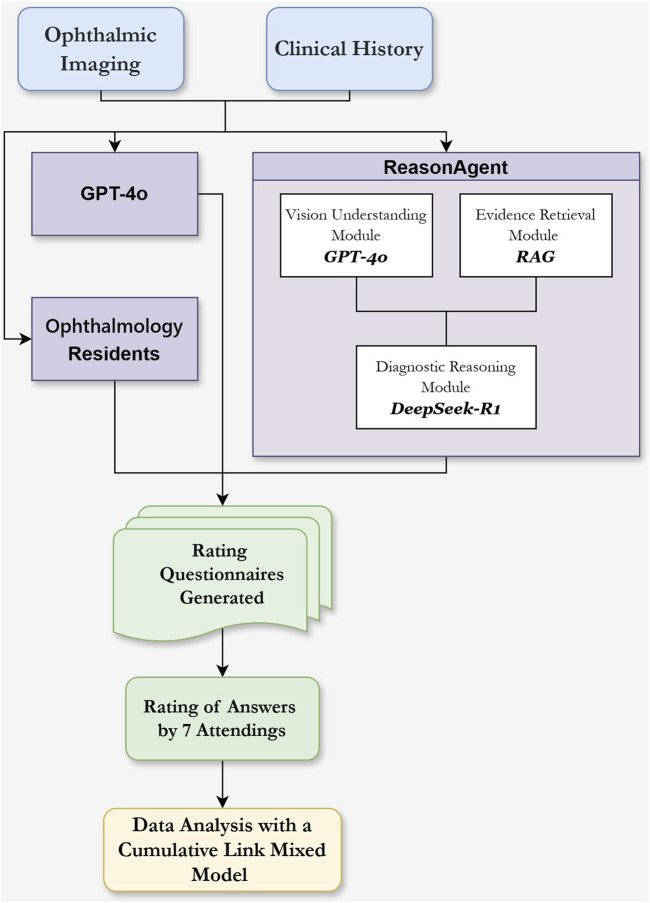
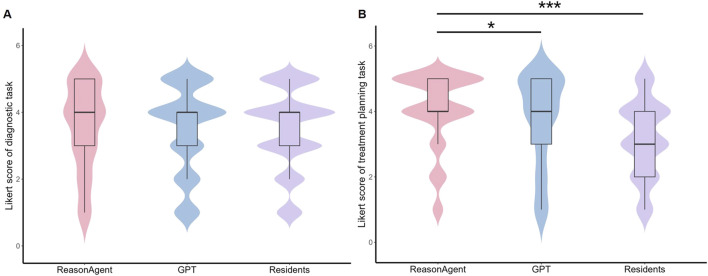
Although large language models (LLMs) show significant potential in clinical practice, accurate diagnosis and treatment planning in ophthalmology require multimodal integration of imaging, clinical history, and guideline-based knowledge. Current LLMs predominantly focus on unimodal language tasks and face limitations in specialized ophthalmic diagnosis due to domain knowledge gaps, hallucination risks, and inadequate alignment with clinical workflows. This study introduces a structured reasoning agent (ReasonAgent) that integrates a multimodal visual analysis module, a knowledge retrieval module, and a diagnostic reasoning module to address the limitations of current AI systems in ophthalmic decision-making. Validated on 30 real-world ophthalmic cases (27 common and 3 rare diseases), ReasonAgent demonstrated diagnostic accuracy comparable to ophthalmology residents (β = -0.07, p = 0.65). However, in treatment planning, it significantly outperformed both GPT-4o (β = 0.49, p = 0.01) and residents (β = 1.71, p < 0.001), particularly excelling in rare disease scenarios (all p < 0.05). While GPT-4o showed vulnerabilities in rare cases (90.48% low diagnostic scores), ReasonAgent's hybrid design mitigated errors through structured reasoning. Statistical analysis identified significant case-level heterogeneity (diagnosis ICC = 0.28), highlighting the need for domain-specific AI solutions in complex clinical contexts. This framework establishes a novel paradigm for domain-specific AI in real-world clinical practice, demonstrating the potential of modularized architectures to advance decision fidelity through human-aligned reasoning pathways.
Keywords: GPT-4o; artificial intelligence; large language models; ocular diseases; reasoning agent.
Copyright © 2025 Zhuang, Fang, Li, Bai, Hei, Feng, Li and Zhang.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
References
-
- Bommasani R., Hudson D., Adeli E., Altman R., Arora S., Arx S., et al. (2021). On the opportunities and risks of foundation models.
-
- Chen J., Xiao S., Zhang P., Luo K., Lian D., Liu Z. J. a.p.a. (2024b). Bge m3-embedding: multi-Lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.
LinkOut - more resources
Full Text Sources