

Ensemble learning to enhance accurate identification of patients with glaucoma using electronic health records
- PMID: 40799932
- PMCID: PMC12342940
- DOI: 10.1093/jamiaopen/ooaf080
Ensemble learning to enhance accurate identification of patients with glaucoma using electronic health records
Abstract
Objectives: Existing ophthalmology studies for clinical phenotypes identification in real-world datasets (RWD) rely exclusively on structured data elements (SDE). We evaluated the performance, generalizability, and fairness of multimodal ensemble models that integrate real-world SDE and free-text data compared to SDE-only models to identify patients with glaucoma.
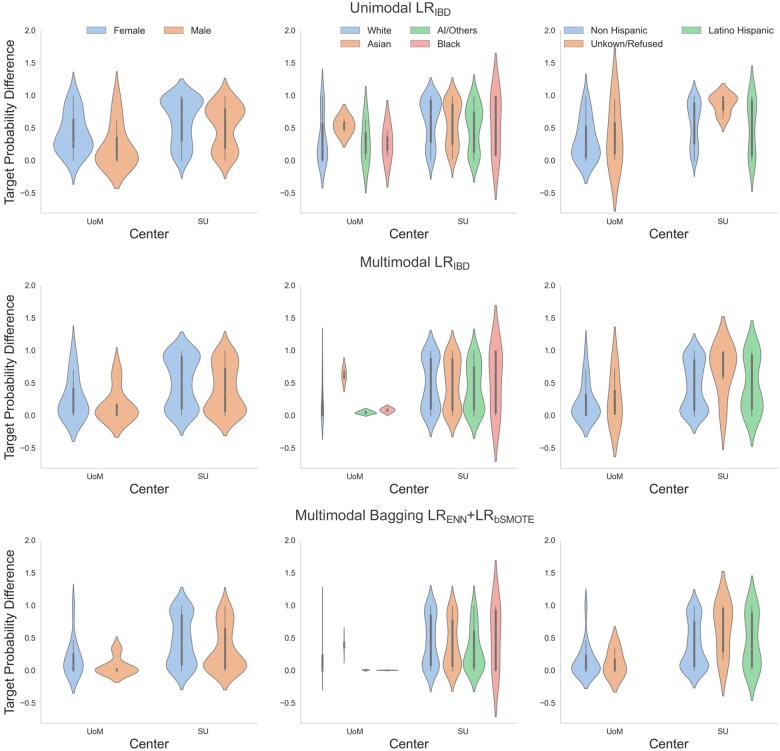
Materials and methods: This is a retrospective cross-sectional study involving 2 health systems- University of Michigan (UoM) and Stanford University (SU). It involves 1728 patients visiting eye clinics during 2012-2021. Free-text embeddings extracted using BioClinicalBERT were combined with SDE. EditedNearestNeighbor (ENN) undersampling and Borderline-Synthetic Minority Over-sampling Technique (bSMOTE) addressed class imbalance. Lasso Regression (LR), Random Forest (RF), Support Vector Classifier (SVC) models were trained on UoM imbalanced (imb) and resampled data along with bagging ensemble method. Models were externally validated with SU data. Fairness was assessed using equalized odds difference (EOD) and Target Probability Difference (TPD).
Results: Among 900 and 828 patients from UoM and SU, 10% and 23% respectively had glaucoma as confirmed by ophthalmologists. At UoM, multimodal LRimb (F1 = 76.60 [61.90-88.89]; AUROC = 95.41 [87.01-99.63]) outperformed unimodal RFimb (F1 = 69.77 [52.94-83.64]; AUROC = 97.72 [95.95-99.18]) and ICD-coding method (F1 = 53.01 [39.51-65.43]; AUROC = 90.10 [84.59-93.93]). Bagging (BM = LRENN + LRbSMOTE) improved performance achieving an F1 of 83.02 [70.59-92.86] and AUROC of 97.59 [92.98-99.88]. During external validation BM achieved the highest F1 (68.47 [62.61-73.75]), outperforming unimodal (F1 = 51.26 [43.80-58.13]) and multimodal LRimb (F1 = 62.46 [55.95-68.24]). BM EOD revealed lower disparities for sex (<0.1), race (<0.5) and ethnicity (<0.5), and had least uncertainty using TDP analysis as compared to traditional models.
Discussion: Multimodal ensemble models integrating structured and unstructured EHR data outperformed traditional SDE models achieving fair predictions across demographic sub-groups. Among ensemble methods, bagging demonstrated better generalizability than stacking, particularly when training data is limited.
Conclusion: This approach can enhance phenotype discovery to enable future research studies using RWD, leading to better patient management and clinical outcomes.
Keywords: class imbalance; clinical notes; ensemble learning; generalizability and fairness; real-world data.
© The Author(s) 2025. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Conflict of interest statement
None declared.
Figures


References
-
- Welvaars K, Oosterhoff JHF, van den Bekerom MPJ, et al. ; OLVG Urology Consortium, and the Machine Learning Consortium. Implications of resampling data to address the class imbalance problem (IRCIP): an evaluation of impact on performance between classification algorithms in medical data. JAMIA Open. 2023;6:ooad033. 10.1093/jamiaopen/ooad033 - DOI - PMC - PubMed
LinkOut - more resources
Full Text Sources