

Exploration of potential biomarkers and immune cell infiltration characteristics for peripheral atherosclerosis in sjögren's syndrome based on comprehensive bioinformatics analysis and machine learning
- PMID: 40809841
- PMCID: PMC12343227
- DOI: 10.3389/fgene.2025.1546315
Exploration of potential biomarkers and immune cell infiltration characteristics for peripheral atherosclerosis in sjögren's syndrome based on comprehensive bioinformatics analysis and machine learning
Abstract
Background: Sjögren's syndrome (SS) is an autoimmune disorder impacting exocrine glands, while peripheral atherosclerosis (PA) demonstrates a close link to inflammation. Despite a notable rise in atherosclerosis risk among SS patients in prior investigations, the precise mechanisms remain elusive.
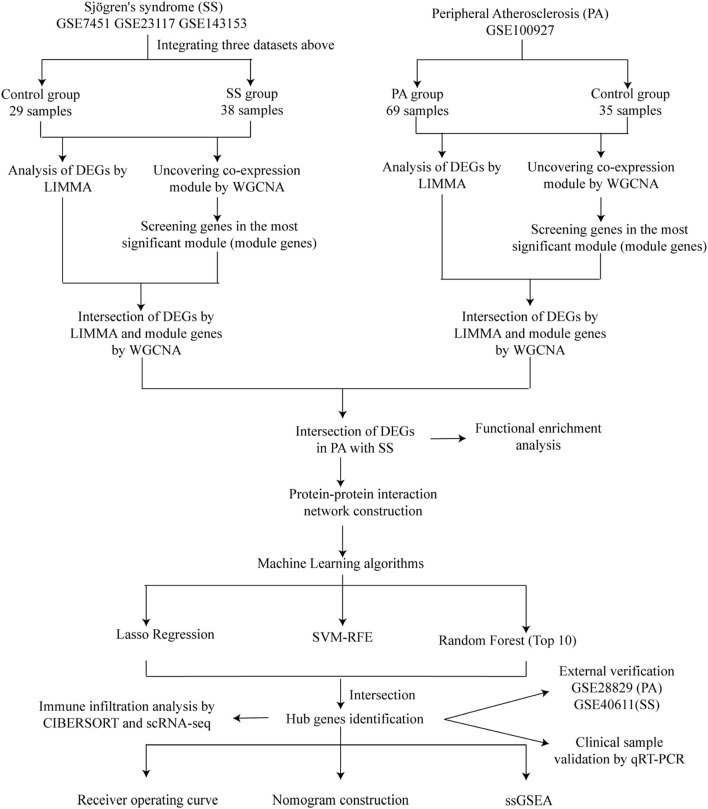
Methods: A comprehensive analysis was conducted on seven microarray datasets (GSE7451, GSE23117, GSE143153, GSE28829, GSE100927, GSE159677, and GSE40611). The LIMMA package, in conjunction with weighted gene co-expression network analysis (WGCNA), provides a robust method for identifying differentially expressed genes (DEGs) associated with peripheral atherosclerosis (PA) in Sjögren's syndrome (SS). Subsequently, machine learning algorithms and protein-protein interaction (PPI) network analysis were employed to further investigate potential predictive genes. These findings were utilized to construct a nomogram and a receiver operating characteristic (ROC) curve, which assessed the predictive accuracy of these genes in PA patients with SS. Additionally, extensive analyses of immune cell infiltration and single-sample gene set enrichment analysis (ssGSEA) were conducted to elucidate the underlying biological mechanisms.
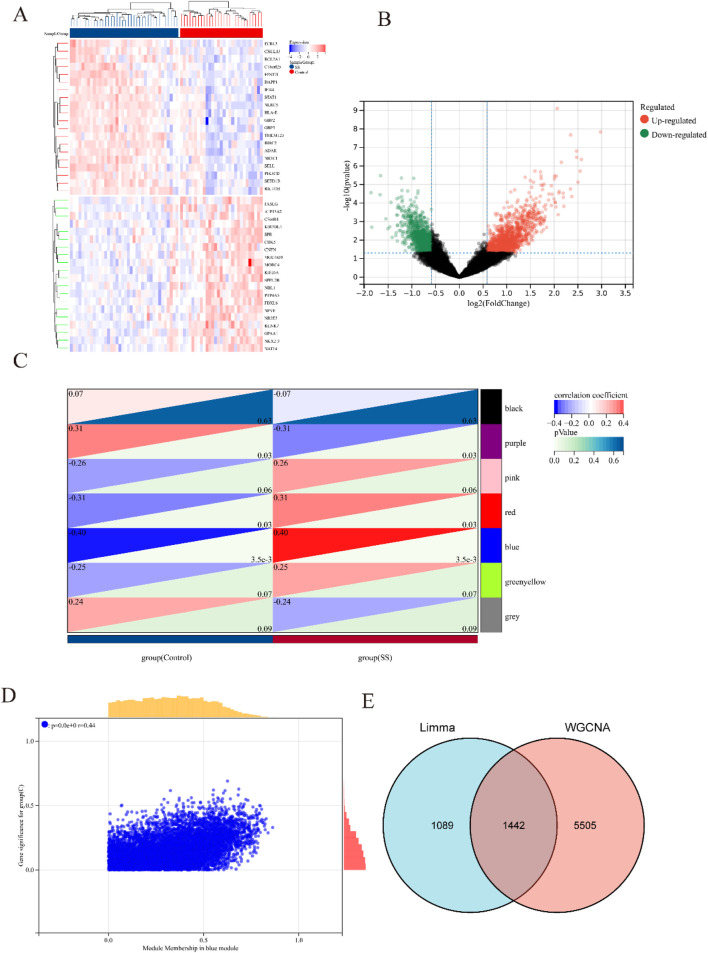
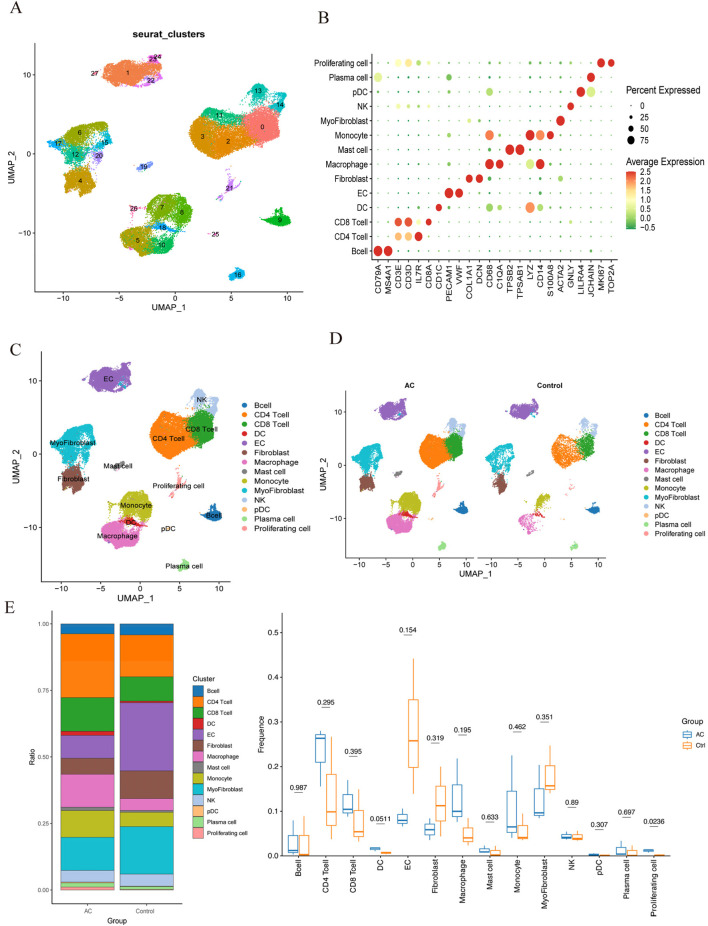
Results: Using the LIMMA package and WGCNA, 135 DEGs associated with PA in SS were identified. PPI network analysis revealed 17 candidate hub genes. The intersection of gene sets identified by three distinct machine learning algorithms highlighted CCL4, CSF1R, and MX1 as key DEGs. ROC analysis and nomogram construction demonstrated their high predictive accuracy (AUC: 0.971, 95% CI: 0.941-1.000). Analysis of immune cell infiltration showed a significant positive correlation between these hub genes and dysregulated immune cells. Additionally, ssGSEA provided critical biological insights into the progression of PA in SS.
Conclusion: This study systematically identified three promising hub genes (CCL4, CSF1R, and MX1) and developed a nomogram for predicting PA in SS. Analysis of immune cell infiltration demonstrated that dysregulated immune cells significantly contribute to the progression of PA. Additionally, ssGSEA analysis offered important insights into the mechanisms by which SS leads to PA.
Keywords: Sjögren’s syndrome; bioinformatics analysis; biomarkers; immune infiltration; machine learning; peripheral atherosclerosis.
Copyright © 2025 Liu, Wang, Zhou, Cai, Tang, Wang and Zhang.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures






References
LinkOut - more resources
Full Text Sources
Miscellaneous