

Inner speech in motor cortex and implications for speech neuroprostheses
- PMID: 40816265
- PMCID: PMC12360486
- DOI: 10.1016/j.cell.2025.06.015
Inner speech in motor cortex and implications for speech neuroprostheses
Abstract
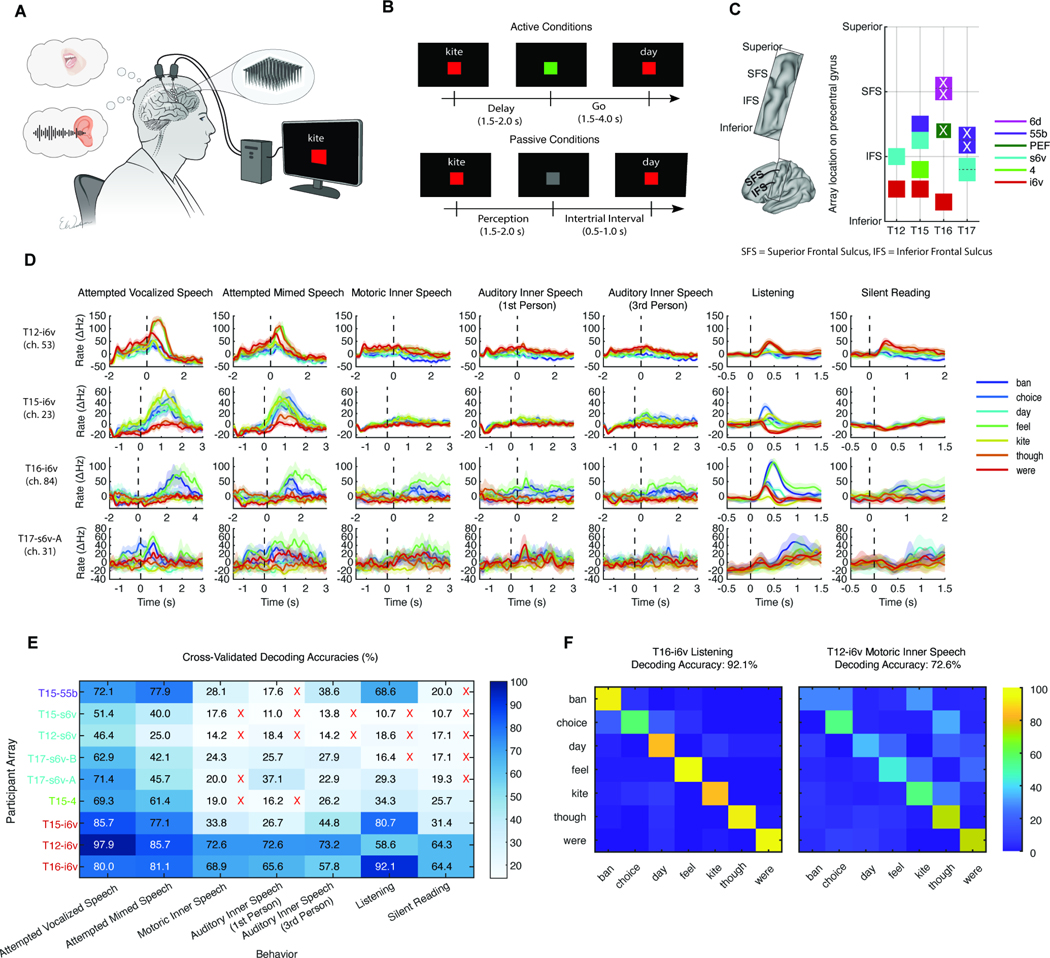
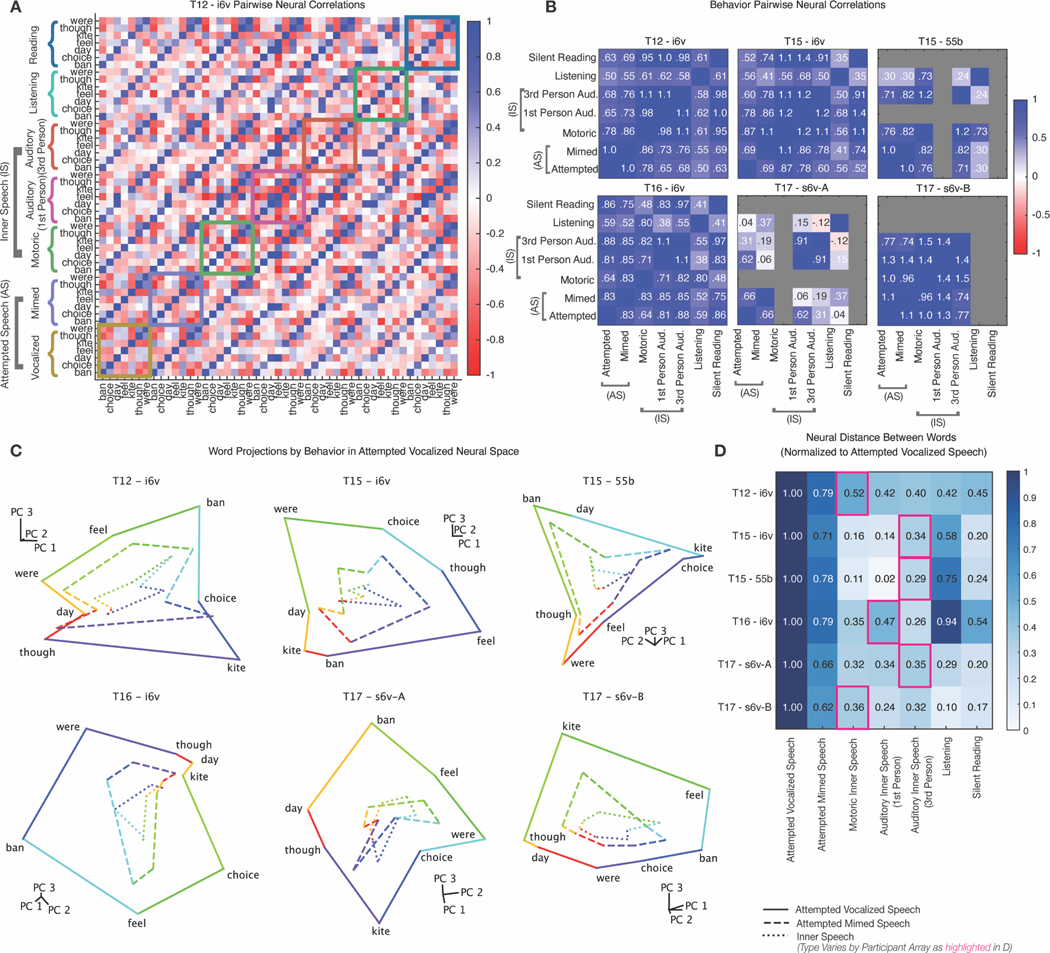
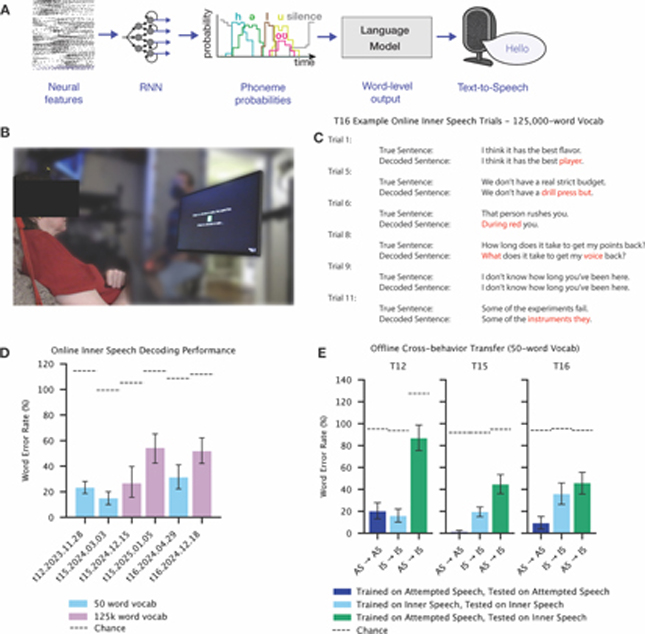
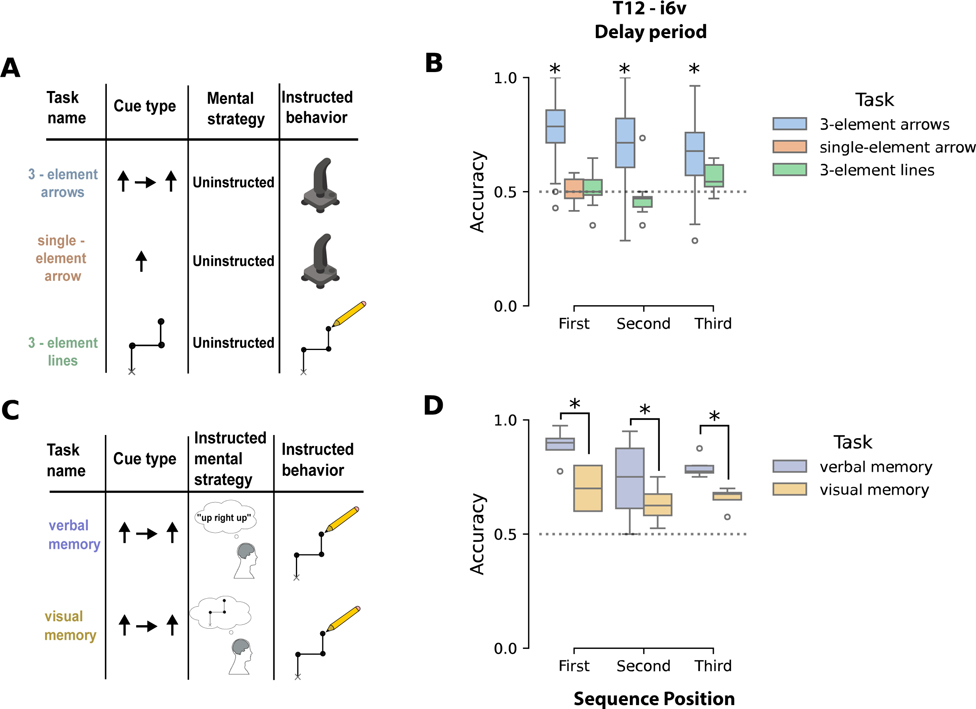
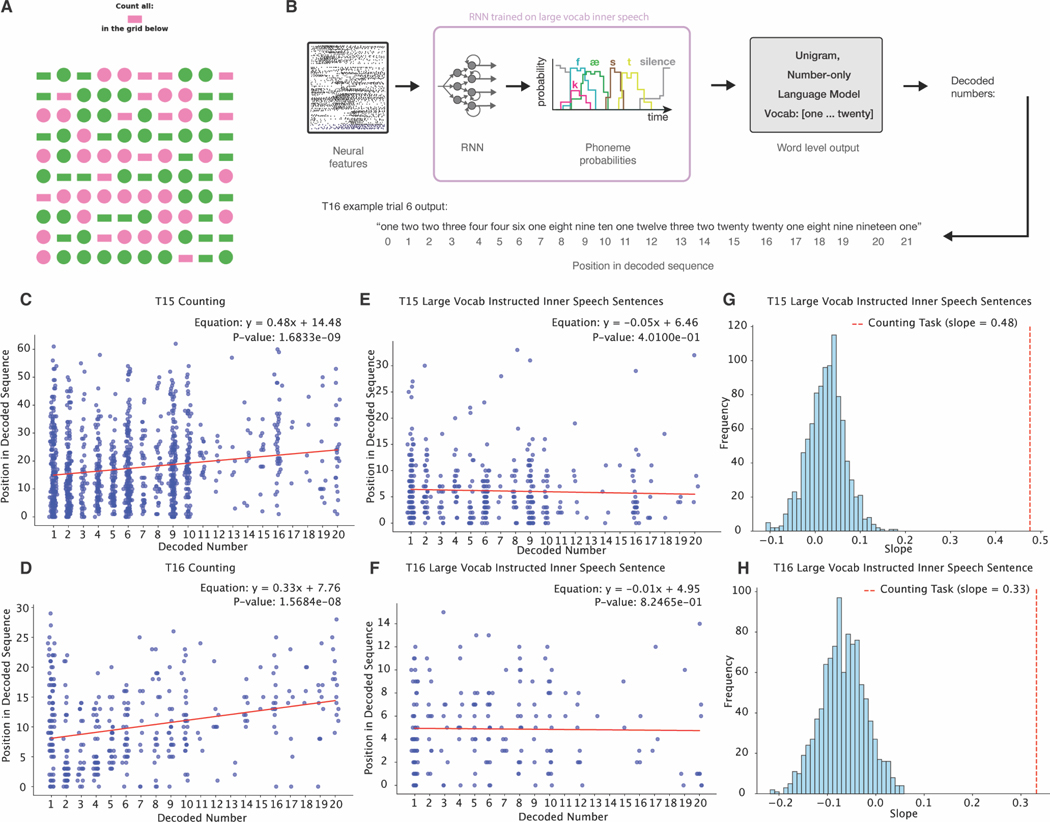
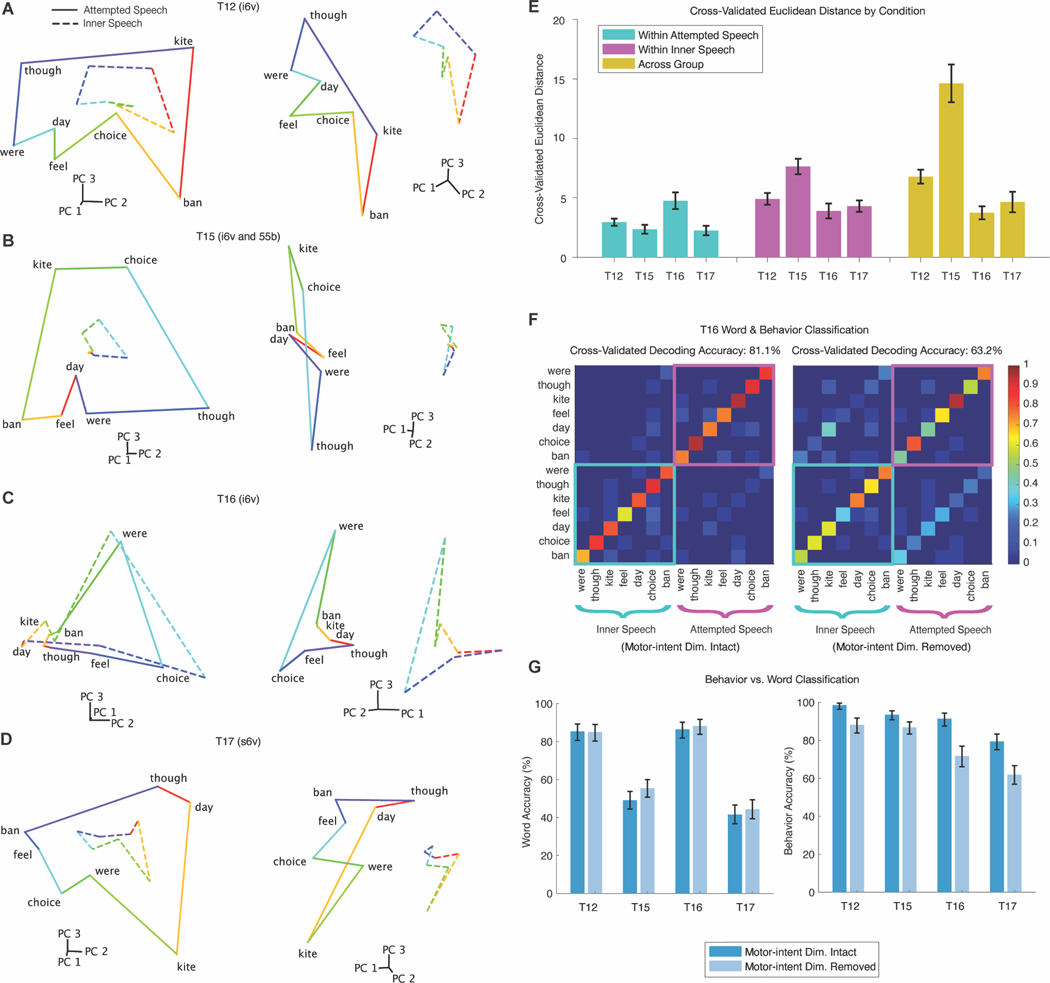
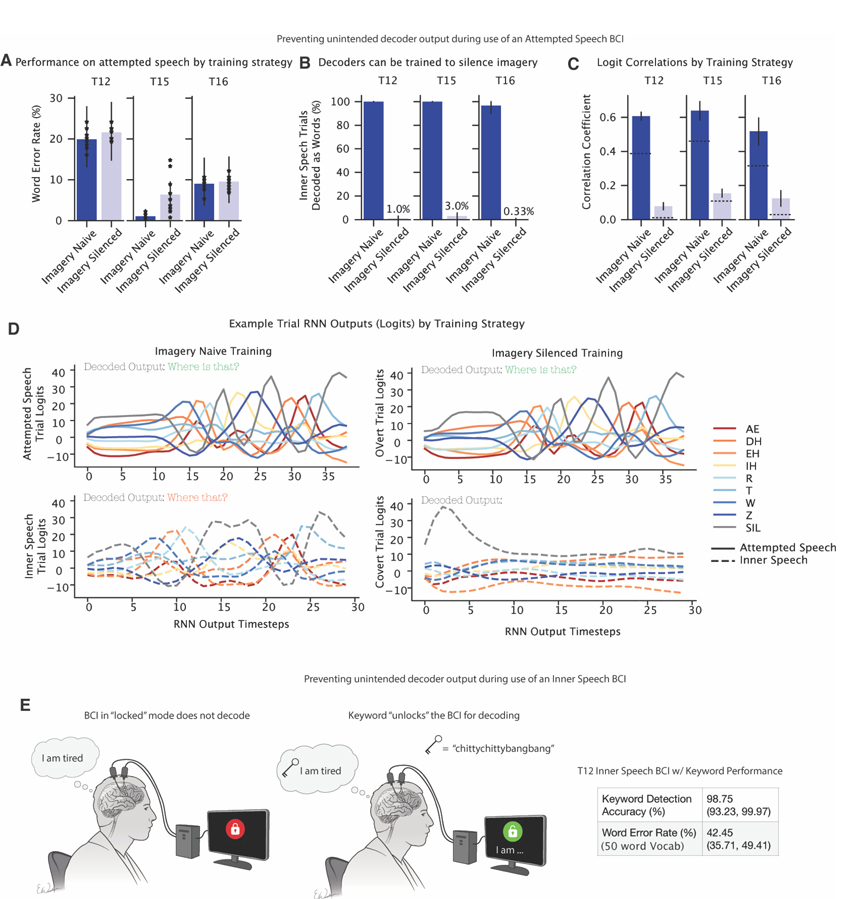
Speech brain-computer interfaces (BCIs) show promise in restoring communication to people with paralysis but have also prompted discussions regarding their potential to decode private inner speech. Separately, inner speech may be a way to bypass the current approach of requiring speech BCI users to physically attempt speech, which is fatiguing and can slow communication. Using multi-unit recordings from four participants, we found that inner speech is robustly represented in the motor cortex and that imagined sentences can be decoded in real time. The representation of inner speech was highly correlated with attempted speech, though we also identified a neural "motor-intent" dimension that differentiates the two. We investigated the possibility of decoding private inner speech and found that some aspects of free-form inner speech could be decoded during sequence recall and counting tasks. Finally, we demonstrate high-fidelity strategies that prevent speech BCIs from unintentionally decoding private inner speech.
Keywords: brain-computer interface; covert speech; inner speech; motor cortex; speech neuroprosthesis.
Copyright © 2025 The Authors. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests The MGH Translational Research Center has a clinical research support agreement (CRSA) with Axoft, Neuralink, Neurobionics, Paradromics, Precision Neuro, Synchron, and Reach Neuro, for which L.R.H. provides consultative input. L.R.H. is a non-compensated member of the Board of Directors of a nonprofit assistive communication device technology foundation (Speak Your Mind Foundation). Mass General Brigham (MGB) is convening the Implantable Brain-Computer Interface Collaborative Community (iBCI-CC). Charitable gift agreements to MGB, including those received to date from Paradromics, Synchron, Precision Neuro, Neuralink, and Blackrock Neurotech, support the iBCI-CC, for which L.R.H. provides effort. S.D.S. is an inventor on intellectual property licensed by Stanford University to Blackrock Neurotech and Neuralink Corp. He is an advisor to Sonera. He also has equity in Wispr.ai. C.P. is an employee at Meta (Reality Labs). D.M.B. is a surgical consultant for Paradromics Inc. D.M.B. and D.B.R. are principal investigators for the Connexus BCI clinical trial for a Paradromics Inc. clinical product. S.D.S. and D.M.B. are inventors of intellectual property related to speech neuroprostheses owned by the University of California, Davis that has been licensed to a neurotechnology startup. J.M.H. is a consultant for Paradromics, serves on the Medical Advisory Board of Enspire DBS, and is a shareholder in Maplight Therapeutics. He is also the co-founder of Re-EmergeDBS. He is also an inventor on intellectual property licensed by Stanford University to Blackrock Neurotech and Neuralink Corp. F.R.W. is an inventor on intellectual property licensed by Stanford University to Blackrock Neurotech and Neuralink Corp.
Figures
References
-
- Brown CML (2024). Neurorights, mental privacy, and mind reading. Neuroethics 17. 10.1007/s12152-024-09568-z. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
