

A feedforward mechanism for human-like contour integration
- PMID: 40825057
- PMCID: PMC12370188
- DOI: 10.1371/journal.pcbi.1013391
A feedforward mechanism for human-like contour integration
Abstract
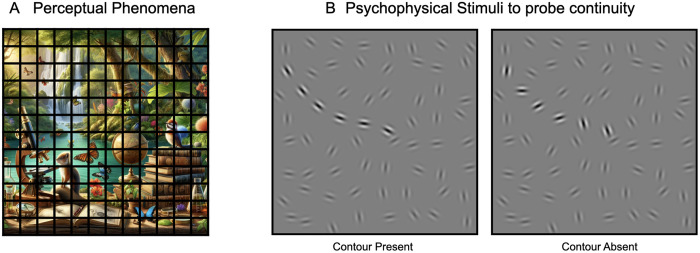
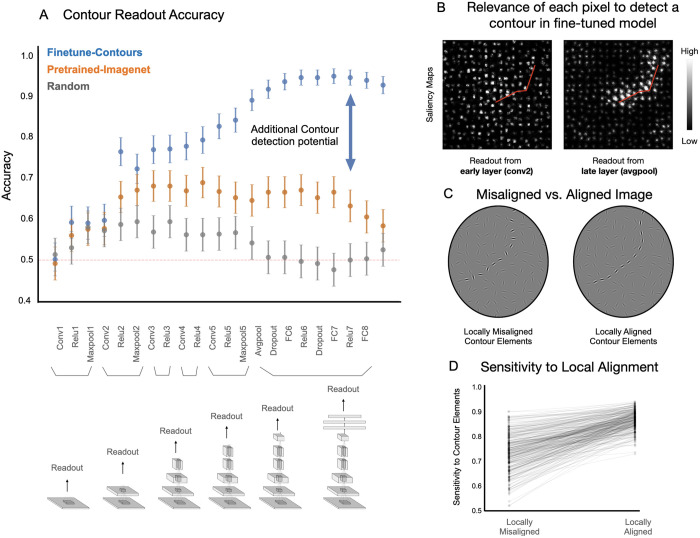
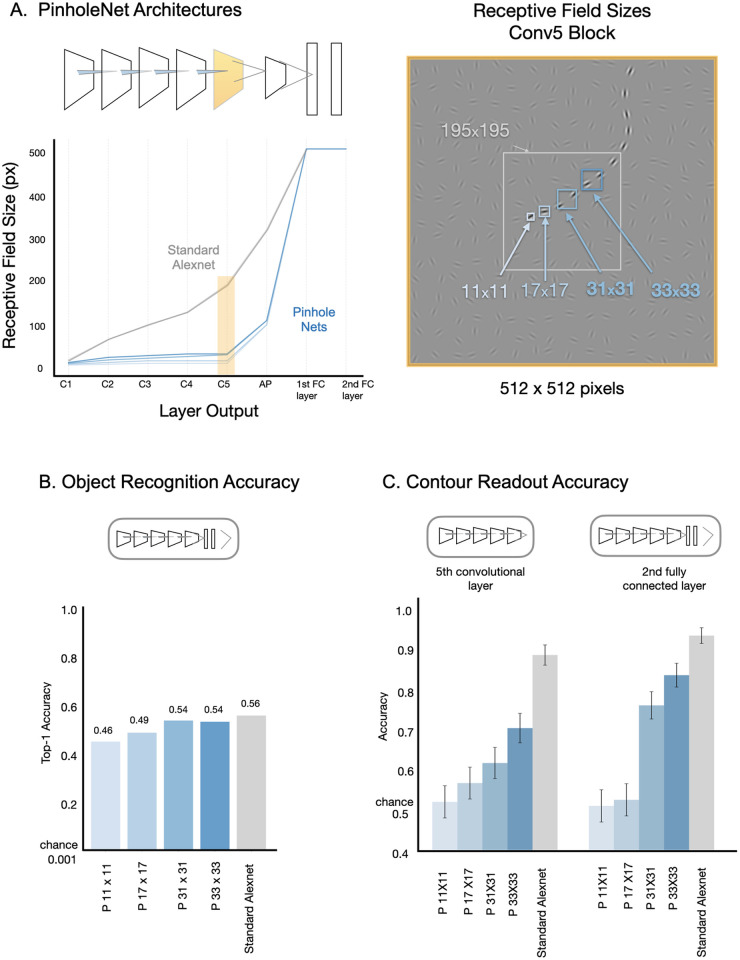
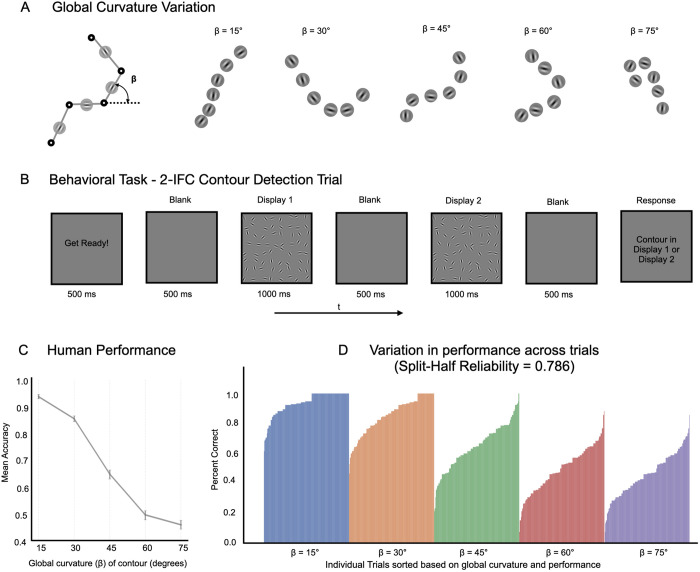
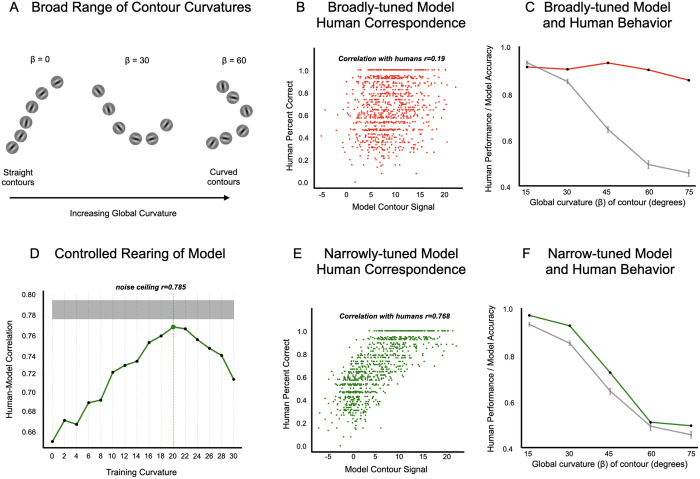
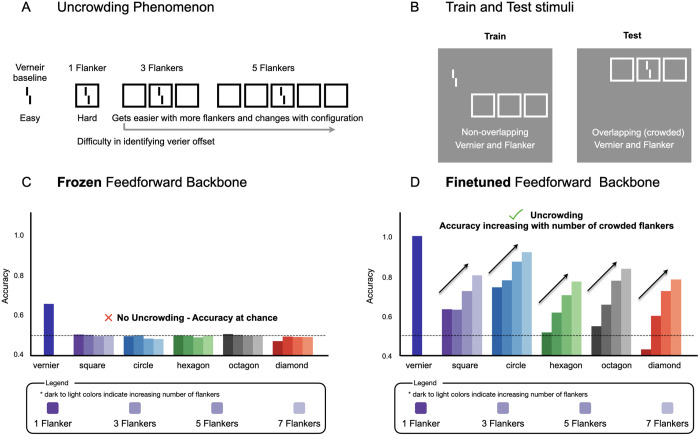
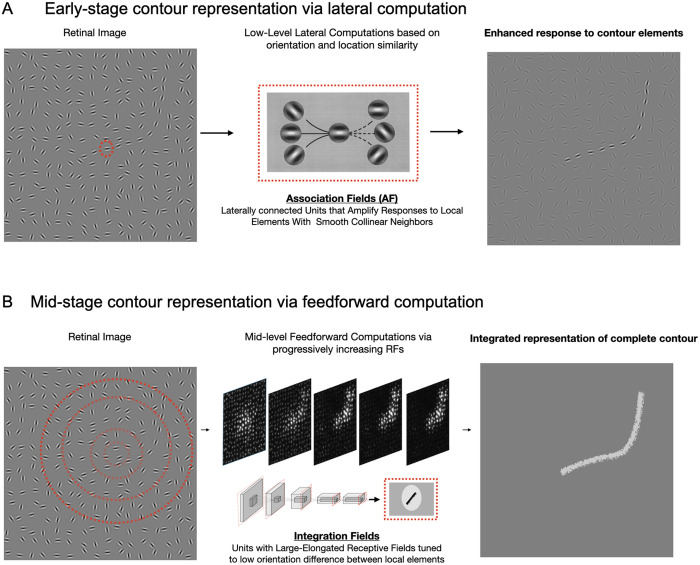
Deep neural network models provide a powerful experimental platform for exploring core mechanisms underlying human visual perception, such as perceptual grouping and contour integration-the process of linking local edge elements to arrive at a unified perceptual representation of a complete contour. Here, we demonstrate that feedforward convolutional neural networks (CNNs) fine-tuned on contour detection show this human-like capacity, but without relying on mechanisms proposed in prior work, such as lateral connections, recurrence, or top-down feedback. We identified two key properties needed for ImageNet pre-trained, feed-forward models to yield human-like contour integration: first, progressively increasing receptive field structure served as a critical architectural motif to support this capacity; and second, biased fine-tuning for contour-detection specifically for gradual curves (~20 degrees) resulted in human-like sensitivity to curvature. We further demonstrate that fine-tuning ImageNet pretrained models uncovers other hidden human-like capacities in feed-forward networks, including uncrowding (reduced interference from distractors as the number of distractors increases), which is considered a signature of human perceptual grouping. Thus, taken together these results provide a computational existence proof that purely feedforward hierarchical computations are capable of implementing gestalt "good continuation" and perceptual organization needed for human-like contour-integration and uncrowding. More broadly, these results raise the possibility that in human vision, later stages of processing play a more prominent role in perceptual-organization than implied by theories focused on recurrence and early lateral connections.
Copyright: © 2025 Doshi et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist
Figures
Similar articles
-
Short-Term Memory Impairment.2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. 2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. PMID: 31424720 Free Books & Documents.
-
Prescription of Controlled Substances: Benefits and Risks.2025 Jul 6. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. 2025 Jul 6. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. PMID: 30726003 Free Books & Documents.
-
Modeling the Role of Contour Integration in Visual Inference.Neural Comput. 2023 Dec 12;36(1):33-74. doi: 10.1162/neco_a_01625. Neural Comput. 2023. PMID: 38052088
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
-
The quantity, quality and findings of network meta-analyses evaluating the effectiveness of GLP-1 RAs for weight loss: a scoping review.Health Technol Assess. 2025 Jun 25:1-73. doi: 10.3310/SKHT8119. Online ahead of print. Health Technol Assess. 2025. PMID: 40580049 Free PMC article.
Cited by
-
RTify: Aligning Deep Neural Networks with Human Behavioral Decisions.ArXiv [Preprint]. 2024 Dec 26:arXiv:2411.03630v2. ArXiv. 2024. PMID: 39764401 Free PMC article. Preprint.
References
-
- Nakayama K, He ZJ, Shimojo S. Visual surface representation: A critical link between lower-level and higher-level vision. 1995.
MeSH terms
LinkOut - more resources
Full Text Sources
