

Multivariate genome-wide association analysis of dyslexia and quantitative reading skill improves gene discovery
- PMID: 40825760
- PMCID: PMC12361447
- DOI: 10.1038/s41398-025-03514-0
Multivariate genome-wide association analysis of dyslexia and quantitative reading skill improves gene discovery
Abstract
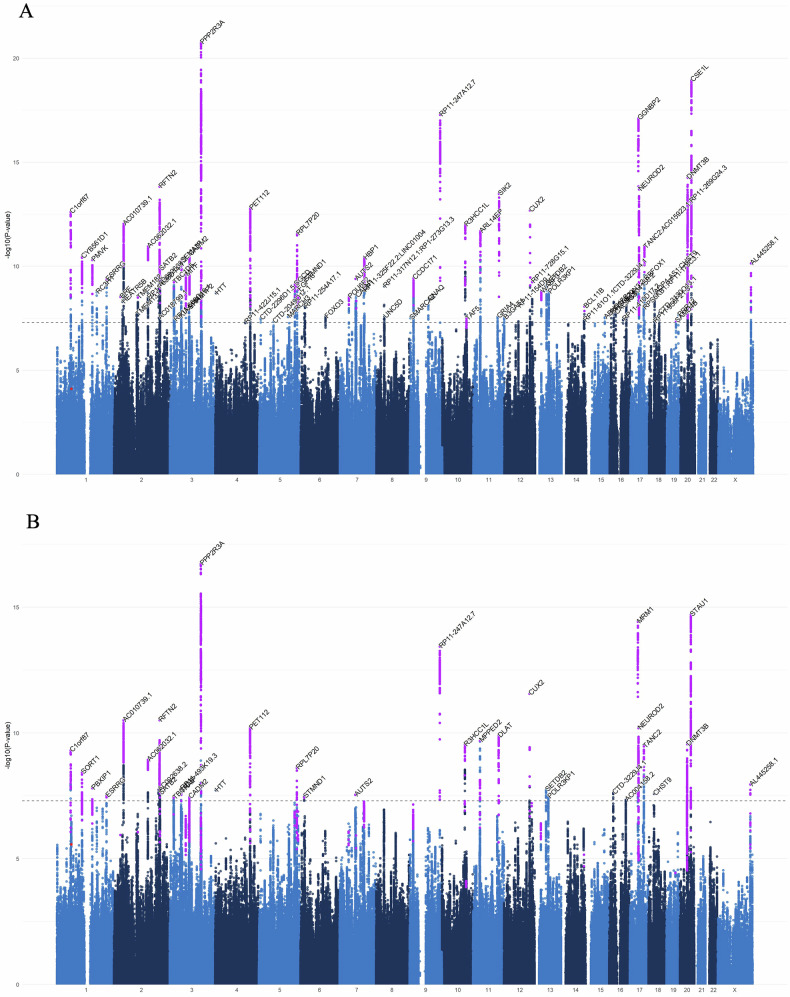
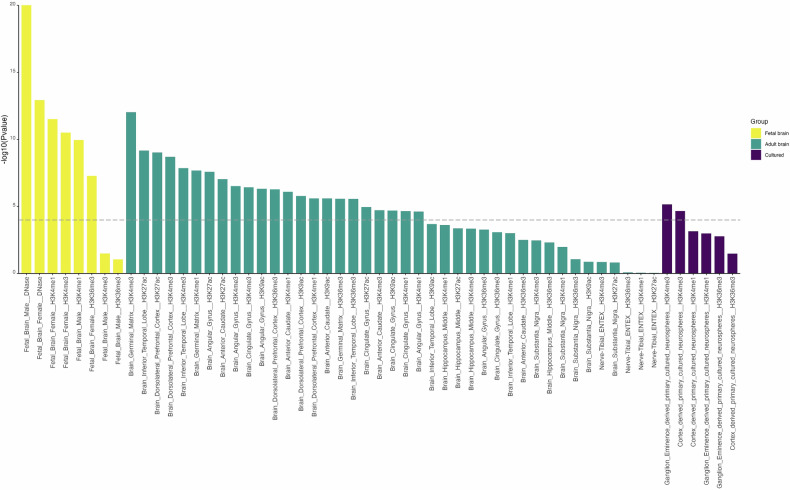
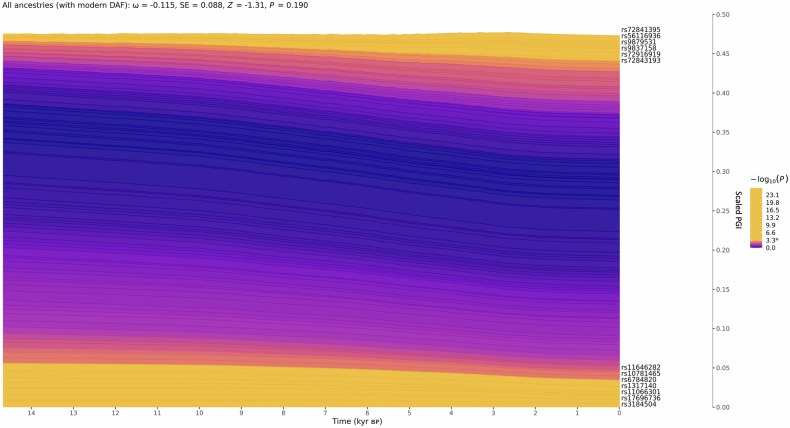
The ability to read is an important life skill and a major route to education. Dyslexia, characterized by difficulties with accurate/ fluent word reading, and poor spelling is influenced by genetic variation, with a twin study heritability estimate of 0.4-0.6. Until recently, genomic investigations were limited by modest sample size. We used a multivariate genome-wide association study (GWAS) method, MTAG, to leverage summary statistics from two independent GWAS efforts, boosting power for analyses of dyslexia; the GenLang meta-analysis of word reading (N = 27,180) and the 23andMe, Inc., study of dyslexia (Ncases = 51,800, Ncontrols = 1,087,070). We increased the effective sample size to 1,228,832 participants, representing the largest genetic study of reading-related phenotypes to date. Our analyses identified 80 independent genome-wide significant loci, including 36 regions which were not previously reported as significant. Of these 36 loci, 13 were novel regions with no prior association with dyslexia. We observed clear genetic correlations with cognitive and educational measures. Gene-set analyses revealed significant enrichment of dyslexia-associated genes in four neuronal biological process pathways, and findings were further supported by enrichment of neuronally expressed genes in the developing embryonic brain. Polygenic index analysis of our multivariate results predicted between 2.34-4.73% of variance in reading traits in an independent sample, the National Child Development Study cohort (N = 6410). Polygenic adaptation was examined using a large panel of ancient genomes spanning the last ~15 k years. We did not find evidence of selection, suggesting that dyslexia has not been subject to recent selection pressure in Europeans. By combining existing datasets to improve statistical power, these results provide novel insights into the biology of dyslexia.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: PF, AA and the 23andMe Research Team are employed by and hold stock or stock options in 23andMe, Inc. All other authors declare no conflicts of interest. Ethics approval and consent to participate: The study made use of existing data sets with all original studies stating relevant ethical approval and informed consent from participants. Ethical approval for this study was granted by the University of Edinburgh School of Philosophy, Psychology and Language Sciences research ethics committee (PPLSREC 29-1819/8), and was carried out in accordance with the principles of the Declaration of Helsinki.
Figures


References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
