

Progressive decomposition of infrared and visible image fusion network with joint transformer and Resnet
- PMID: 40844972
- PMCID: PMC12373181
- DOI: 10.1371/journal.pone.0330328
Progressive decomposition of infrared and visible image fusion network with joint transformer and Resnet
Abstract
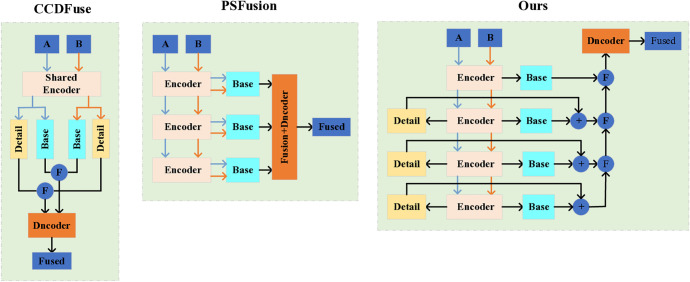
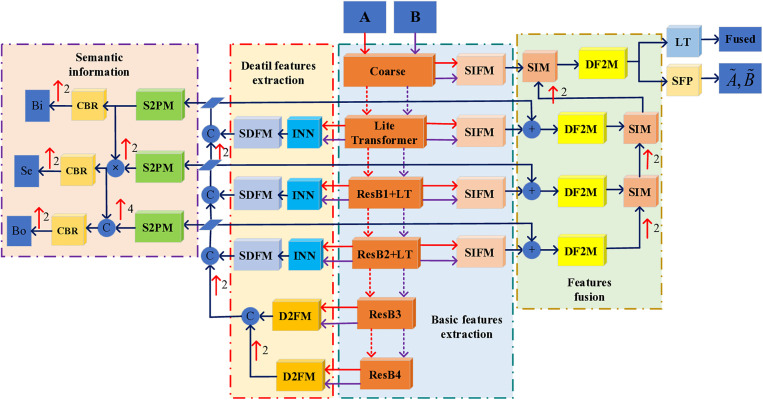
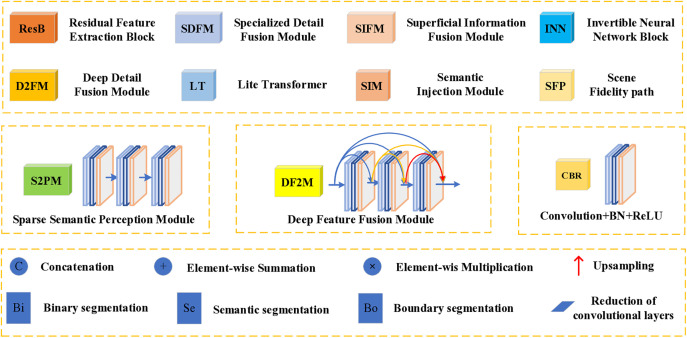
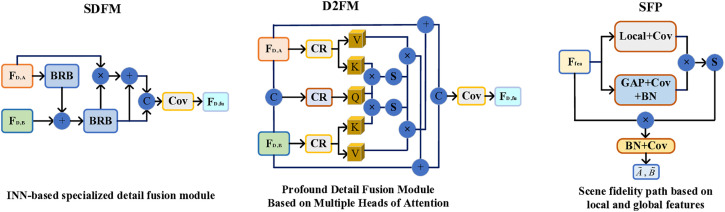
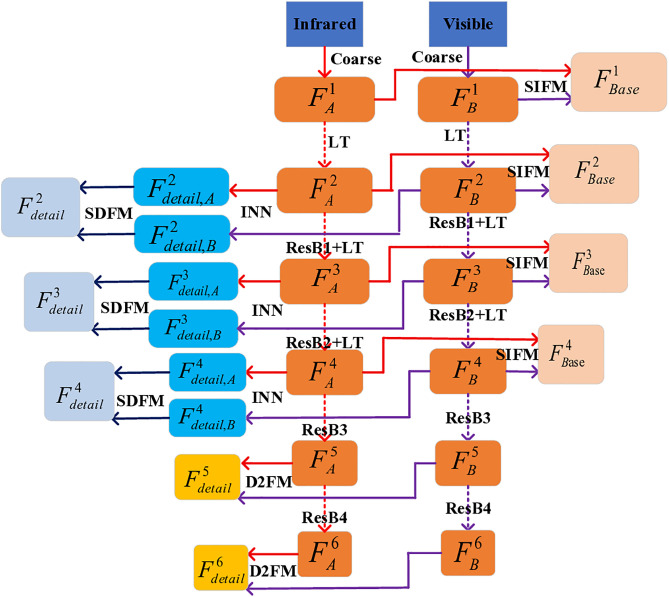
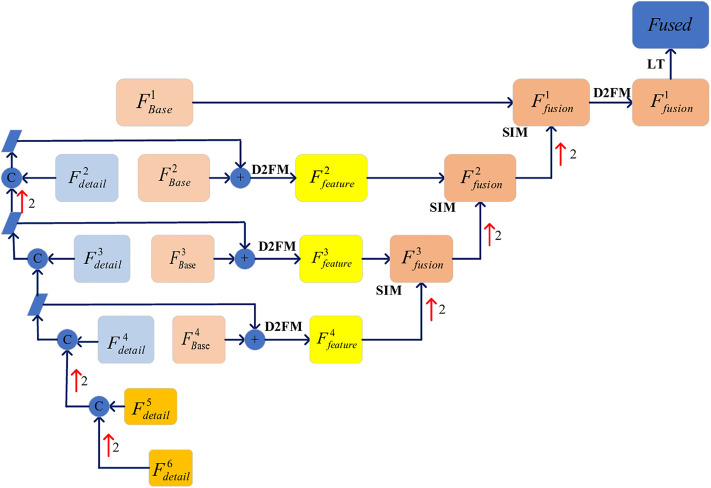
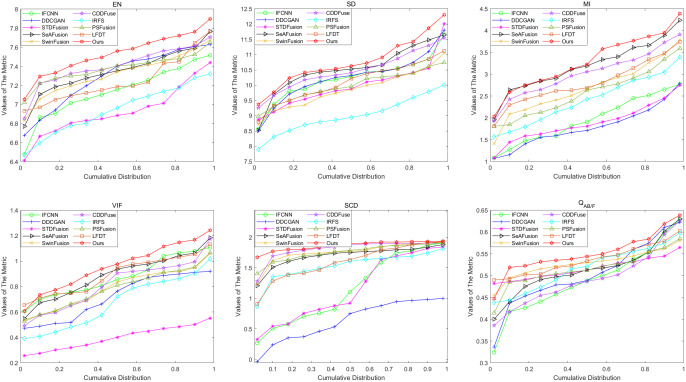
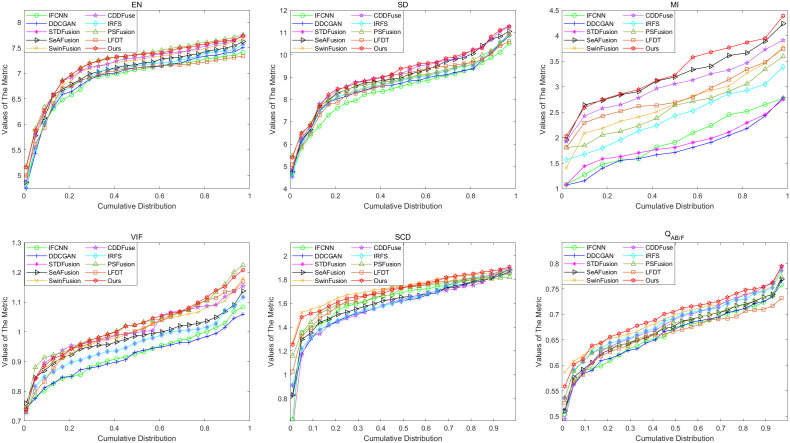
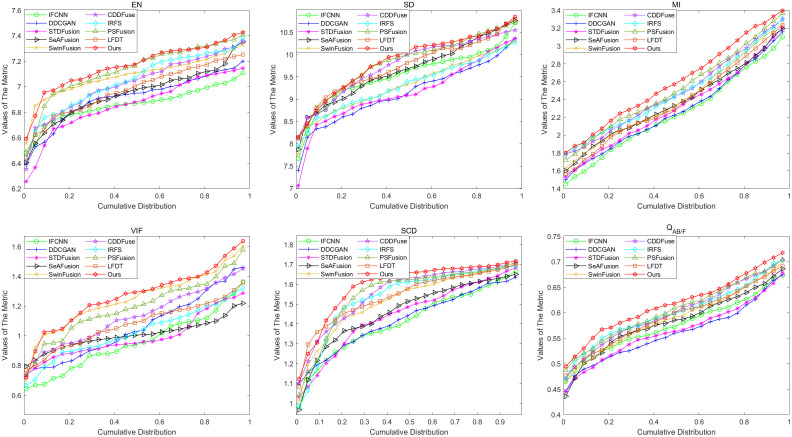
The objective of image fusion is to synthesize information from multiple source images into a single, high-quality composite that is information-rich, thereby enhancing both human visual interpretation and machine perception capabilities. This process also establishes a robust foundation for downstream image-related tasks. Nevertheless, current deep learning-based networks frequently neglect the distinctive features inherent in source images, presenting challenges in effectively balancing the interplay between basic and detailed features. To tackle this limitation, we introduce a progressive decomposition network that integrates Lite Transformer (LT) and ResNet architecture for infrared and visible image fusion (IVIF). Our methodology unfolds in three principal stages: Initially, a foundational convolutional neural network (CNN) is deployed to extract coarse-scale features from the source images. Subsequently, the LT is employed to bifurcate these coarse features into basic and detailed feature components. In the second phase, to augment the detail information across various inter-layer extractions, we substitute the conventional ResNet preprocessing with a combination of coarse and LT module. Cascade LT operations are implemented following the initial two ResNet blocks (ResB), enabling two-branch feature extraction from these reconfigured blocks. The final stage involves the design of specialized fusion sub-networks to process the basic and detail information blocks extracted from different layers. These processed image feature blocks are then channeled through semantic injection module (SIM) and Transformer decoders to generate the fused image. Complementing this architecture, we have developed a semantic information extraction module that aligns with the progressive inter-layer detail extraction framework. The LT module is strategically embedded within the ResNet network architecture to optimize the extraction of both basic and detailed features across diverse layers. Moreover, we introduce a novel correlation loss function that operates on the basic and detail information between layers, facilitating the correlation of basic features while maintaining the independence of detail features across layers. Through comprehensive qualitative and quantitative analyses conducted on multiple infrared-visible datasets, we demonstrate the superior potential of our proposed network for advanced visual tasks. Our network exhibits remarkable performance in detail extraction, significantly outperforming existing deep learning methodologies in this domain.
Copyright: © 2025 Zhu, Liu. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures







Similar articles
-
Short-Term Memory Impairment.2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. 2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. PMID: 31424720 Free Books & Documents.
-
A novel deep learning framework for retinal disease detection leveraging contextual and local features cues from retinal images.Med Biol Eng Comput. 2025 Jul;63(7):2029-2046. doi: 10.1007/s11517-025-03314-0. Epub 2025 Feb 7. Med Biol Eng Comput. 2025. PMID: 39918766
-
TLTNet: A novel transscale cascade layered transformer network for enhanced retinal blood vessel segmentation.Comput Biol Med. 2024 Aug;178:108773. doi: 10.1016/j.compbiomed.2024.108773. Epub 2024 Jun 25. Comput Biol Med. 2024. PMID: 38925090
-
A systematic review on feature extraction methods and deep learning models for detection of cancerous lung nodules at an early stage -the recent trends and challenges.Biomed Phys Eng Express. 2024 Nov 20;11(1). doi: 10.1088/2057-1976/ad9154. Biomed Phys Eng Express. 2024. PMID: 39530659
-
Systemic pharmacological treatments for chronic plaque psoriasis: a network meta-analysis.Cochrane Database Syst Rev. 2020 Jan 9;1(1):CD011535. doi: 10.1002/14651858.CD011535.pub3. Cochrane Database Syst Rev. 2020. Update in: Cochrane Database Syst Rev. 2021 Apr 19;4:CD011535. doi: 10.1002/14651858.CD011535.pub4. PMID: 31917873 Free PMC article. Updated.
References
-
- Xiao G, Bavirisetti DP, Liu G, Zhang X. Image Fusion. Springer; 2020.
-
- Paramanandham N, Rajendiran K. Infrared and visible image fusion using discrete cosine transform and swarm intelligence for surveillance applications. Infrared Physics & Technology. 2018;88:13–22. doi: 10.1016/j.infrared.2017.11.006 - DOI
-
- Bogdoll D, Nitsche M, Zöllner JM. Anomaly detection in autonomous driving: A survey. In: IEEE Conference on Computer Vision and Pattern Recognition. 2022. 4488–99.
-
- Zhang P, Wang D, Lu H, Yang X. Learning Adaptive Attribute-Driven Representation for Real-Time RGB-T Tracking. Int J Comput Vis. 2021;129(9):2714–29. doi: 10.1007/s11263-021-01495-3 - DOI
-
- Zhang H, Xu H, Xiao Y, Guo X, Ma J. Rethinking the Image Fusion: A Fast Unified Image Fusion Network based on Proportional Maintenance of Gradient and Intensity. AAAI. 2020;34(07):12797–804. doi: 10.1609/aaai.v34i07.6975 - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
