

Quality and efficiency of integrating customised large language model-generated summaries versus physician-written summaries: a validation study
- PMID: 40908007
- PMCID: PMC12414186
- DOI: 10.1136/bmjopen-2025-099301
Quality and efficiency of integrating customised large language model-generated summaries versus physician-written summaries: a validation study
Abstract
Objectives: To compare the quality and time efficiency of physician-written summaries with customised large language model (LLM)-generated medical summaries integrated into the electronic health record (EHR) in a non-English clinical environment.
Design: Cross-sectional non-inferiority validation study.
Setting: Tertiary academic hospital.
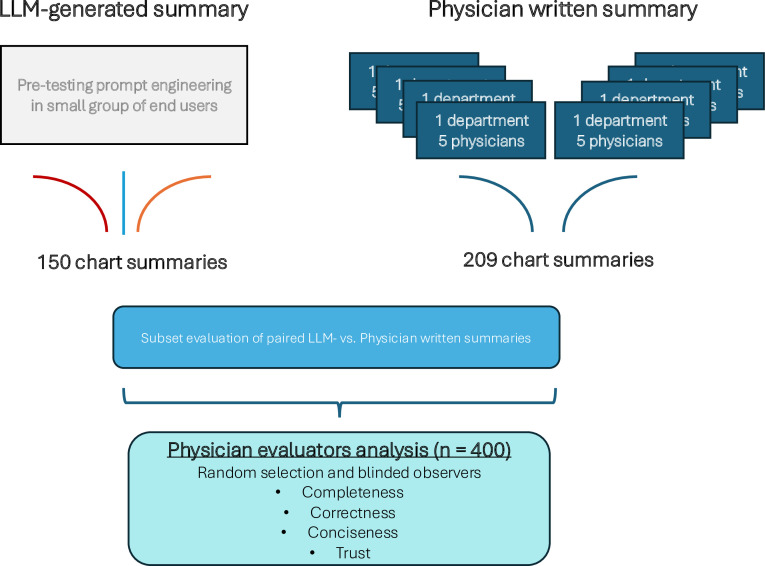
Participants: 52 physicians from 8 specialties at a large Dutch academic hospital participated, either in writing summaries (n=42) or evaluating them (n=10).
Interventions: Physician writers wrote summaries of 50 patient records. LLM-generated summaries were created for the same records using an EHR-integrated LLM. An independent, blinded panel of physician evaluators compared physician-written summaries to LLM-generated summaries.
Primary and secondary outcome measures: Primary outcome measures were completeness, correctness and conciseness (on a 5-point Likert scale). Secondary outcomes were preference and trust, and time to generate either the physician-written or LLM-generated summary.
Results: The completeness and correctness of LLM-generated summaries did not differ significantly from physician-written summaries. However, LLM summaries were less concise (3.0 vs 3.5, p=0.001). Overall evaluation scores were similar (3.4 vs 3.3, p=0.373), with 57% of evaluators preferring LLM-generated summaries. Trust in both summary types was comparable, and interobserver variability showed excellent reliability (intraclass correlation coefficient 0.975). Physicians took an average of 7 min per summary, while LLMs completed the same task in just 15.7 s.
Conclusions: LLM-generated summaries are comparable to physician-written summaries in completeness and correctness, although slightly less concise. With a clear time-saving benefit, LLMs could help reduce clinicians' administrative burden without compromising summary quality.
Keywords: Artificial Intelligence; Electronic Health Records; Physicians.
© Author(s) (or their employer(s)) 2025. Re-use permitted under CC BY-NC. No commercial re-use. See rights and permissions. Published by BMJ Group.
Conflict of interest statement
Competing interests: None declared.
Figures


References
-
- OpenAI GPT-4 technical report. 2023. [25-Jul-2025]. https://cdn.openai.com/papers/gpt-4.pdf Available. Accessed.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources