

This is a preprint.
An Efficient Lasso Framework for Admixture-Aware Polygenic Scores
- PMID: 40909540
- PMCID: PMC12407912
- DOI: 10.1101/2025.08.26.671106
An Efficient Lasso Framework for Admixture-Aware Polygenic Scores
Abstract
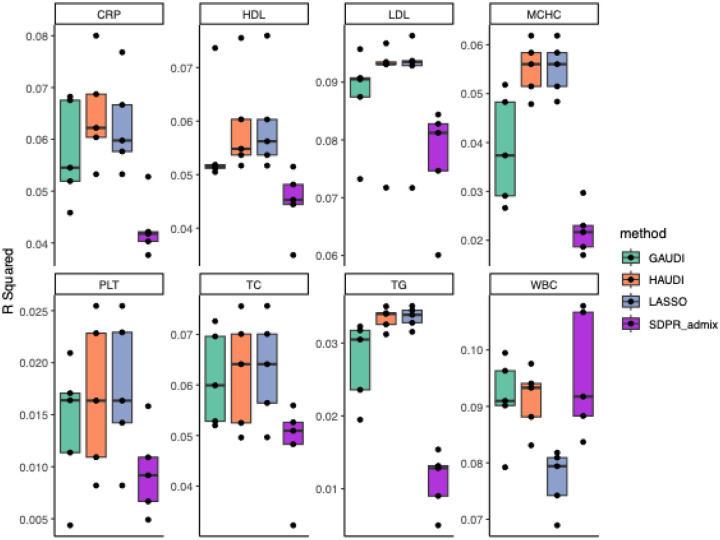
Polygenic scores (PGS) have promising clinical applications for risk stratification, disease screening, and personalized medicine. However, most PGS are trained on predominantly European ancestry cohorts and have limited portability to external populations. While cross-population PGS methods have demonstrated greater generalizability than single-ancestry PGS, they fail to properly account for individuals with recent admixture between continental ancestry groups. GAUDI is a recently proposed PGS method which overcomes this gap by leveraging local ancestry to estimate ancestry-specific effects, penalizing but allowing ancestry-differential effects. However, the modified fused LASSO approach used by GAUDI is computationally expensive and does not readily accommodate more than two-way admixture. To address these limitations, we introduce HAUDI, an efficient LASSO framework for admixed PGS construction. HAUDI re-parameterizes the GAUDI model as a standard LASSO problem, allowing for extension to multi-way admixture settings and far superior computational speed than GAUDI. In extensive simulations, HAUDI compares favorably to GAUDI while dramatically reducing computation time. In real data applications, HAUDI uniformly out-performs GAUDI across 18 clinical phenotypes, including total triglycerides (TG), C-reactive protein (CRP), and mean corpuscular hemoglobin concentration (MCHC), and shows substantial benefits over an ancestry-agnostic PGS for white blood cell count (WBC) and chronic kidney disease (CKD).
Figures







References
Publication types
Grants and funding
- HHSN268201300003I/HL/NHLBI NIH HHS/United States
- N01 HC065233/HL/NHLBI NIH HHS/United States
- N01 HC065236/HL/NHLBI NIH HHS/United States
- N01 HC065235/HL/NHLBI NIH HHS/United States
- 75N92021D00001/HL/NHLBI NIH HHS/United States
- N01 HC065234/HL/NHLBI NIH HHS/United States
- R01 HL151152/HL/NHLBI NIH HHS/United States
- 75N92021D00003/WH/WHI NIH HHS/United States
- R01 AR083790/AR/NIAMS NIH HHS/United States
- U01 HG011715/HG/NHGRI NIH HHS/United States
- HHSN268201300005C/HL/NHLBI NIH HHS/United States
- 75N92021D00002/HL/NHLBI NIH HHS/United States
- U01 HG007419/HG/NHGRI NIH HHS/United States
- HHSN268201300004C/HL/NHLBI NIH HHS/United States
- 75N92021D00005/WH/WHI NIH HHS/United States
- HHSN268201300001C/HL/NHLBI NIH HHS/United States
- U01 HG011720/HG/NHGRI NIH HHS/United States
- U24 AR076730/AR/NIAMS NIH HHS/United States
- HHSN268201300003C/HG/NHGRI NIH HHS/United States
- R01 HL146500/HL/NHLBI NIH HHS/United States
- N01 HC065237/HL/NHLBI NIH HHS/United States
- R01 HG010297/HG/NHGRI NIH HHS/United States
- 75N92021D00004/WH/WHI NIH HHS/United States
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous