

This is a preprint.
Proteomic prediction of disease largely reflects environmental risk exposure
- PMID: 40909825
- PMCID: PMC12407670
- DOI: 10.1101/2025.08.27.25334571
Proteomic prediction of disease largely reflects environmental risk exposure
Abstract
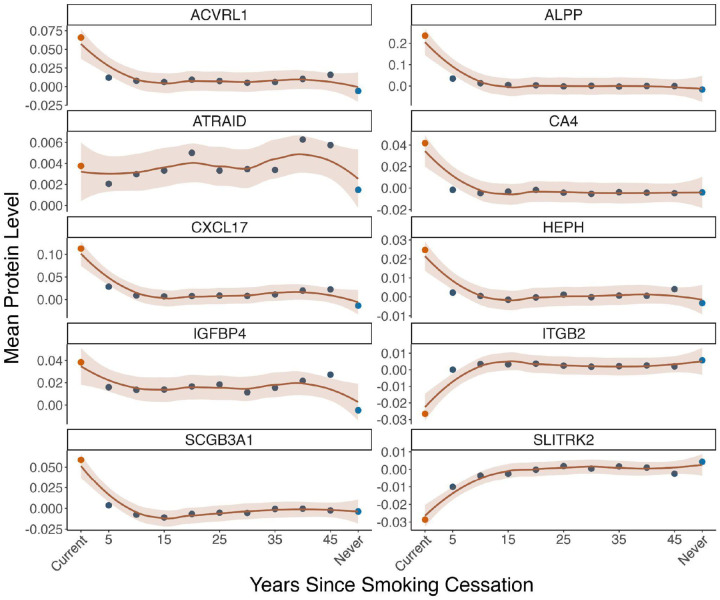
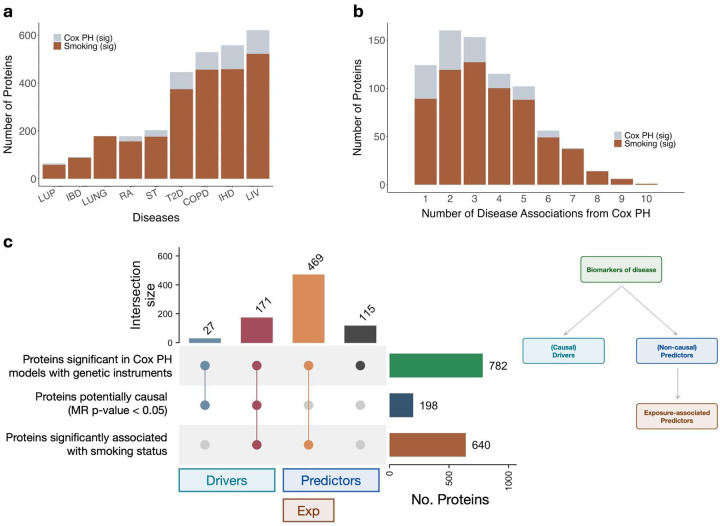
Plasma proteomic signatures accurately predict disease risk, but our understanding of the mechanisms contributing to the predictive value of the proteome remains limited. Here, we characterized proteomic biomarkers of 19 age-related diseases, based on observational associations between 2,923 protein levels and incidence of these outcomes in the UK Biobank (N = 45,438). To identify the subset of these biomarkers that may represent causal drivers of disease, we first employed Mendelian Randomization (MR) and found that only 8% of the protein-disease associations with genetic instruments showed suggestive evidence of causal relationships, and were more likely to pertain to only a single disease. We then tested the hypothesis that many proteomic biomarkers, particularly the non-causal proteins, are impacted by environmental factors that might independently affect disease risk and protein levels. We discovered that the vast majority (>90%) of proteins associated with diseases like lung cancer and COPD are also associated with smoking, and more than half of all disease-associated proteins tested in MR were associated with smoking. These proteins showed no evidence of causal effects on disease, suggesting their predictive value is as an environmental sensor. Given the sensitivity of the plasma proteome to smoking, we developed a proteomic score for smoking (SmokingPS) and demonstrated that the plasma proteome can serve as a quantitative index of smoking behavior and history. Extending this approach to alcohol intake phenotypes, our results generally suggest that many plasma proteins identified in observational associations are more likely to be readouts of environmental risk factors than disease-specific signals. We conclude that the plasma proteome may provide critical objective biomarkers for quantifying the impacts of environmental risk factors on human health and disease. Our results have significant implications for implementing predictive plasma protein biomarkers in disease prevention, and can help guide interpretation of putative protein-disease associations as actionable therapeutic targets or quantitative indications of upstream exposures that represent potential intervention points.
Figures












References
-
- Ferkingstad E. et al. Large-scale integration of the plasma proteome with genetics and disease. Nat. Genet. 53, 1712–1721 (2021). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources