

Long-read sequencing reveals the RNA isoform repertoire of neuropsychiatric risk genes in human brain
- PMID: 40988056
- PMCID: PMC12455821
- DOI: 10.1186/s13059-025-03724-1
Long-read sequencing reveals the RNA isoform repertoire of neuropsychiatric risk genes in human brain
Abstract
Background: Neuropsychiatric disorders are highly complex conditions and the risk of developing a disorder has been tied to hundreds of genomic variants that alter the expression and/or RNA isoforms made by risk genes. However, how these genes contribute to disease risk and onset through altered expression and RNA splicing is not well understood.
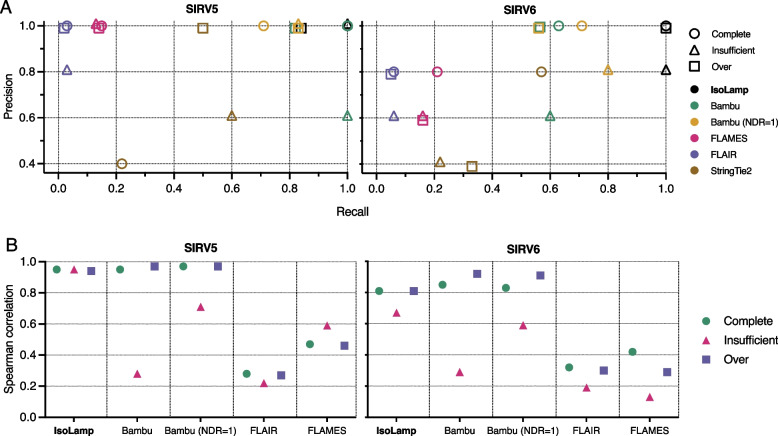
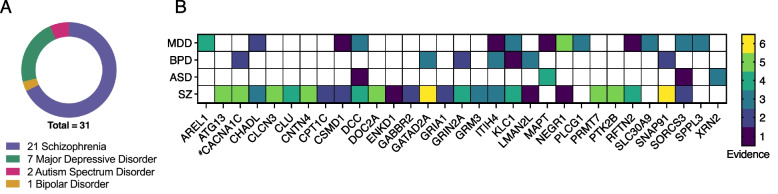
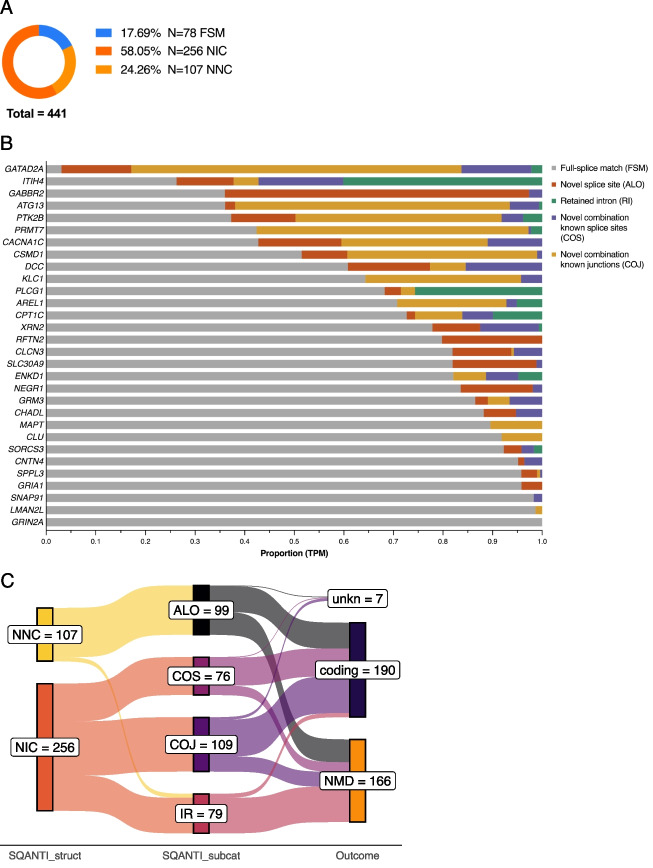
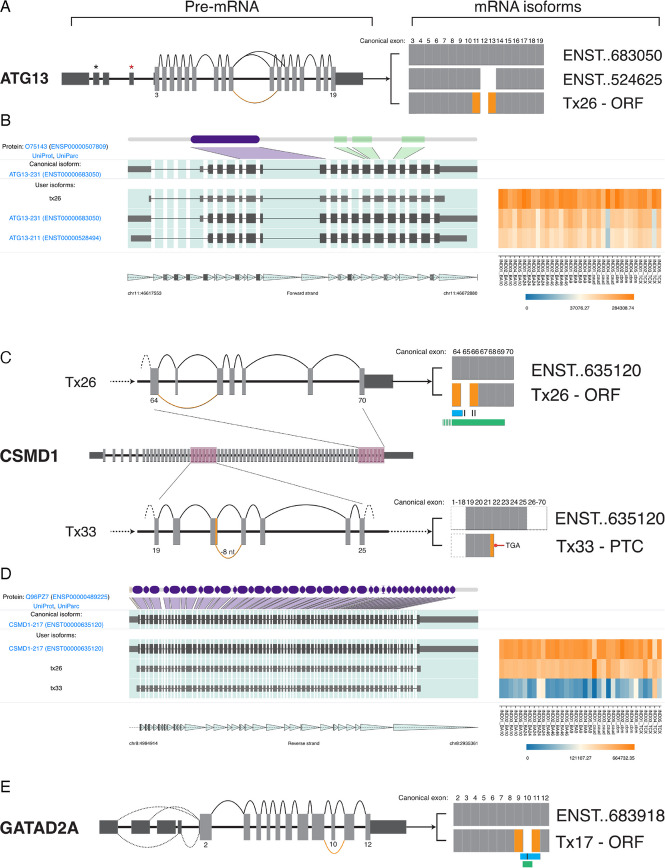
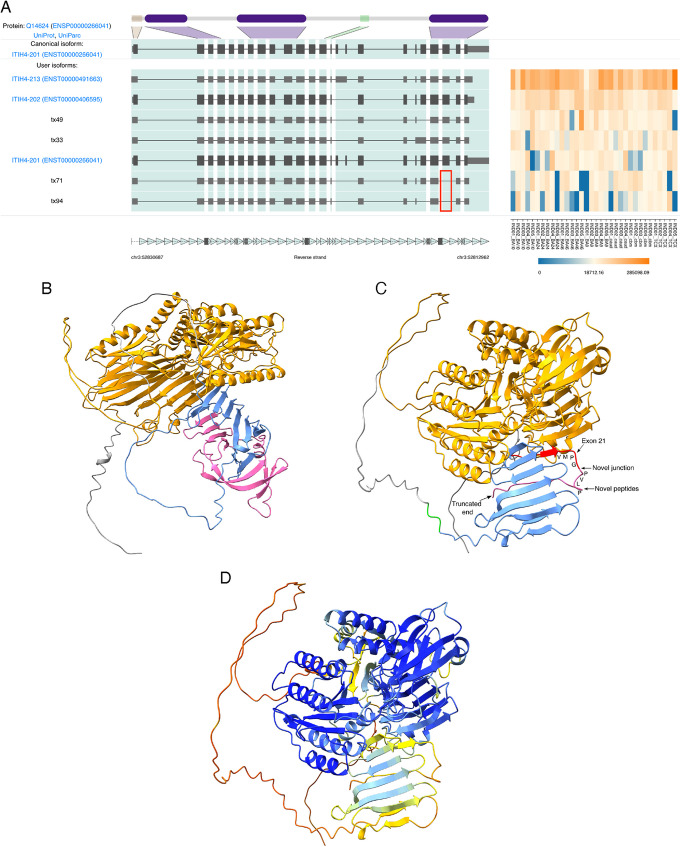
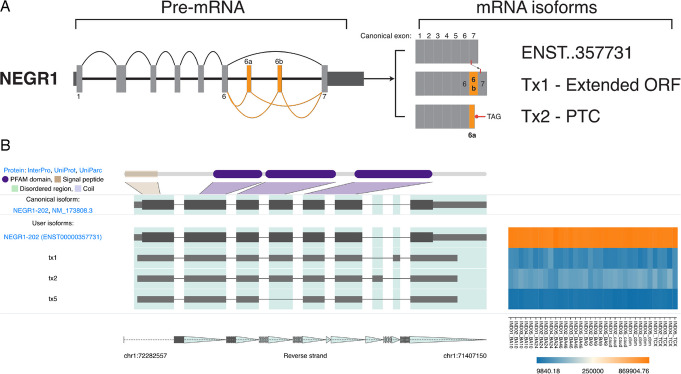
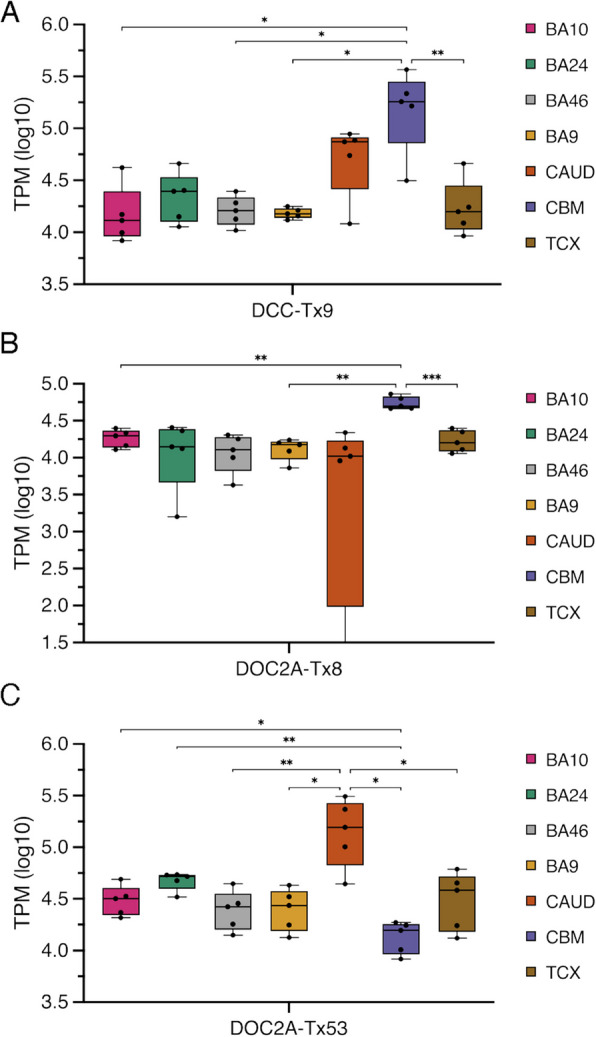
Results: Combining our new bioinformatic pipeline IsoLamp with nanopore long-read amplicon sequencing, we deeply profile the RNA isoform repertoire of 31 high-confidence neuropsychiatric disorder risk genes in Human brain. We show most risk genes are more complex than previously reported, identifying 363 novel isoforms and 28 novel exons, including isoforms which alter protein domains, and genes such as ATG13 and GATAD2A where most expression was from previously undiscovered isoforms. The greatest isoform diversity is detected in the schizophrenia risk gene ITIH4. Mass spectrometry of brain protein isolates confirms translation of a novel exon skipping event in ITIH4, suggesting a new regulatory mechanism for this gene in the brain.
Conclusions: Our results emphasize the widespread presence of previously undetected RNA and protein isoforms in the human brain and provide an effective approach to address this knowledge gap. Uncovering the isoform repertoire of candidate neuropsychiatric risk genes will underpin future analyses of the functional impact these isoforms have on neuropsychiatric disorders, enabling the translation of genomic findings into a pathophysiological understanding of disease.
Keywords: Brain; Isoform; Long-read; Nanopore; Neuropsychiatric; RNA; Splicing.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Ethics approval and consent to participate: Healthy control post-mortem human brain samples were obtained from six consented individuals collected by the Victorian Brain Bank (VBB) and the Human Research Ethics Committee of the University of Melbourne gave ethical approval for this work: #12457 and #28304. Consent for publication: The VBB obtained signed consent for whole-brain donation from either the donor or their next-of-kin in which the signed person states: “I agree that research data gathered from studies may be published providing the donor cannot be identified.” All samples mentioned in this study have been de-identified and, except VBB pathologist CM, authors were blinded to any other individual details beyond those mentioned in the methods. Competing interests: RDP, YP, YY, JG, and MBC have received financial support from Oxford Nanopore Technologies (ONT) to present their findings at scientific conferences. ONT played no role in study design, execution, analysis or publication.
Figures

References
-
- Leung SK, Jeffries AR, Castanho I, Jordan BT, Moore K, Davies JP, Dempster EL, Bray NJ, O’Neill P, Tseng E, et al. Full-length transcript sequencing of human and mouse cerebral cortex identifies widespread isoform diversity and alternative splicing. Cell Reports. 2021;37:110022. - DOI - PMC - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
